If you’ve read anything about compilers in the last two decades or so, you have almost certainly heard of SSA compilers, a popular architecture featured in many optimizing compilers, including ahead-of-time compilers such as LLVM, GCC, Go, CUDA (and various shader compilers), Swift1, and MSVC2, and just-in-time compilers such as HotSpot C23, V84, SpiderMonkey5, LuaJIT, and the Android Runtime6.
SSA is hugely popular, to the point that most compiler projects no longer bother with other IRs for optimization7. This is because SSA is incredibly nimble at the types of program analysis and transformation that compiler optimizations want to do on your code. But why? Many of my friends who don’t do compilers often say that compilers seem like opaque magical black boxes, and SSA, as it often appears in the literature, is impenetrably complex.
But it’s not! SSA is actually very simple once you forget everything you think your programs are actually doing. We will develop the concept of SSA form, a simple SSA IR, prove facts about it, and design some optimizations on it.
I have previously written about the granddaddy of all modern SSA compilers, LLVM. This article is about SSA in general, and won’t really have anything to do with LLVM. However, it may be helpful to read that article to make some of the things in this article feel more concrete.
SSA is a property of intermediate representations (IRs), primarily used by compilers for optimizing imperative code that target a register machine. Register machines are computers that feature a fixed set of registers that can be used as the operands for instructions: this includes virtually all physical processors, including CPUs, GPUs, and weird tings like DSPs.
SSA is most frequently found in compiler middle-ends, the optimizing component between the frontend (which deals with the surface language programmers write, and lowers it into the middle-end’s IR), and the backend (which takes the optimized IR and lowers it into the target platform’s assembly).
SSA IRs, however, often have little resemblance to the surface language they lower out of, or the assembly language they target. This is because neither of these representations make it easy for a compiler to intuit optimization opportunities.
Imperative code consists of a sequence of operations that mutate the executing machine’s state to produce a desired result. For example, consider the following C program:
But, how would you write a general algorithm to detect that all of the operations cancel out? You’re forced to keep in mind program order to perform the necessary dataflow analysis, following mutations of a and b through the program. But this isn’t very general, and traversing all of those paths makes the search space for large functions very big. Instead, you would like to rewrite the program such that a and b gradually get replaced with the expression that calculates the most recent value, like this:
And finally, we see that we’re returning argc - argc, and can replace it with 0. All the other variables are now unused, so we can delete them.
The reason this works so well is because we took a function with mutation, and converted it into a combinatorial circuit, a type of digital logic circuit that has no state, and which is very easy to analyze. The dependencies between nodes in the circuit (corresponding to primitive operations such as addition or multiplication) are obvious from its structure. For example, consider the following circuit diagram for a one-bit multiplier:
A binary multiplier (Wikipedia)
This graph representation of an operation program has two huge benefits:
The powerful tools of graph theory can be used to algorithmically analyze the program and discover useful properties, such as operations that are independent of each other or whose results are never used.
The operations are not ordered with respect to each other except when there is a dependency; this is useful for reordering operations, something compilers really like to do.
The reason combinatorial circuits are the best circuits is because they are directed acyclic graphs (DAGs) which admit really nice algorithms. For example, longest path in a graph is NP-hard (and because P=NP8, has complexity O(2n)). However, if the graph is a DAG, it admits an O(n) solution!
To understand this benefit, consider another program:
Suppose we wanted to replace each variable with its definition like we did before. We can’t just replace each constant variable with the expression that defines it though, because we would wind up with a different program!
intf(intx){inty=x*2;x*=y;// const int z = y; // Replace z with its definition.y*=y;returnx+y;}
Now, we pick up an extra y term because the squaring operation is no longer unused! We can put this into circuit form, but it requires inserting new variables for every mutation.
But we can’t do this when complex control flow is involved! So all of our algorithms need to carefully account for mutations and program order, meaning that we don’t get to use the nice graph algorithms without careful modification.
SSA stands for “static single assignment”, and was developed in the 80s as a way to enhance the existing three-argument code (where every statement is in the form x = y op z) so that every program was circuit-like, using a very similar procedure to the one described above.
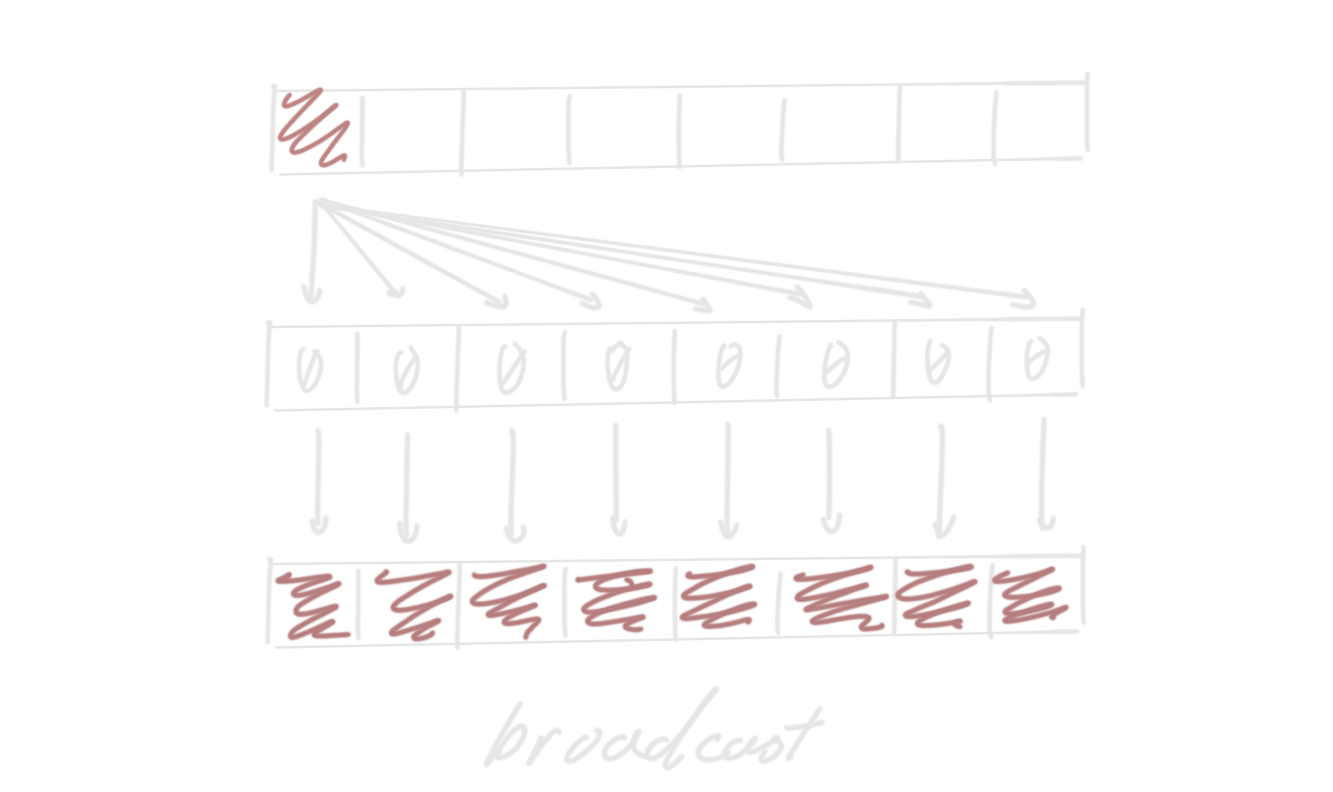
The SSA invariant states that every variable in the program is assigned to by precisely one operation. If every operation in the program is visited once, they form a combinatorial circuit. Transformations are required to respect this invariant. In circuit form, a program is a graph where operations are nodes, and “registers” (which is what variables are usually called in SSA) are edges (specifically, each output of an operation corresponds to a register).
But, again, control flow. We can’t hope to circuitize a loop, right? The key observation of SSA is that most parts of a program are circuit-like. A basic block is a maximal circuital component of a program. Simply put, it is a sequence of non-control flow operations, and a final terminator operation that transfers control to another basic block.
The basic blocks themselves form a graph, the control flow graph, or CFG. This formulation of SSA is sometimes called SSA-CFG9. This graph is not a DAG in general; however, separating the program into basic blocks conveniently factors out the “non-DAG” parts of the program, allowing for simpler analysis within basic blocks.
There are two equivalent formalisms for SSA-CFG. The traditional one uses special “phi” operations (often called phi nodes, which is what I will call them here) to link registers across basic blocks. This is the formalism LLVM uses. A more modern approach, used by MLIR, is block arguments: each basic block specifies parameters, like a function, and blocks transferring control flow to it must pass arguments of those types to it.
How might we express this in an SSA-CFG IR? Let’s start inventing our SSA IR! It will look a little bit like LLVM IR, since that’s what I’m used to looking at.
// Globals (including functions) start with $, registers with %.// Each function declares a signature.funcfib(%n:i32)->(i32){// The first block has no label and can't be "jumped to".//// Single-argument goto jumps directly into a block with// the given arguments.goto@loop.start(%n,0,1)// Block labels start with a `!`, can contain dots, and// define parameters. Register names are scoped to a block.@loop.start(%n,%a,%b:i32):// Integer comparison: %n > 0.%cont=cmp.gt%n,0// Multi-argument goto is a switch statement. The compiler// may assume that `%cont` is among the cases listed in the// goto.goto%cont{0->@ret(%a),// Goto can jump to the function exit.1->@loop.body(%n,%a,%b),}@loop.body(%n,%a,%b:i32):// Addition and subtraction.%c=add%a,%b%n.2=sub%n,1// Note the assignments in @loop.start:// %n = %n.2, %a = %b, %b = %c.goto@loop.start(%n.2,%b,%c)}
Every block ends in a goto, which transfers control to one of several possible blocks. In the process, it calls that block with the given arguments. One can think of a basic block as a tiny function which tails10 into other basic blocks in the same function.
LLVM IR is… older, so it uses the older formalism of phi nodes. “Phi” comes from “phony”, because it is an operation that doesn’t do anything; it just links registers from predecessors.
A phi operation is essentially a switch-case on the predecessors, each case selecting a register from that predecessor (or an immediate). For example, @loop.start has two predecessors, the implicit entry block @entry, and @loop.body. In a phi node IR, instead of taking a block argument for %n, it would specify
The value of the phi operation is the value from whichever block jumped to this one.
This can be awkward to type out by hand and read, but is a more convenient representation for describing algorithms (just “add a phi node” instead of “add a parameter and a corresponding argument”) and for the in-memory representation, but is otherwise completely equivalent.
It’s a bit easier to understand the transformation from C to our IR if we first rewrite the C to use goto instead of a for loop:
However, we still have mutation in the picture, so this isn’t SSA. To get into SSA, we need to replace every assignment with a new register, and somehow insert block arguments…
The above IR code is already partially optimized; the named variables in the C program have been lifted out of memory and into registers. If we represent each named variable in our C program with a pointer, we can avoid needing to put the program into SSA form immediately. This technique is used by frontends that lower into LLVM, like Clang.
We’ll enhance our IR by adding a stack declaration for functions, which defines scratch space on the stack for the function to use. Each stack slot produces a pointer that we can load from and store to.
Our Fibonacci function would now look like so:
func&fib(%n:i32)->(i32){// Declare stack slots.%np=stacki32%ap=stacki32%bp=stacki32// Load initial values into them.store%np,%nstore%ap,0store%bp,1// Start the loop.goto@loop.start(%np,%ap,%bp)@loop.start(%np,%ap,%bp:ptr):%n=load%np%cont=cmp.gt%n,0goto%cont{0->@exit(%ap)1->@loop.body(%n,%a,%b),}@loop.body(%np,%ap,%bp:ptr):%a=load%ap%b=load%bp%c=add%a,%bstore%ap,%bstore%bp,%c%n=load%np%n.2=sub%n,1store%np,%n.2goto@loop.start(%np,%ap,%bp)@exit(%ap:ptr):%a=load%apgoto@ret(%ap)}
Any time we reference a named variable, we load from its stack slot, and any time we assign it, we store to that slot. This is very easy to get into from C, but the code sucks because it’s doing lots of unnecessary pointer operations. How do we get from this to the register-only function I showed earlier?
We want program order to not matter for the purposes of reordering, but as we’ve written code here, program order does matter: loads depend on prior stores but stores don’t produce a value that can be used to link the two operations.
We can restore not having program order by introducing operands representing an “address space”; loads and stores take an address space as an argument, and stores return a new address space. An address space, or mem, represents the state of some region of memory. Loads and stores are independent when they are not connected by a mem argument.
This type of enhancement is used by Go’s SSA IR, for example. However, it adds a layer of complexity to the examples, so instead I will hand-wave this away.
The predecessors (or “preds”) of a basic block is the set of blocks with an outgoing edge to that block. A block may be its own predecessors.
Some literature calls the above “direct” or immediate predecessors. For example, the preds of in our example are @loop.start are @entry (the special name for the function entry-point) @loop.body.
The successors (no, not “succs”) of a basic block is the set of blocks with an outgoing edge from that block. A block may be its own successors.
The sucessors of @loop.start are @exit and @loop.body. The successors are listed in the loop’s goto.
If a block @a is a transitive pred of a block @b, we say that @aweakly dominates@b, or that it is a weak dominator of @b. For example, @entry, @loop.start and @loop.body both weakly dominate @exit.
However, this is not usually an especially useful relationship. Instead, we want to speak of dominators:
We only consider CFGs which are flowgraphs, that is, all blocks are reachable from the root block @entry, which has no preds. This is necessary to eliminate some pathological graphs from our proofs. Importantly, we can always ask for an acyclic path11 from @entry to any block @b.
An equivalent way to state the dominance relationship is that from every path from @entry to @b contains all of @b’s dominators.
First, assume every @entry to @b path contains @a. If @b is @a, we’re done. Otherwise we need to prove each predecessor of @b is dominated by @a; we do this by induction on the length of acyclic paths from @entry to @b. Consider preds @p of @b that are not @a, and consider all acyclic paths p from @entry to @p; by appending @b to them, we have an acyclic path p′ from @entry to @b, which must contain @a. Because both the last and second-to-last elements of this are not @a, it must be within the shorter path p which is shorter than p′. Thus, by induction, @a dominates @p and therefore @b
Going the other way, if @a dominates @b, and consider a path p from @entry to @b. The second-to-last element of p is a pred @p of @b; if it is @a we are done. Otherwise, we can consider the path p made by deleting @b at the end. @p is dominated by @a, and p′ is shorter than p, so we can proceed by induction as above.
Onto those nice properties. Dominance allows us to take an arbitrarily complicated CFG and extract from it a DAG, composed of blocks ordered by dominance.
Dominance is reflexive and transitive by definition, so we only need to show blocks can’t dominate each other.
Suppose distinct @a and @b dominate each other.Pick an acyclic pathp from @entry to @a. Because @b dominates @a, there is a prefix p′ of this path ending in @b. But because @a dominates @b, some prefix p′′ of p′ ends in @a. But now p must contain @a twice, contradicting that it is acyclic.
This allows us to write @a < @b when @a dominates @b. There is an even more refined graph structure that we can build out of dominators, which follows immediately from the partial order theorem.
Suppose @a1 < @b and @a2 < @b, but neither dominates the other. Then, there must exist acyclic paths from @entry to @b which contain both, but in different orders. Take the subpaths of those paths which follow @entry ... @a1, and @a1 ... @b, neither of which contains @a2. Concatenating these paths yields a path from @entry to @b that does not contain @a2, a contradiction.
This tells us that the DAG we get from the dominance relation is actually a tree, rooted at @entry. The parent of a node in this tree is called its immediate dominator.
Computing dominators can be done iteratively: the dominator set of a block @b is the intersection the dominator sets of its preds, plus @b. This algorithm runs in quadratic time.
A better algorithm is the Lengauer-Tarjan algorithm[^lta]. It is relatively simple, but explaining how to implement it is a bit out of scope for this article. I found a nice treatment of it here.
What’s important is we can compute the dominator tree without breaking the bank, and given any node, we can ask for its immediate dominator. Using immediate dominators, we can introduce the final, important property of dominators.
The dominance frontier of a block @a is the set of all blocks not dominated by @a with at least one pred which @a dominates.
These are points where control flow merges from distinct paths: one containing @a and one not. The dominance frontier of @loop.body is @loop.start, whose preds are @entry and @loop.body.
There are many ways to calculate dominance frontiers, but with a dominance tree in hand, we can do it like this:
For each block @b with more than one pred, for each of its preds, let @p be that pred. Add @b to the dominance frontier of @p and all of its dominators, stopping when encountering @b’ immediate dominator.
We need to prove that every block examined by the algorithm winds up in the correct frontiers.
First, we check that every examined block @b is added to the correct frontier. If @a < @p, where @p is a pred of @b, and a @d is @b’s immediate dominator, then if @a < @d, @b is not in its frontier, because @a must dominate @b. Otherwise, @b must be in @a’s frontier, because @a dominates a pred but it cannot dominate @b, because then it would be dominated by @i, a contradiction.
Second, we check that every frontier is complete. Consider a block @a. If an examined block @b is in its frontier, then @a must be among the dominators of some pred @p, and it must be dominated by @b’s immediate dominator; otherwise, @a would dominate @b (and thus @b would not be in its frontier). Thus, @b gets added to @a’s dominator.
You might notice that all of these algorithms are quadratic. This is actually a very good time complexity for a compilers-related graph algorithm. Cubic and quartic algorithms are not especially uncommon, and yes, your optimizing compiler’s time complexity is probably cubic or quartic in the size of the program!
Ok. Let’s construct an optimization. We want to figure out if we can replace a load from a pointer with the most recent store to that pointer. This will allow us to fully lift values out of memory by cancelling out store/load pairs.
This will make use of yet another implicit graph data structure.
The dataflow graph is the directed graph made up of the internal circuit graphs of each each basic block, connected along block arguments.
To follow a use-def chain is to walk this graph forward from an operation to discover operations that potentially depend on it, or backwards to find operations it potentially depends on.
It’s important to remember that the dataflow graph, like the CFG, does not have a well defined “up” direction. Navigating it and the CFG requires the dominator tree.
One other important thing to remember here is that every instruction in a basic block always executes if the block executes. In much of this analysis, we need to appeal to “program order” to select the last load in a block, but we are always able to do so. This is an important property of basic blocks that makes them essential for constructing optimizations.
For a given store %p, %v, we want to identify all loads that depend on it. We can follow the use-def chain of %p to find which blocks contain loads that potentially depend on the store (call it %s).
First, we can eliminate loads within the same basic block (call it @a). Replace all load %p instructions after s (but before any other store %p, _s, in program order) with %v’s def. If s is not the last store in this block, we’re done.
Otherwise, follow the use-def chain of %p to successors which use %p, i.e., successors whose goto case has %p as at least one argument. Recurse into those successors, and now replacing the pointer %p of interest with the parameters of the successor which were set to %p (more than one argument may be %p).
If successor @b loads from one of the registers holding %p, replace all such loads before a store to %p. We also now need to send %v into @b somehow.
This is where we run into something of a wrinkle. If @b has exactly one predecessor, we need to add a new block argument to pass whichever register is holding %v (which exists by induction). If %v is already passed into @b by another argument, we can use that one.
However, if @b has multiple predecessors, we need to make sure that every path from @a to @b sends %v, and canonicalizing those will be tricky. Worse still, if @b is in @a’s domination frontier, a different store could be contributing to that load! For this reason, dataflow from stores to loads is not a great strategy.
Instead, we’ll look at dataflow from loads backwards to stores (in general, dataflow from uses to defs tends to be more useful), which we can use to augment the above forward dataflow analysis to remove the complex issues around domination frontiers.
Let’s analyze loads instead. For each load %p in @a, we want to determine all stores that could potentially contribute to its value. We can find those stores as follows:
We want to be able to determine which register in a given block corresponds to the value of %p, and then find its last store in that block.
To do this, we’ll flood-fill the CFG backwards in BFS order. This means that we’ll follow preds (through the use-def chain) recursively, visiting each pred before visiting their preds, and never revisiting a basic block (except we may need to come back to @a at the end).
Determining the “equivalent”12 of %p in @b (we’ll call it %p.b) can be done recursively: while examining @b, follow the def of %p.b. If %p.b is a block parameter, for each pred @c, set %p.c to the corresponding argument in the @b(...) case in @c’s goto.
Using this information, we can collect all stores that the load potentially depends on. If a predecessor @b stores to %p.b, we add the last such store in @b (in program order) to our set of stores, and do not recurse to @b’s preds (because this store overwrites all past stores). Note that we may revisit @a in this process, and collect a store to %p from it occurs in the block. This is necessary in the case of loops.
The result is a set stores of (store %p.s %v.s, @s) pairs. In the process, we also collected a set of all blocks visited, subgraph, which are dominators of @a which we need to plumb a %v.b through. This process is called memory dependency analysis, and is a key component of many optimizations.
Not all contributing operations are stores. Some may be references to globals (which we’re disregarding), or function arguments or the results of a function call (which means we probably can’t lift this load). For example %p gets traced all the way back to a function argument, there is a code path which loads from a pointer whose stores we can’t see.
It may also trace back to a stack slot that is potentially not stored to. This means there is a code path that can potentially load uninitialized memory. Like LLVM, we can assume this is not observable behavior, so we can discount such dependencies. If all of the dependencies are uninitialized loads, we can potentially delete not just the load, but operations which depend on it (reverse dataflow analysis is the origin of so-called “time-traveling” UB).
Now that we have the full set of dependency information, we can start lifting loads. Loads can be safely lifted when all of their dependencies are stores in the current function, or dependencies we can disregard thanks to UB in the surface language (such as null loads or uninitialized loads).
There is a lot of fuss in this algorithm about plumbing values through block arguments. A lot of IRs make a simplifying change, where every block implicitly receives the registers from its dominators as block arguments.
I am keeping the fuss because it makes it clearer what’s going on, but in practice, most of this plumbing, except at dominance frontiers, would be happening in the background.
Suppose we can safely lift some load. Now we need to plumb the stored values down to the load. For each block @b in subgraph (all other blocks will now be in subgraph unless stated otherwise). We will be building two mappings: one (@s, @b) -> %v.s.b, which is the register equivalent to %v.s in that block. We will also be building a map @b -> %v.b, which is the value that %p must have in that block.
Prepare a work queue, with each @s in it initially.
Pop a block @a form the queue. For each successor @b (in subgraph):
If %v.b isn’t already defined, add it as a block argument. Have @a pass %v.a to that argument.
If @b hasn’t been visited yet, and isn’t the block containing the load we’re deleting, add it to the queue.
Once we’re done, if @a is the block that contains the load, we can now replace all loads to %p before any stores to %p with %v.a.
There are cases where this whole process can be skipped, by applying a “peephole” optimization. For example, stores followed by loads within the same basic block can be optimized away locally, leaving the heavy-weight analysis for cross-block store/load pairs.
Let’s look at L1. Is contributing loads are in @entry and @loop.body. So we add a new parameter %n: in @entry, we call that parameter with %n (since that’s stored to it in @entry), while in @loop.body, we pass %n.2.
What about L4? The contributing loads are also in @entry and @loop.body, but one of those isn’t a pred of @exit. @loop.start is also in the subgraph for this load, though. So, starting from @entry, we add a new parameter %a to @loop.body and feed 0 (the stored value, an immediate this time) through it. Now looking at @loop.body, we see there is already a parameter for this load (%a), so we just pass %b as that argument. Now we process @loop.start, which @entry pushed onto the queue. @exit gets a new parameter %a, which is fed @loop.start’s own %a. We do not re-process @loop.body, even though it also appears in @loop.start’s gotos, because we already visited it.
After doing this for the other two loads, we get this:
After lifting, if we know that a stack slot’s pointer does not escape (i.e., none of its uses wind up going into a function call13) or a write to a global (or a pointer that escapes), we can delete every store to that pointer. If we delete every store to a stack slot, we can delete the stack slot altogether (there should be no loads left for that stack slot at this point).
This analysis is simple, because it assumes pointers do not alias in general. Alias analysis is necessary for more accurate dependency analysis. This is necessary, for example, for lifting loads of fields of structs through subobject pointers, and dealing with pointer arithmetic in general.
However, our dependency analysis is robust to passing different pointers as arguments to the same block from different predecessors. This is the case that is specifically handled by all of the fussing about with dominance frontiers. This robustness ultimately comes from SSA’s circuital nature.
Similarly, this analysis needs to be tweaked to deal with something like select %cond, %a, %b (a ternary, essentially). selects of pointers need to be replaced with selects of the loaded values, which means we need to do the lifting transformation “all at once”: lifting some liftable loads will leave the IR in an inconsistent state, until all of them have been lifted.
Many optimizations will make a mess of the CFG, so it’s useful to have simple passes that “clean up” the mess left by transformations. Here’s some easy examples.
If an operation’s result has zero uses, and the operation has no side-effects, it can be deleted. This allows us to then delete operations that it depended on that now have no side effects. Doing this is very simple, due to the circuital nature of SSA: collect all instructions whose outputs have zero uses, and delete them. Then, examine the defs of their operands; if those operations now have no uses, delete them, and recurse.
This bubbles up all the way to block arguments. Deleting block arguments is a bit trickier, but we can use a work queue to do it. Put all of the blocks into a work queue.
Pop a block from the queue.
Run unused result elimination on its operations.
If it now has parameters with no uses, remove those parameters.
For each pred, delete the corresponding arguments to this block. Then, Place those preds into the work queue (since some of their operations may have lost their last use).
There are many CFG configurations that are redundant and can be simplified to reduce the number of basic blocks.
For example, unreachable code can help delete blocks. Other optimizations may cause the goto at the end of a function to be empty (because all of its successors were optimized away). We treat an empty goto as being unreachable (since it has no cases!), so we can delete every operation in the block up to the last non-pure operation. If we delete every instruction in the block, we can delete the block entirely, and delete it from its preds’ gotos. This is a form of dead code elimination, or DCE, which combines with the previous optimization to aggressively delete redundant code.
Some jumps are redundant. For example, if a block has exactly one pred and one successor, the pred’s goto case for that block can be wired directly to the successor. Similarly, if two blocks are each other’s unique predecessor/successor, they can be fused, creating a single block by connecting the input blocks’ circuits directly, instead of through a goto.
If we have a ternary select operation, we can do more sophisticated fusion. If a block has two successors, both of which the same unique successor, and those successors consist only of gotos, we can fuse all four blocks, replacing the CFG diamond with a select. In terms of C, this is this transformation:
I am hoping to write more about SSA optimization passes. This is a very rich subject, and viewing optimizations in isolation is a great way to understand how a sophisticated optimization pipeline is built out of simple, dumb components.
It’s also a practical application of graph theory that shows just how powerful it can be, and (at least in my opinion), is an intuitive setting for understanding graph theory, which can feel very abstract otherwise.
In the future, I’d like to cover CSE/GVN, loop optimizations, and, if I’m feeling brave, getting out of SSA into a finite-register machine (backends are not my strong suit!).
Specifically the Swift frontend before lowering into LLVM IR. ↩
Microsoft Visual C++, a non-conforming C++ compiler sold by Microsoft ↩
HotSpot is the JVM implementation provided by OpenJDK; C2 is the “second compiler”, which has the best performance among HotSpot’s Java execution engines. ↩
The Android Runtime (ART) is the “JVM” (scare quotes) on the Android platform. ↩
The Glasgow Haskell Compiler (GHC), does not use SSA; it (like some other pure-functional languages) uses a continuation-oriented IR (compare to Scheme’s call/cc). ↩
Every compiler person firmly believes that P=NP, because program optimization is full of NP-hard problems and we would have definitely found polynomial ideal register allocation by now if it existed. ↩
Some more recent IRs use a different version of SSA called “structured control flow”, or SCF. Wasm is a notable example of an SCF IR. SSA-SCF is equivalent to SSA-CFG, and polynomial time algorithms exist for losslessly converting between them (LLVM compiling Wasm, for example, converts its CFG into SCF using a “relooping algorithm”).
In SCF, operations like switch statements and loops are represented as macro operations that contain basic blocks. For example, a switch operation might take a value as input, select a basic block to execute based on that, and return the value that basic block evaluates to as its output.
RVSDG is a notable innovation in this space, because it allows circuit analysis of entire imperative programs.
I am convering SSA-CFG instead of SSA-SCF simply because it’s more common, and because it’s what LLVM IR is.
Tail calling is when a function call is the last operation in a function; this allows the caller to jump directly to the callee, recycling its own stack frame for it instead of requiring it to allocate its own. ↩
Given any path from @a to @b, we can make it acyclic by replacing each subpath from @c to @c with a single @c node. ↩
When moving from a basic block to a pred, a register in that block which is defined as a block parameter corresponds to some register (or immediate) in each predecessor. That is the “equivalent” of %p.
One possible option for the “equivalent” is an immediate: for example, null or the address of a global. In the case of a global &g, assuming no data races, we would instead need alias information to tell if stores to this global within the current function (a) exist and (b) are liftable at all.
If the equivalent is null, we can proceed in one of two ways depending on optimization level. If we want loads of null to trap (as in Go), we need to mark this load as not being liftable, because it may trap. If we want loads of null to be UB, we simply ignore that pred, because we can assume (for our analysis) that if the pointer is null, it is never loaded from. ↩
Returned stack pointers do not escape: stack slots’ lifetimes end at function exit, so we return a dangling pointer, which we assume are never loaded. So stores to that pointer before returning it can be discarded. ↩
Go’s interfaces are very funny. Rather than being explicitly implemented, like in Java or Rust, they are simply a collection of methods (a “method set”) that the concrete type must happen to have. This is called structural typing, which is the opposite of nominal typing.
Go interfaces are very cute, but this conceptual simplicity leads to a lot of implementation problems (a theme with Go, honestly). It removes a lot of intentionality from implementing interfaces, and there is no canonical way to document that A satisfies1B, nor can you avoid conforming to interfaces, especially if one forces a particular method on you.
It also has very quirky results for the language runtime. To cast an interface value to another interface type (via the type assertion syntax a.(B)), the runtime essentially has to use reflection to go through the method set of the concrete type of a. I go into detail on how this is implemented here.
Because of their structural nature, this also means that you can’t add new methods to an interface without breaking existing code, because there is no way to attach default implementations to interface methods. This results in very silly APIs because someone screwed up an interface.
For example, in the standard library’s package flag, the interface flag.Value represents a value which can be parsed as a CLI flag. It looks like this:
typeValueinterface{// Get a string representation of the value.String()string// Parse a value from a string, possibly returning an error.Set(string)error}
flag.Value also has an optional method, which is only specified in the documentation. If the concrete type happens to provide IsBoolFlag() bool, it will be queries for determining if the flag should have bool-like behavior. Essentially, this means that something like this exists in the flag library:
The flag package already uses reflection, but you can see how it might be a problem if this interface-to-interface cast happens regularly, even taking into account Go’s caching of cast results.
There is also flag.Getter, which exists because they messed up and didn’t provide a way for a flag.Value to unwrap into the value it contains. For example, if a flag is defined with flag.Int, and then that flag is looked up with flag.Lookup, there’s no straightforward way to get the int out of the returned flag.Value.
Instead, you have to side-cast to flag.Getter:
typeGetterinterface{Value// Returns the value of the flag.Get()any}
As a result, flag.Lookup("...").(flag.Getter) needs to do a lot more work than if flag.Value had just added Get() any, with a default return value of nil.
It turns out that there is a rather elegant workaround for this.
The A-typed embedded field behaves as if we had declared the field A A, but selectors on var b B will search in A if they do not match something on the B level. For example, if A has a method Bar, and B does not, b.Bar() will resolve to b.A.Bar(). However, if A has a method Foo, b.Foo resolves to b.Foo, not b.A.Foo, because b has a field Foo.
Importantly, any methods from A which B does not already have will be added to B’s method set. So this works:
type(AintBstruct{A}Cinterface{Foo()Bar()})func(A)Foo(){}func(B)Bar(){}var_C=B{}// B satisfies C.
Now, suppose that we were trying to add Get() any to flag.Value. Let’s suppose that we had also defined flag.ValueDefaults, a type that all satisfiers of flag.Value must embed. Then, we can write the following:
typeValueinterface{String()stringSet(string)errorGet()any// New method.}typeValueDefaultsstruct{}func(ValueDefaults)Get(){returnnil}
Now, this only works if we had required in the first place that anyone satisfying flag.Value embeds flag.ValueDefaults. How can we force that?
A little-known Go feature is that interfaces can have unexported methods. The way these work, for the purposes of interface conformance, is that exported methods are matched just by their name, but unexported methods must match both name and package.
So, if we have an interface like interface { foo() }, then foo will only match methods defined in the same package that this interface expression appears. This is useful for preventing satisfaction of interfaces.
However, there is a loophole: embedding inherits the entire method set, including unexported methods. Therefore, we can enhance Value to account for this:
typeValueinterface{String()stringSet(string)errorGet()any// New method.value()// Unexported!}typeValueDefaultsstruct{}func(ValueDefaults)Get(){returnnil}func(ValueDefaults)value(){}
Now, it’s impossible for any type defined outside of this package to satisfy flag.Value, without embedding flag.ValueDefaults (either directly or through another embedded flag.Value).
Now, another problem is that you can’t control the name of embedded fields. If the embedded type is Foo, the field’s name is Foo. Except, it’s not based on the name of the type itself; it will pick up the name of a type alias. So, if you want to unexport the defaults struct, you can simply write:
This also has the side-effect of hiding all of ValueDefaults’ methods from MyValue’s documentation, despite the fact that exported and fields methods are still selectable and callable by other packages (including via interfaces). As far as I can tell, this is simply a bug in godoc, since this behavior is not documented.
There is still a failure mode: if a user type satisfying flag.Value happened to define a Get method with a different interface. In this case, that Get takes precedence, and changes to flag.Value will break users.
There are two workarounds:
Tell people not to define methods on their satisfying type, and if they do, they’re screwed. Because satisfying flag.Value is now explicit, this is not too difficult to ask for.
Pick a name for new methods that is unlikely to collide with anything.
Unfortunately, this runs into a big issue with structural typing, which is that it is very difficult to avoid making mistakes when making changes, due to the lack of intent involved. A similar problem occurs with C++ templates, where the interfaces defined by concepts are implicit, and can result in violating contract expectations.
Go has historically be relatively cavalier about this kind of issue, so I think that breaking people based on this is fine.
And of course, you cannot retrofit a default struct into a interface; you have to define it from day one.
Now IsBoolFlag is more than just a random throw-away comment on a type.
We can also use defaults to speed up side casts. Many functions around the io package will cast an io.Reader into an io.Seeker or io.ReadAt to perform more efficient I/O.
In a hypothetical world where we had defaults structs for all the io interfaces, we can enhance io.Reader with a ReadAt default method that by default returns an error.
We can do something similar for io.Seeker, but because it’s a rather general interface, it’s better to keep io.Seeker as-is. So, we can add a conversion method:
Here, Reader.Seeker() converts to an io.Seeker, returning nil if that’s not possible. How is this faster than r.(io.Seeker)? Well, consider what this would look like in user code:
Now, we might consider looking past that, but it becomes a big problem with reflection. If we passed Foo(x) into reflect.ValueOf, the resulting any conversion would discard the defaulted method, meaning that it would not be findable by reflect.Value.MethodByName(). Oops.
So we need to somehow add Baz to MyFoo’s method set. Maybe we say that if MyFoo is ever converted into Foo, it gets the method. But this doesn’t work, because the compiler might not be able to see through something like any(MyFoo{...}).(Foo). This means that Baz must be applied unconditionally. But, now we have the problem that if we have another interface interface { Bar(); Baz(int) }, MyFoo would need to receive incompatible signatures for Baz.
Again, we’re screwed by the non-intentionality of structural typing.
Ok, let’s forget about default method implementations, that doesn’t seem to be workable. What if we make some methods optional, like IsBoolFlag() earlier? Let’s invent some syntax for it.
Then, suppose that MyFoo provides Bar but not Baz (or Baz with the wrong signature). Then, the entry in the itab for Baz would contain a nil function pointer, such that x.Baz() panics! To determine if Baz is safe to call, we would use the following idiom:
The compiler is already smart enough to elide construction of funcvals for cases like this, although it does mean that x.Func in general, for an interface value x, requires an extra cmov or similar to make sure that x.Func is nil when it’s a missing method.
All of the use cases described above would work Just Fine using this construction, though! However, we run into the same issue that Foo(x) appears to have a larger method set than x. It is not clear if Foo(x) should conform to interface { Bar(); Baz() }, where Baz is required. My intuition would be no: Foo is a strictly weaker interface. Perhaps it might be necessary to avoid the method access syntax for optional methods, but that’s a question of aesthetics.
This idea of having nulls in place of function pointers in a vtable is not new, but to my knowledge is not used especially widely. It would be very useful in C++, for example, to be able to determine if no implementation was provided for a non-pure virtual function. However, the nominal nature of C++’s virtual functions does not make this as big of a need.
Another alternative is to store a related interfaces’ itabs on in an itab. For example, suppose that we invent the syntax A<- within an interface{} to indicate that that interface will likely get cast to A. For example:
Satisfying B does not require satisfying A. However, the A<- must be part of public API, because a interface{ Bar() } cannot be used in place of an interface{ A<- }
Within B’s itab, after all of the methods, there is a pointer to an itab for A, if the concrete type for this itab also happens to satisfy A. Then, a cast from B to A is just loading a pointer from the itab. If the cast would fail, the loaded pointer will be nil.
I had always assumed that Go did an optimization like this for embedding interfaces, but no! Any inter-interface conversion, including upcasts, goes through the whole type assertion machinery! Of course, Go cannot hope to generate an itab for every possible subset of the method set of an interface (exponential blow-up), but it’s surprising that they don’t do this for embedded interfaces, which are Go’s equivalent of superinterfaces (present in basically every language with interfaces).
Using this feature, we can update flag.Value to look like this:
Unfortunately, because A<- changes the ABI of an interface, it does not seem possible to actually add this to existing interfaces, because the following code is valid:
Even though this fix seems really clean, it doesn’t work! The only way it could work is if PGO determines that a particular interface conversion A to B happens a lot, and updates the ABI of all interfaces with the method set of A, program-globally, to contain a pointer to a B itab if available.
Go’s interfaces are pretty bad; in my opinion, a feature that looks good on a slide, but which results in a lot of mess due to its granular and intention-less nature. We can sort of patch over it with embeds, but there’s still problems.
Due to how method sets work in Go, it’s very hard to “add” methods through an interface, and honestly at this point, any interface mechanism that makes it impossible (or expensive) to add new functions is going to be a huge problem.
Missing methods seems like the best way out of this problem, but for now, we can stick to the janky embedded structs.
Go uses the term “implements” to say that a type satisfies an interface. I am instead intentionally using the term “satisfies”, because it makes the structural, passive nature of implementing an interface clearer. This is also more in-line with interfaces’ use as generic constraints.
Swift uses the term “conform” instead, which I am avoiding for this reason. ↩
Historically I have worked on many projects related to high-performance Protobuf, be that on the C++ runtime, on the Rust runtime, or on integrating UPB, the fastest Protobuf runtime, written by my colleague Josh Haberman. I generally don’t post directly about my current job, but my most recent toy-turned-product is something I’m very excited to write about: hyperpb.
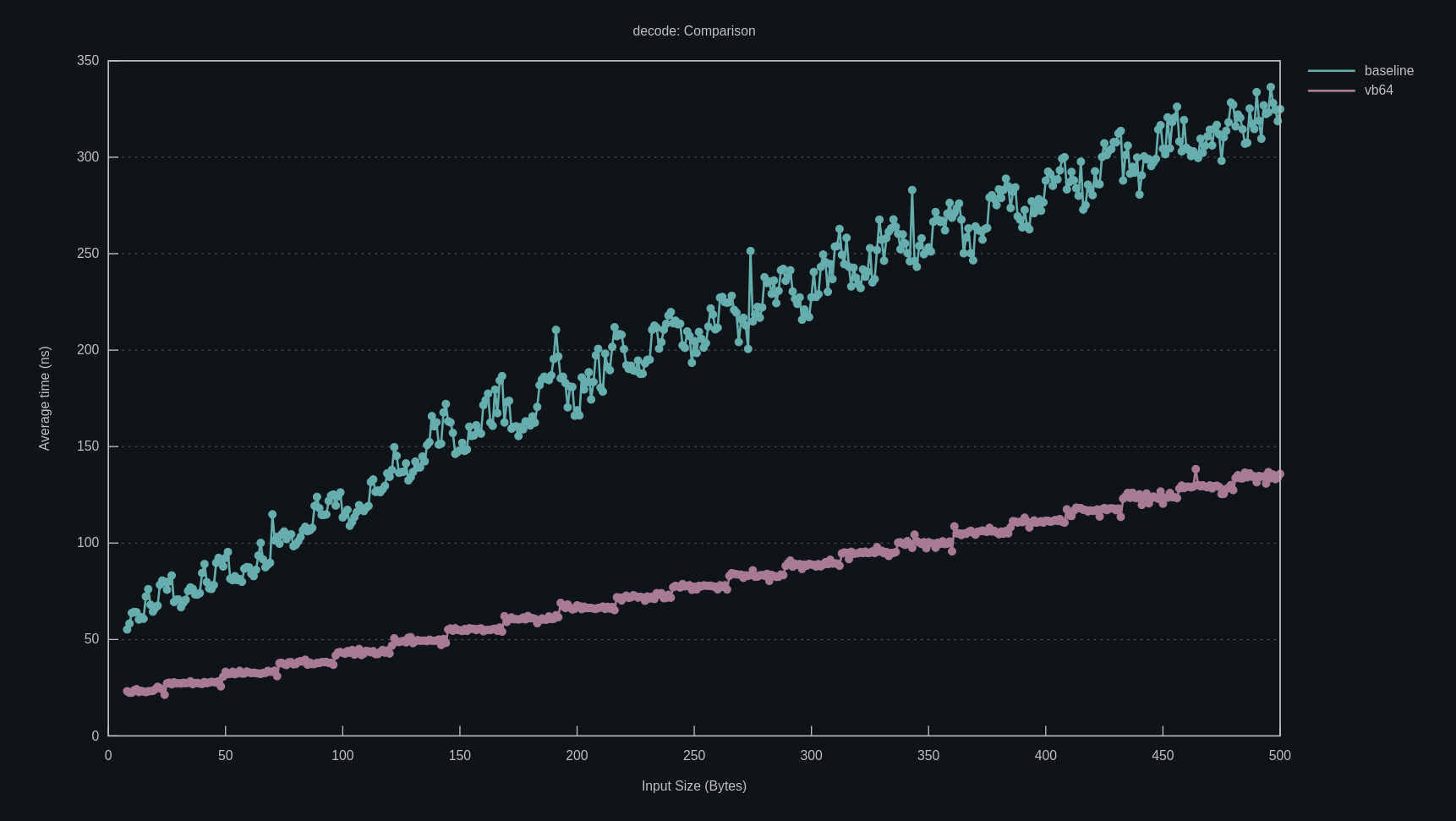
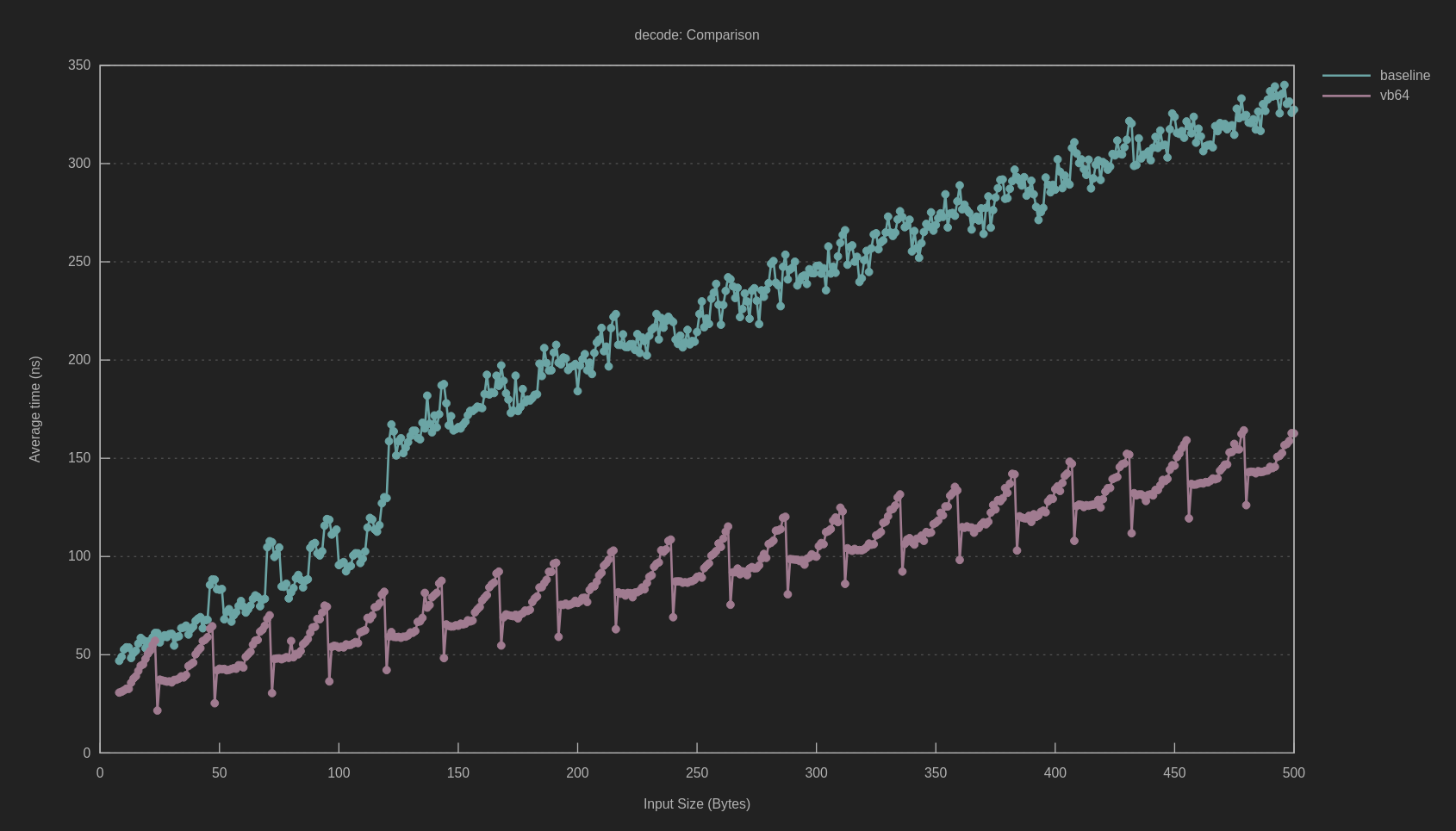
Here’s how we measure up against other Go Protobuf parsers. This is a subset of my benchmarks, since the benchmark suite contains many dozens of specimens. This was recorded on an AMD Zen 4 machine.
Throughput for various configurations of hyperpb (colored bars) vs. competing parsers (grey bars). Each successive hyperpb includes all previous optimizations, corresponding to zerocopy mode, arena reuse, and profile-guided optimization. Bigger is better.
Traditionally, Protobuf backends would generate parsers by generating source code specialized to each type. Naively, this would give the best performance, because everything would be “right-sized” to a particular message type. Unfortunately, now that we know better, there are a bunch of drawbacks:
Every type you care about must be compiled ahead-of-time. Tricky for when you want to build something generic over schemas your users provide you.
Every type contributes to a cost on the instruction cache, meaning that if your program parses a lot of different types, it will essentially flush your instruction cache any time you enter a parser. Worse still, if a parse involves enough types, the parser itself will hit instruction decoding throughput issues.
These effects are not directly visible in normal workloads, but other side-effects are visible: for example, giant switches on field numbers can turn into chains of branch instructions, meaning that higher-numbered fields will be quite slow. Even binary-searching on field numbers isn’t exactly ideal. However, we know that every Protobuf codec ever emits fields in index order (i.e., declaration order in the .proto file), which is a data conditioning fact we don’t take advantage of with a switch.
UPB solves this problem. It is a small C kernel for parsing Protobuf messages, which is completely dynamic: a UPB “parser” is actually a collection of data tables that are evaluated by a table-driven parser. In other words, a UPB parser is actually configuration for an interpreter VM, which executes Protobuf messages as its bytecode. UPB also contains many arena optimizations to improve allocation throughput when parsing complex messages.
hyperpb is a brand new library, written in the most cursed Go imaginable, which brings many of the optimizations of UPB to Go, and many new ones, while being tuned to Go’s own weird needs. The result leaves the competition in the dust in virtually every benchmark, while being completely runtime-dynamic. This means it’s faster than Protobuf Go’s own generated code, andvtprotobuf (a popular but non-conforming1 parser generator for Go).
This post is about some of the internals of hyperpb. I have also prepared a more sales-ey writeup, which you can read on the Buf blog.
UPB is awesome. It can slot easily into any language that has C FFI, which is basically every language ever.
Unfortunately, Go’s C FFI is really, really bad. It’s hard to overstate how bad cgo is. There isn’t a good way to cooperate with C on memory allocation (C can’t really handle Go memory without a lot of problems, due to the GC). Having C memory get cleaned up by the GC requires finalizers, which are very slow. Calling into C is very slow, because Go pessimistically assumes that C requires a large stack, and also calling into C does nasty things to the scheduler.
All of these things can be worked around, of course. For a while I considered compiling UPB to assembly, and rewriting that assembly into Go’s awful assembly syntax2, and then having Go assemble UPB out of that. This presents a few issues though, particularly because Go’s assembly calling convention is still in the stone age3 (arguments are passed on the stack), and because we would still need to do a lot of work to get UPB to match the protoreflect API.
Go also has a few… unique qualities that make writing a Protobuf interpreter an interesting challenge with exciting optimization opportunities.
First, of course, is the register ABI, which on x86_64 gives us a whopping nine argument and return registers, meaning that we can simply pass the entire parser state in registers all the time.
Second is that Go does not have much UB to speak of, so we can get away with a lot of very evil pointer crimes that we could not in C++ or Rust.
Third is that Protobuf Go has a robust reflection system that we can target if we design specifically for it.
Also, the Go ecosystem seems much more tolerant of less-than-ideal startup times (because the language loves life-before-main due to init() functions), so unlike UPB, we can require that the interpreter’s program be generated at runtime, meaning that we can design for online PGO. In other words, we have the perfect storm to create the first-ever Protobuf JIT compiler (which we also refer to as “online PGO” or “real-time PGO”).
Right now, hyperpb’s API is very simple. There are hyperpb.Compile* functions that accept some representation of a message descriptor, and return a *hyperpb.MessageType, which implements the protoreflect type APIs. This can be used to allocate a new *hyperpb.Message , which you can shove into proto.Unmarshal and do reflection on the result. However, you can’t mutate *hyperpb.Messages currently, because the main use-cases I am optimizing for are read-only. All mutations panic instead.
The hero use-case, using Buf’s protovalidate library, uses reflection to execute validation predicates. It looks like this:
// Compile a new message type, deserializing an encoded FileDescriptorSet.msgType:=hyperpb.CompileForBytes(schema,"my.api.v1.Request")// Allocate a new message of that type.msg:=hyperpb.NewMessage(msgType)// Unmarshal like you would any other message, using proto.Unmarshal.iferr:=proto.Unmarshal(data,msg);err!=nil{// Handle parse failure.}// Validate the message. Protovalidate uses reflection, so this Just Works.iferr:=protovalidate.Validate(msg);err!=nil{// Handle validation failure.}
We tell users to make sure to cache the compilation step because compilation can be arbitrarily slow: it’s an optimizing compiler! This is not unlike the same warning on regexp.Compile, which makes it easy to teach users how to use this API correctly.
In addition to the main API, there’s a bunch of performance tuning knobs for the compiler, for unmarshaling, and for recording profiles. Types can be recompiled using a recorded profile to be more optimized for the kinds of messages that actually come on the wire. hyperpb PGO4 affects a number of things that we’ll get into as I dive into the implementation details.
Most of the core implementation lives under internal/tdp. The main components are as follows:
tdp, which defines the “object code format” for the interpreter. This includes definitions for describing types and fields to the parser.
tdp/compiler, which contains all of the code for converting a protoreflect.MessageDescriptor into a tdp.Library, which contains all of the types relevant to a particular parsing operation.
tdp/dynamic defines what dynamic message types look like. The compiler does a bunch of layout work that gets stored in tdp.Type values, which a dynamic.Message interprets to find the offsets of fields within itself.
tdp/vm contains the core interpreter implementation, including the VM state that is passed in registers everywhere. It also includes hand-optimized routines for parsing varints and validating UTF-8.
tdp/thunks defines archetypes, which are classes of fields that all use the same layout and parsers. This corresponds roughly to a (presence, kind) pair, but not exactly. There are around 200 different archetypes.
This article won’t be a deep-dive into everything in the parser, and even this excludes large portions of hyperpb. For example, the internal/arena package is already described in a different blogpost of mine. I recommend taking a look at that to learn about how we implement a GC-friendly arena for hyperpb .
Instead, I will give a brief overview of how the object code is organized and how the parser interprets it. I will also go over a few of the more interesting optimizations we have.
Every MessageDescriptor that is reachable from the root message (either as a field or as an extension) becomes a tdp.Type . This contains the dynamic size of the corresponding message type, a pointer to the type’s default parser (there can be more than one parser for a type) and a variable number of tdp.Field values. These specify the offset of each field and provide accessor thunks, for actually extracting the value of the field.
A tdp.TypeParser is what the parser VM interprets alongside encoded Protobuf data. It contains all of the information needed for decoding a message in compact form, including tdp.FieldParsers for each of its fields (and extensions), as well as a hashtable for looking up a field by tag, which is used by the VM as a fallback.
The tdp.FieldParsers each contain:
The same offset information as a tdp.Field.
The field’s tag, in a special format.
A function pointer that gets called to parse the field.
The next field(s) to try parsing after this one is parsed.
Each tdp.FieldParser actually corresponds to a possible tag on a record for this message. Some fields have multiple different tags: for example, a repeated int32 can have a VARINT-type tag for the repeated representation, and a LEN-type tag for the packed representation.
Each field specifies which fields to try next. This allows the compiler to perform field scheduling, by carefully deciding which order to try fields in based both on their declaration order and a rough estimation of their “hotness”, much like branch scheduling happens in a program compiler. This avoids almost all of the work of looking up the next field in the common case, because we have already pre-loaded the correct guess.
I haven’t managed to nail down a good algorithm for this yet, but I am working on a system for implementing a type of “branch prediction” for PGO, that tries to provide better predictions for the next fields to try based on what has been seen before.
The offset information for a field is more than just a memory offset. A tdp.Offset includes a bit offset, for fields which request allocation of individual bits in the message’s bitfields. These are used to implement the hasbits of optional fields (and the values of bool fields). It also includes a byte offset for larger storage. However, this byte offset can be negative, in which case it’s actually an offset into the cold region.
In many messages, most fields won’t be set, particularly extensions. But we would like to avoid having to allocate memory for the very rare (i.e., “cold”) fields. For this, a special “cold region” exists in a separate allocation from the main message, which is referenced via a compressed pointer. If a message happens to need a cold field set, it takes a slow path to allocate a cold region only if needed. Whether a field is cold is a dynamic property that can be affected by PGO.
The parser is designed to make maximal use of Go’s generous ABI without spilling anything to the stack that isn’t absolutely necessary. The parser state consists of eight 64-bit integers, split across two types: vm.P1 and vm.P2. Unfortunately, these can’t be merged due to a compiler bug, as documented in vm/vm.go.
Every parser function takes these two structs as its first two arguments, and returns them as its first two results. This ensures that register allocation tries its darnedest to keep those eight integers in the first eight argument registers, even across calls. This leads to the common idiom of
Overwriting the parser state like this ensures that future uses of p1 and p2 use the values that DoSomething places in registers for us.
I spent a lot of time and a lot of profiling catching all of the places where Go would incorrectly spill parser state to the stack, which would result in stalls. I found quite a few codegen bugs in the process. Particularly notable (and shocking!) is #73589. Go has somehow made it a decade without a very basic pointer-to-SSA lifting pass (for comparison, this is a heavy-lifting cleanup pass (mem2reg) in LLVM).
The core loop of the VM goes something like this:
Are we out of bytes to parse? If so, pop a parser stack frame5. If we popped the last stack frame, parsing is done; return success.
Parse a tag. This does not fully decode the tag, because tdp.FieldParsers contain a carefully-formatted, partially-decoded tag to reduce decoding work.
Check if the next field we would parse matches the tag.
If yes, call the function pointer tdp.Field.Parser; update the current field to tdp.Field.NextOk; goto 1.
If no, update the current field to tdp.Field.NextErr; goto 3.
If no “enough times”, fall through.
Slow path: hit tdp.Field.Tags to find the matching field for that tag.
If matched, go to 3a.
If not, this is an unknown field; put it into the unknown field set; parse a tag and goto 4.
Naturally, this is implemented as a single function whose control flow consists exclusively of ifs and gotos, because getting Go to generate good control flow otherwise proved too hard.
Now, you might be wondering why the hot loop for the parser includes calling a virtual function. Conventional wisdom holds that virtual calls are slow. After all, the actual virtual call instruction is quite slow, because it’s an indirect branch, meaning that it can easily stall the CPU. However, it’s actually much faster than the alternatives in this case, due to a few quirks of our workload and how modern CPUs are designed:
Modern CPUs are not great at traversing complex “branch mazes”. This means that selecting one of ~100 alternatives using branches, even if they are well-predicted and you use unrolled binary search, is still likely to result in frequent mispredictions, and is an obstacle to other JIT optimizations in the processor’s backend.
Predicting a single indirect branch with dozens of popular targets is something modern CPUs are pretty good at. Chips and Cheese have a great writeup on the indirect prediction characteristics of Zen 4 chips.
In fact, the “optimized” form of a large switch is a jump table, which is essentially an array of function pointers. Rather than doing a large number of comparisons and direct branches, a jump table turns a switch into a load and an indirect branch.
This is great news for us, because it means we can make use of a powerful assumption about most messages: most messages only feature a handful of field archetypes. How often is it that you see a message which has more in it than int32, int64, string , and submessages? In effect, this allows us to have a very large “instruction set”, consisting of all of the different field archetypes, but a particular message only pays for what it uses. The fewer archetypes it uses at runtime, the better the CPU can predict this indirect jump.
On the other hand, we can just keep adding archetypes over time to specialize for common parse workloads, which PGO can select for. Adding new archetypes that are not used by most messages does not incur a performance penalty.
We’ve already discussed the hot/cold split, and briefly touched on the message bitfields used for bools and hasbits. I’d like to mention a few other cool optimizations that help cover all our bases, as far as high-performance parsing does.
The fastest memcpy implementation is the one you don’t call. For this reason, we try to, whenever possible, avoid copying anything out of the input buffer. strings and bytes are represented as zc.Ranges, which are a packed pair of offset+length in a uint64. Protobuf is not able to handle lengths greater than 2GB properly, so we can assume that this covers all the data we could ever care about. This means that a bytes field is 8 bytes, rather than 24, in our representation.
Zerocopy is also used for packed fields. For example, a repeated double will typically be encoded as a LEN record. The number of float64s in this record is equal to its length divided by 8, and the float64s are already encoded in IEEE754 format for us. So we can just retain the whole repeated fields as a zc.Range . Of course, we need to be able to handle cases where there are multiple disjoint records, so the backing repeated.Scalars can also function as a 24-byte arena slice. Being able to switch between these modes gracefully is a delicate and carefully-tested part of the repeated field thunks.
Surprisingly, we also use zerocopy for varint fields, such as repeated int32. Varints are variable-length, so we can’t just index directly into the packed buffer to get the n th element… unless all of the elements happen to be the same size. In the case that every varint is one byte (so, between 0 and 127), we can zerocopy the packed field. This is a relatively common scenario, too, so it results in big savings6. We already count the number of varints in the packed field in order to preallocate space for it, so this doesn’t add extra cost. This counting is very efficient because I have manually vectorized the loop.
PGO records the median size of each repeated/map field, and that is used to calculate a “preload” for each repeated field. Whenever the field is first allocated, it is pre-allocated using the preload to try to right-size the field with minimal waste.
Using the median ensures that large outliers don’t result in huge memory waste; instead, this guarantees that at least 50% of repeated fields will only need to allocate from the arena once. Packed fields don’t use the preload, since in the common case only one record appears for packed fields. This mostly benefits string- and message-typed repeated fields, which can’t be packed.
We don’t use Go’s built-in map, because it has significant overhead in some cases: in particular, it has to support Go’s mutation-during-iteration semantics, as well as deletion. Although both are Swisstables7 under the hood, my implementation can afford to take a few shortcuts. It also allows our implementation to use arena-managed memory. swiss.Tables are used both for the backing store of map fields, and for maps inside of tdp.Types.
Currently, the hash used is the variant of fxhash used by the Rust compiler. This greatly out-performs Go’s maphash for integers, but maphash is better for larger strings. I hope to maybe switch to maphash at some point for large strings, but it hasn’t been a priority.
Hitting the Go allocator is always going to be a little slow, because it’s a general-case allocator. Ideally, we should learn the estimated memory requirements for a particular workload, and then allocate a single block of that size for the arena to portion out.
The best way to do this is via arena reuse In the context of a service, each request has a bounded lifetime on the message that it parses. Once that lifetime is over (the request is complete), the message is discarded. This gives the programmer an opportunity to reset the backing arena, so that it keeps its largest memory block for re-allocation.
You can show that over time, this will cause the arena to never hit the Go allocator. If the largest block is too small for a message, a block twice as large will wind up getting allocated. Messages that use the same amount of memory will keep doubling the largest block, until the largest block is large enough to fit the whole message. Memory usage will be at worst 2x the size of this message. Note that, thanks to extensive use of zero-copy optimizations, we can often avoid allocating memory for large portions of the message.
Of course, arena re-use poses a memory safety danger, if the previously allocated message is kept around after the arena is reset. For this reason, it’s not the default behavior. Using arena resets is a double-digit percentage improvement, however.
Go does not properly support unions, because the GC does not keep the necessary book-keeping to distinguish a memory location that may be an integer or a pointer at runtime. Instead, this gets worked around using interfaces, which is always a pointer to some memory. Go’s GC can handle untyped pointers just fine, so this just works.
The generated API for Protobuf Go uses interface values for oneofs. This API is… pretty messy to use, unfortunately, and triggers unnecessary allocations, (much like optional fields do in the open API).
However, my arena design (read about it here) makes it possible to store arena pointers on the arena as if they are integers, since the GC does not need to scan through arena memory. Thus, our oneofs are true unions, like in C++.
hyperpb is really exciting because its growing JIT capabilities offer an improvement in the state of the art over UPB. It’s also been a really fun challenge working around Go compiler bugs to get the best assembly possible. The code is already so well-optimized that re-building the benchmarks with the Go compiler’s own PGO mode (based on a profile collected from the benchmarks) didn’t really seem to move the needle!
I’m always working on making hyperpb better (I get paid for it!) and I’m always excited to try new optimizations. If you think of something, file an issue! I have meticulously commented most things within hyperpb , so it should be pretty easy to get an idea of where things are if you want to contribute.
I would like to write more posts diving into some of the weeds of the implementation. I can’t promise anything, but there’s lots to talk about. For now… have fun source-diving!
There’s a lot of other things we could be doing: for example, we could be using SIMD to parse varints, we could have smarter parser scheduling, we could be allocating small submessages inline to improve locality… there’s still so much we can do!
And most importantly, I hope you’ve learned something new about performance optimization!
vtprotobuf gets a lot of things wrong that make it beat us in like two benchmarks, because it’s so sloppy. For example, vtprotobuf believes that it’s ok to not validate UTF-8 strings. This is non-conforming behavior. It also believes that map entries’ fields are always in order and always populated, meaning that valid Protobuf messages containing maps can be parsed incorrectly. This sloppiness is unacceptable, which is why hyperpb goes to great lengths to implement all of Protobuf correctly. ↩
Never gonna let Rob live that one down. Of all of Rob’s careless design decisions, the assembler is definitely one of the least forgivable ones. ↩
There are only really two pieces of code in hyperpb that could benefit from hand-written assembly: varint decoding and UTF-8 validation. Both of these vectorize well, however, ABI0 is so inefficient that no hand-written implementation will be faster.
If I do wind up doing this, it will require a build tag like hyperasm, along with something like -gcflags=buf.build/go/hyperpb/internal/asm/...=-+ to treat the assembly implementations as part of the Go runtime, allowing the use of ABIInternal. But even then, this only speeds up parsing of large (>2 byte) varints. ↩
This is PGO performed by hyperpb itself; this is unrelated to gc’s own PGO mode, which seems to not actually make hyperpb faster. ↩
Yes, the parser manages its own stack separate from the goroutine stack. This ensures that nothing in the parser has to be reentrant. The only time the stack is pushed to is when we “recurse” into a submessage. ↩
Large packed repeated fields are where the biggest wins are for us. Being able to zero-copy large packed int32 fields full of small values allows us to eliminate all of the overhead that the other runtimes are paying for; we also choose different parsing strategies depending on the byte-to-varint ratio of the record.
Throughput for various repeated field benchmarks. This excludes the repeated fixed32 benchmarks, since those achieve such high throughputs (~20 Gbps) that they make the chart unreadable.
These optimizations account for the performance difference between descriptor/#00 and descriptor/#01 in the first benchmark chart. The latter is a FileDescriptorSet containing SourceCodeInfo, Protobuf’s janky debuginfo format. It is dominated by repeated int32 fields.
NB: This chart is currently missing the Y-axis, I need to have it re-made. ↩
Map parsing performance has been a bit of a puzzle. vtprotobuf cheats by rejecting some valid map entry encodings, such as (in Protoscope) {1: {"key"}} (value is implied to be ""), while mis-parsing others, such as {2: {"value"} 1: {"key"}} (fields can go in any order), since they don’t actually validate the field numbers like hyperpb does.
Here’s where the benchmarks currently stand for maps:
Throughput for various map parsing benchmarks.
Maps, I’m told, are not very popular in Protobuf, so they’re not something I have tried to optimize as hard as packed repeated fields. ↩
It’s no secret that my taste in programming languages is very weird for a programming language enthusiast professional. Several of my lastfewposts are about Go, broadly regarded as the programming language equivalent of eating plain oatmeal for breakfast.
To make up for that, I’m going to write about the programming language equivalent of diluting your morning coffee with Everclear. I am, of course, talking about C++.
If you’ve ever had the misfortune of doing C++ professionally, you’ll know that the C++ standard library is really bad. Where to begin?
Well, the associative containers are terrible. Due to bone-headed API decisions, std::unordered_map MUST be a closed-addressing, array-of-linked-lists map, not a Swisstable, despite closed-addressing being an outdated technology. std::map, which is not what you usually want, must be a red-black tree. It can’t be a b-tree, like every sensible language provides for the ordered map.
std::optional is a massive pain in the ass to use, and is full of footguns, like operator*. std::variant is also really annoying to use. std::filesystem is full of sharp edges. And where are the APIs for signals?
Everything is extremely wordy. std::hardware_destructive_interference_size could have been called std::cache_line. std::span::subspan could have used opeartor[]. The standard algorithms are super wordy, because they deal with iterator pairs. Oh my god, iterator pairs. They added std::ranges, which do not measure up to Rust’s Iterator at all!
I’m so mad about all this! The people in charge of C++ clearly, actively hate their users!1 They want C++ to be as hard and unpleasant as possible to use. Many brilliant people that I am lucky to consider friends and colleagues, including Titus Winters, JeanHeyd Meneide, Matt Fowles-Kulukundis, and Andy Soffer, have tried and mostly failed2 to improve the language.
This is much to say that I believe C++ in its current form is unfixable. But that’s only due to the small-mindedness of a small cabal based out of Redmond. What if we could do whatever we wanted? What if we used C++’s incredible library-building language features to build a brand-new language?
For the last year-or-so I’ve been playing with a wild idea: what would C++ look like if we did it over again? Starting from an empty C++20 file with no access to the standard library, what can we build in its place?
Titus started Abseil while at Google, whose namespace, absl, is sometimes said to stand for “a better standard library”3. To me, Abseil is important because it was an attempt to work with the existing standard library and make it better, while retaining a high level of implementation quality that a C++ shop’s home-grown utility library won’t have, and a uniformity of vision that Boost is too all-over-the-place to achieve.
Rather than trying to coexist with the standard library, I want to surpass it. As a form of performance art, I want to discover what the standard library would look like if we designed it today, in 2025.
In this sense, I want to build something that isn’t just better. It should be the C++ standard library from the best possible world. It is the best possible library. This is why my library’s namespace is best.
In general, I am trying not to directly copy either what C++, or Abseil, or Rust, or Go did. However, each of them has really interesting ideas, and the best library probably lies in some middle-ground somewhere.
The rest of this post will be about what I have achieved with best so far, and where I want to take it. You can look at the code here.
We’re throwing out everything, and that includes <type_traits>. This is a header which shows its age: alias templates were’t added until C++14, and variable templates were added in C++17. As a result, many things that really aught to be concepts have names like best::is_same_v. All of these now have concept equivalents in <concepts>.
I have opted to try to classify type traits into separate headers to make them easier to find. They all live under //best/meta/traits, and they form the leaves of the dependency graph.
For example, arrays.h contains all of the array traits, such as best::is_array, best::un_array (to remove an array extent), and best::as_array, which applies an extent to a type T, such that best::as_array<T, 0> is not an error.
types.h contains very low-level metaprogramming helpers, such as:
best::id and best::val, the identity traits for type- and value-kinded traits.
best::same<...>, which returns whether an entire pack of types is all equal.
best::lie, our version of std::declval.
best::select, our std::conditional_t.
best::abridge, a “symbol compression” mechanism for shortening the names of otherwise huge symbols.
funcs.h provides best::tame, which removes the qualifiers from an abominable function type. quals.h provides best::qualifies_to, necessary for determining if a type is “more const” than another. empty.h provides a standard empty type that interoperates cleanly with void.
On top of the type traits is the metaprogramming library //best/meta, which includes generalized constructibility traits in init.h (e.g., to check that you can, in fact, initialize a T& from a T&&, for example). tlist.h provides a very general type-level heterogenous list abstraction; a parameter pack as-a-type.
The other part of “the foundation” is //best/base, which mostly provides access to intrinsics, portability helpers, macros, and “tag types” such as our versions of std::in_place. For example, macro.h provides BEST_STRINGIFY(), port.h provides BEST_HAS_INCLUDE(), and hint.h provides best::unreachable().
guard.h provides our version of the Rust ? operator, which is not an expression because statement expressions are broken in Clang.
Finally, within //best/container we find best::object, a special type for turning any C++ type into an object (i.e., a type that you can form a reference to). This is useful for manipulating any type generically, without tripping over the assign-through semantics of references. For example, best::object<T&> is essentially a pointer.
On top of this foundation we build the basic algebraic data types of best: best::row and best::choice, which replace std::tuple and std::variant.
best::row<A, B, C> is a heterogenous collection of values, stored inside of best::objects. This means that best::row<int&> has natural rebinding, rather than assign-through, semantics.
Accessing elements is done with at(): my_row.at<0>() returns a reference to the first element. Getting the first element is so common that you can also use my_row.first(). Using my_row.object<0>() will return a reference to a best::object instead, which can be used for rebinding references. For example:
intx=0,y=0;best::row<int&>a{x};a.at<0>()=42;// Writes to x.a.object<0>()=y;// Rebinds a.0 to y.a.at<0>()=2*x;// Writes to y.
There is also second() and last(), for the other two most common elements to access.
best::row is named so in reference to database rows: it provides many operations for slicing and dicing that std::tuple does not.
For example, in addition to extracting single elements, it’s also possible to access contiguous subsequences, using best::bounds: a.at<best::bounds{.start = 1, .end = 10}>()! There are also a plethora of mutation operations:
a + b concatenates tuples, copying or moving as appropriate (a + BEST_MOVE(b) will move out of the elements of b, for example).
a.push(x) returns a copy of a with x appended, while a.insert<n>(x) does the same at an arbitrary index.
a.update<n>(x)replaces the nth element with x, potentially of a different type.
a.remove<n>() deletes the nth element, while a.erase<...>() deletes a contiguous range.
a.splice<best::bounds{...}>(...) splices a row into another row, offering a general replace/delete operation that all of the above operations are implemented in terms of.
gather() and scatter() are even more general, allowing for non-contiguous indexing.
Meanwhile, std::apply is a method now: a.apply(f) calls f with a’s elements as its arguments. a.each(f) is similar, but instead expands to n unary calls of f, one with each element.
And of course, best::row supports structured bindings.
Meanwhile, best::choice<A, B, C> contains precisely one value from various types. There is an underlying best::pun<A, B, C> type that implements a variadic untagged union that works around many of C++’s bugs relating to unions with members of non-trivial type.
The most common way to operate on a choice is to match on it:
Which case gets called here is chosen by overload resolution, allowing us to write a default case as [](auto&&) { ... }.
Which variant is currently selected can be checked with z.which(), while specific variants can be accessed with z.at(), just like a best::row, except that it returns a best::option<T&>.
best::choice is what all of the other sum types, like best::option and best::result, are built out of. All of the clever layout optimizations live here.
Speaking of best::option<T>, that’s our option type. It’s close in spirit to what Option<T> is in Rust. best has a generic niche mechanism that user types can opt into, allowing best::option<T&> to be the same size as a pointer, using nullptr for the best::none variant.
best::option provides the usual transformation operations: map, then, filter. Emptiness can be checked with is_empty() or has_value(). You can even pass a predicate to has_value() to check the value with, if it’s present: x.has_value([](auto& x) { return x == 42; }).
The value can be accessed using operator* and operator->, like std::optional; however, this operation is checked, instead of causing UB if the option is empty. value_or() can be used to unwrap with a default; the default can be any number of arguments, which are used to construct the default, or even a callback. For example:
best::option<Foo>x;// Pass arguments to the constructor.do_something(x.value_or(args,to,foo));// Execute arbitrary logic if the value is missing.do_something(x.value_or([]{returnFoo(...);}))
best::option<void> also Just Works (in fact, best::option<T> is a best::choice<void, T> internally), allowing for truly generic manipulation of optional results.
best::result<T, E> is, unsurprisingly, the analogue of Rust’s Result<T, E>. Because it’s a best::choice internally, best::result<void, E> works as you might expect, and is a common return value for I/O operations.
It’s very similar to best::option, including offering operator-> for accessing the “ok” variant. This enables succinct idioms:
r.ok() and r.err() return best::options containing references to the ok and error variants, depending on which is actually present; meanwhile, a best::option can be converted into a best::result using ok_or() or err_or(), just like in Rust.
best::results are constructed using best::ok and best::err. For example:
These internally use best::args, a wrapper over best::row that represents a “delayed initialization” that can be stored in a value. It will implicitly convert into any type that can be constructed from its elements. For example:
Foofoo=best::args(args,to,foo);// Calls Foo::Foo(args, to, foo).
Of course, all of these ADTs need to be built on top of pointer operations, which is where //best/memory comes in. best::ptr<T> is a generalized pointer type that provides many of the same operations as Rust’s raw pointers, including offsetting, copying, and indexing. Like Rust pointers, best::ptr<T> can be a fat pointer, i.e., it can carry additional metadata on top of the pointer. For example, best::ptr<int[]> remembers the size of the array.
Providing metadata for a best::ptr is done through a member alias called BestPtrMetadata. This alias should be private, which best is given access to by befriending best::access. Types with custom metadata will usually not be directly constructible (because they are of variable size), and must be manipulated exclusively through types like best::ptr.
Specifying custom metadata allows specifying what the pointer dereferences to. For example, best::ptr<int[]> dereferences to a best::span<int>, meaning that all the span operations are accessible through operator->: for example, my_array_ptr->first().
Most of this may seem a bit over-complicated, since ordinary C++ raw pointers and references are fine for most uses. However, best::ptr is the foundation upon which best::box<T> is built on. best::box<T> is a replacement for std::unique_ptr<T> that fixes its const correctness and adds Rust Box-like helpers. best::box<T[]> also works, but unlike std::unique_ptr<T[]>, it remembers its size, just like best::ptr<T[]>.
best::box is parameterized by its allocator, which must satisfy best::allocator, a much less insane API than what std::allocator offers. best::malloc is a singleton allocator representing the system allocator.
best::span<T>, mentioned before, is the contiguous memory abstraction, replacing std::span. Like std::span, best::span<T, n> is a fixed-length span of n elements. Unlike std::span, the second parameter is a best::option<size_t>, not a size_t that uses -1 as a sentinel.
best::span<T> tries to approximate the API of Rust slices, providing indexing, slicing, splicing, search, sort, and more. Naturally, it’s also iterable, both forwards and backwards, and provides splitting iterators, just like Rust.
Slicing and indexing is always bounds-checked. Indexing can be done with size_t values, while slicing uses a best::bounds:
best::bounds is a generic mechanism for specifying slicing bounds, similar to Rust’s range types. You can specify the start and end (exclusive), like x..y in Rust. You can also specify an inclusive end using .inclusive_end = 5, equivalent to Rust’s x..=y. And you can specify a count, like C++’s slicing operations prefer: {.start = 1, .count = 5}. best::bounds itself provides all of the necessary helpers for performing bounds checks and crashing with a nice error message. best::bounds is also iterable, as we’ll see shortly.
best::layout is a copy of Rust’s Layout type, providing similar helpers for performing C++-specific size and address calculations.
C++ iterator pairs suck. C++ ranges suck. best provides a new paradigm for iteration that is essentially just Rust Iterators hammered into a C++ shape. This library lives in //best/iter.
To define an iterator, you define an iterator implementation type, which must define a member function named next() that returns a best::option:
This type is an implementation detail; the actual iterator type is best::iter<my_iter_impl>. best::iter provides all kinds of helpers, just like Iterator, for adapting the iterator or consuming items out of it.
Iterators can override the behavior of some of these adaptors to be more efficient, such as for making count() constant-time rather than linear. Iterators can also offer extra methods if they define the member alias BestIterArrow; for example, the iterators for best::span have a ->rest() method for returning the part of the slice that has not been yielded by next() yet.
One of the most important extension points is size_hint(), analogous to Iterator::size_hint(), for right-sizing containers that the iterator is converted to, such as a best::vec.
And of course, best::iter provides begin/end so that it can be used in a C++ range-for loop, just like C++20 ranges do. best::int_range<I>4, which best::bounds is an instantiation of, is also an iterator, and can be used much like Rust ranges would:
Iterators brings us to the most complex container type that’s checked in right now, best::vec. Not only can you customize its allocator type, but you can customize its small vector optimization type.
In libc++, std::strings of at most 23 bytes are stored inline, meaning that the strings’s own storage, rather than heap storage, is used to hold them. best::vec generalizes this, by allowing any trivially copyable type to be inlined. Thus, a best::vec<int> will hold at most five ints inline, on 64-bit targets.
best::vec mostly copies the APIs of std::vector and Rust’s Vec. Indexing and slicing works the same as with best::span, and all of the best::span operations can be accessed through ->, allowing for things like my_vec->sort(...).
I have an active (failing) PR which adds best::table<K, V>, a general hash table implementation that can be used as either a map or a set. Internally it’s backed by a Swisstable5 implementation. Its API resembles neither std::unordered_map, absl::flat_hash_map, or Rust’s HashMap. Instead, everything is done through a general entry API, similar to that of Rust, but optimized for clarity and minimizing hash lookups. I want to get it merged soonish.
Beyond best::table, I plan to add at least the following containers:
best::tree, a btree map/set with a similar API.
best::heap, a simple min-heap implementation.
best::lru, a best::table with a linked list running through it for in-order iteration and oldest-member eviction.
best’s string handling is intended to resemble Rust’s as much as possible; it lives within //best/text. best::rune is the Unicode scalar type, which is such that it is always within the valid range for a Unicode scalar, but including the unpaired surrogates. It offers a number of relatively simple character operations, but I plan to extend it to all kinds of character classes in the future.
best::str is our replacement for best::string_view, close to Rust’s str: a sequence of valid UTF-8 bytes, with all kinds of string manipulation operations, such as rune search, splitting, indexing, and so on.
best::rune and best::str use compiler extensions to ensure that when constructed from literals, they’re constructed from valid literals. This means that the following won’t compile!
best::str is a best::span under the hood, which can be accessed and manipulated the same way as the underlying &[u8] to &str is.
best::strbuf is our std::string equivalent. There isn’t very much to say about it, because it works just like you’d expect, and provides a Rust String-like API.
Where this library really shines is that everything is parametrized over encodings. best::str is actually a best::text<best::utf8>; best::str16 is then best::text<best::utf16>. You can write your own text encodings, too, so long as they are relatively tame and you provide rune encode/decode for them. best::encoding is the concept
best::text is always validly encoded; however, sometimes, that’s not possible. For this reason we have best::pretext, which is “presumed validly encoded”; its operations can fail or produce replacement characters if invalid code units are found. There is no best::pretextbuf; instead, you would generally use something like a best::vec<uint8_t> instead.
Unlike C++, the fact that a best::textbuf is a best::vec under the hood is part of the public interface, allowing for cheap conversions and, of course, we get best::vec’s small vector optimization for free.
best provides the following encodings out of the box: best::utf8, best::utf16, best::utf32, best::wtf8, best::ascii, and best::latin1.
Through the power of compiler extensions and constexpr, the format is actually checked at compile time!
The available formats are the same as Rust’s, including the {} vs {:?} distinction. But it’s actually way more flexible. You can use any ASCII letter, and types can provide multiple custom formatting schemes using letters. By convention, x, X, b, and o all mean numeric bases. q will quote strings, runes, and other text objects; p will print pointer addresses.
The special format {:!} “forwards from above”; when used in a formatting implementation, it uses the format specifier the caller used. This is useful for causing formats to be “passed through”, such as when printing lists or best::option.
Any type can be made formattable by providing a friend template ADL extension (FTADLE) called BestFmt. This is analogous to implementing a trait like fmt::Debug in Rust, however, all formatting operations use the same function; this is similar to fmt.Formatter in Go.
The best::formatter type, which gets passed into BestFmt, is similar to Rust’s Formatter. Beyond being a sink, it also exposes information on the specifier for the formatting operation via current_spec(), and helpers for printing indented lists and blocks.
BestFmtQuery is a related FTADLE that is called to determine what the valid format specifiers for this type are. This allows the format validator to reject formats that a type does not support, such as formatting a best::str with {:x}.
best::format returns (or appends to) a best::strbuf; best::println and best::eprintln can be used to write to stdout and stderr.
Within the metaprogramming library, //best/meta:reflect offers a basic form of reflection. It’s not C++26 reflection, because that’s wholely overkill. Instead, it provides a method for introspecting the members of structs and enums.
For example, suppose that we want to have a default way of formatting arbitrary aggregate structs. The code for doing this is actually devilishly simple:
voidBestFmt(auto&fmt,constbest::is_reflected_structauto&value){// Reflect the type of the struct.autorefl=best::reflect<decltype(value)>;// Start formatting a "record" (key-value pairs).autorec=fmt.record(refl.name());// For each field in the struct...refl.each([&](autofield){// Add a field to the formatting record...rec.field(field.name(),// ...whose name is the field...value->*field,// ...and with the appropriate value.);});}
best::reflect provides access to the fields (or enum variants) of a user-defined type that opts itself in by providing the BestReflect FTADLE, which tells the reflection framework what the fields are. The simplest version of this FTADLE looks like this:
best::mirror is essentially a “reflection builder” that offers fine-grained control over what reflection actually shows of a struct. This allows for hiding fields, or attaching tags to specific fields, which generic functions can then introspect using best::reflected_field::tags().
The functions on best::reflected_type allow iterating over and searching for specific fields (or enum variants); these best::reflected_fields provide metadata about a field (such as its name) and allow accessing it, with the same syntax as a pointer-to-member: value->*field.
Explaining the full breadth (and implementation tricks) of best::reflect would be a post of its own, so I’ll leave it at that.
best provides a unit testing framework under //best/test, like any good standard library should. To define a test, you define a special kind of global variable:
This is very similar to a Go unit test, which defines a function that starts with Test and takes a *testing.T as its argument. The best::test& value offers test assertions and test failures. Through the power of looking at debuginfo, we can extract the name MyTest from the binary, and use that as the name of the test directly.
That’s right, this is a C++ test framework with no macros at all!
Meanwhile, at //best/cli we can find a robust CLI parsing library, in the spirit of #[derive(clap::Parser)] and other similar Rust libraries. The way it works is you first define a reflectable struct, whose fields correspond to CLI flags. A very basic example of this can be found in test.h, since test binaries define their own flags:
structtest::flagsfinal{best::vec<best::strbuf>skip;best::vec<best::strbuf>filters;constexprfriendautoBestReflect(auto&m,flags*){returnm.infer().with(best::cli::app{.about="a best unit test binary"}).with(&flags::skip,best::cli::flag{.arg="FILTER",.help="Skip tests whose names contain FILTER",}).with(&flags::filters,best::cli::positional{.name="FILTERS",.help="Include only tests whose names contain FILTER",});}};
Using best::mirror::with, we can apply tags to the individual fields that describe how they should be parsed and displayed as CLI flags. A more complicated, full-featured example can be found at toy_flags.h, which exercises most of the CLI parser’s features.
best::parse_flags<MyFlags>(...) can be used to parse a particular flag struct from program inputs, independent of the actual argv of the program. A best::cli contains the actual parser metadata, but this is not generally user-accessible; it is constructed automatically using reflection.
Streamlining top-level app execution can be done using best::app, which fully replaces the main() function. Defining an app is very similar to defining a test:
best::appMyApp=[](MyFlags&flags){// Do something cool!};
This will automatically record the program inputs, run the flag parser for MyFlags (printing --help and existing, when requested), and then call the body of the lambda.
The lambda can either return void, an int (as an exit code) or even a best::result, like Rust. best::app is also where the argv of the program can be requested by other parts of the program.
There’s still a lot of stuff I want to add to best. There’s no synchronization primitives, neither atomics nor locks or channels. There’s no I/O; I have a work-in-progress PR to add best::path and best::file. I’d like to write my own math library, best::rc (reference-counting), and portable SIMD. There’s also some other OS APIs I want to build, such as signals and subprocesses. I want to add a robust PRNG, time APIs, networking, and stack symbolization.
Building the best C++ library is a lot of work, not the least because C++ is a very tricky language and writing exhaustive tests is tedious. But it manages to make C++ fun for me again!
I would love to see contributions some day. I don’t expect anyone to actually use this, but to me, it proves C++ could be so much better.
I will grant that JeanHeyd has made significant process where many people believed was impossible. He appears to have the indomitable willpower of a shōnen protagonist. ↩
I have heard an apocryphal story that the namespace was going to be abc or abcl, because it was “Alphabet’s library”. This name was ultimately shot down by the office of the CEO, or so the legend goes. ↩
This may get renamed to best::interval or even best::range We’ll see! ↩
The fourth time I’ve written one in my career, lmao. I also wrote a C implementation at one point. My friend Matt has an excellent introduction to the Swisstable data structure. ↩
2025-07-07 • 1881 words • 20 minutes •#dark-arts • #go
Most people don’t know that Go has special syntax for directives. Unfortunately, it’s not real syntax, it’s just a comment. For example, //go:noinline causes the next function declaration to never get inlined, which is useful for changing the inlining cost of functions that call it.
There are three types of directives:
The ones documented in gc’s doc comment. This includes //go:noinline and //line.
The ones documented elsewhere, such as //go:build and //go:generate.
The ones documented in runtime/HACKING.md, which can only be used if the -+ flag is passed to gc. This includes //go:nowritebarrier.
The ones not documented at all, whose existence can be discovered by searching the compiler’s tests. These include //go:nocheckptr, //go:nointerface, and //go:debug.
We are most interested in a directive of the first type, //go:nosplit. According to the documentation:
The //go:nosplit directive must be followed by a function declaration. It specifies that the function must omit its usual stack overflow check. This is most commonly used by low-level runtime code invoked at times when it is unsafe for the calling goroutine to be preempted.
What does this even mean? Normal program code can use this annotation, but its behavior is poorly specified. Let’s dig in.
Go allocates very small stacks for new goroutines, which grow their stack dynamically. This allows a program to spawn a large number of short-lived goroutines without spending a lot of memory on their stacks.
This means that it’s very easy to overflow the stack. Every function knows how large its stack is, and runtime.g, the goroutine struct, contains the end position of the stack; if the stack pointer is less than it (the stack grows up) control passes to runtime.morestack, which effectively preempts the goroutine while its stack is resized.
In effect, every Go function has the following code around it:
Note that r14 holds a pointer to the current runtime.g, and the stack limit is the third word-sized field (runtime.g.stackguard0) in that struct, hence the offset of 16. If the stack is about to be exhausted, it jumps to a special block at the end of the function that spills all of the argument registers, traps into the runtime, and, once that’s done, unspills the arguments and re-starts the function.
Note that arguments are spilled before adjusting rsp, which means that the arguments are written to the caller’s stack frame. This is part of Go’s ABI; callers must allocate space at the top of their stack frames for any function that they call to spill all of its registers for preemption1.
Preemption is not reentrant, which means that functions that are running in the context of a preempted G or with no G at all must not be preempted by this check.
In the bad old days, Go’s stacks were split up into segments, where each segment ended with a pointer to the next, effectively replacing the stack’s single array with a linked list of such arrays.
Segmented stacks were terrible. Instead of triggering a resize, these prologues were responsible for updating rsp to the next (or previous) block by following this pointer, whenever the current segment bottomed out. This meant that if a function call happened to be on a segment boundary, it would be extremely slow in comparison to other function calls, due to the significant work required to update rsp correctly.
This meant that unlucky sizing of stack frames meant sudden performance cliffs. Fun!
Go has since figured out that segmented stacks are a terrible idea. In the process of implementing a correct GC stack scanning algorithm (which it did not have for many stable releases), it also gained the ability to copy the contents of a stack from one location to another, updating pointers in such a way that user code wouldn’t notice.
This stack splitting code is where the name “nosplit” comes from.
A nosplit function does not load and branch on runtime.g.stackguard0, and simply assumes it has enough stack. This means that nosplit functions will not preempt themselves, and, as a result, are noticeably faster to call in a hot loop. Don’t believe me?
The time spent at each instruction (for the whole benchmark, where I made sure equal time was spent on each test case with -benchtime Nx) is comparable for all of the instructions these functions share, but an additional ~2% cost is incurred for the stack check.
This is a very artificial setup, because the g struct is always in L1 in the yessplit benchmark due to the fact that no other memory operations occur in the loop. However, for very hot code that needs to saturate the cache, this can have an outsized effect due to cache misses. We can enhance this benchmark by adding an assembly function that executes clflush [r14], which causes the g struct to be ejected from all caches.
If we add a call to this function to both benchmark loops, we see the staggering cost of a cold fetch from RAM show up in every function call: 120.1 nanosecods for BenchmarkCall/nosplit, versus 332.1 nanoseconds for BenchmarkCall/yessplit. The 200 nanosecond difference is a fetch from main memory. An L1 miss is about 15 times less expensive, so if the g struct manages to get kicked out of L1, you’re paying about 15 or so nanoseconds, or about two map lookups!
Despite the language resisting adding an inlining heuristic, which programmers would place everywhere without knowing what it does, they did provide something worse that makes code noticeably faster: nosplit.
The Go linker contains a check to verify that any chain of nosplit functions which call nosplit functions do not overflow a small window of extra stack, which is where the stack frames of nosplit functions live if they go past stackguard0.
Every stack frame contributes some stack use (for the return address, at minimum), so the number of functions you can call before you get this error is limited. And because every function needs to allocate space for all of its callees to spill their arguments if necessary, you can hit this limit every fast if every one of these functions uses every available argument register (ask me how I know).
Also, turning on fuzzing instruments the code by inserting nosplit calls into the fuzzer runtime around branches, meaning that turning on fuzzing can previously fine code to no longer link. Stack usage also varies slightly by architecture, meaning that code which builds in one architecture fails to link in others (most visible when going from 32-bit to 64-bit).
There is no easy way to control directives using build tags (two poorly-designed features collide), so you cannot just “turn off” performance-sensitive nosplits for debugging, either.
For this reason, you must be very very careful about using nosplit for performance.
Excitingly, nosplit functions whose addresses are taken do not have special codegen, allowing us to defeat the linker stack check by using virtual function calls.
This will quickly exhaust the main G’s tiny stack and segfault in the most violent way imaginable, preventing the runtime from printing a debug trace. All this program outputs is signal: segmentation fault.
It turns out that nosplit has various other fun side-effects that are not documented anywhere. The main thing it does is it contributes to whether a function is considered “unsafe” by the runtime.
Consider the following program:
packagemainimport("fmt""os""runtime""time")funcmain(){forrangeruntime.GOMAXPROCS(0){gofunc(){for{}}()}time.Sleep(time.Second)// Wait for all the other Gs to start.fmt.Println("Hello, world!")os.Exit(0)}
This program will make sure that every P becomes bound to a G that loops forever, meaning they will never trap into the runtime. Thus, this program will hang forever, never printing its result and exiting. But that’s not what happens.
Thanks to asynchronous preemption, the scheduler will detect Gs that have been running for too long, and preempt its M by sending a signal to it (due to happenstance, this is SIGURG of all things.)
However, asynchronous preemption is only possible when the M stops due to the signal at a safe point, as determined by runtime.isAsyncSafePoint. It includes the following block of code:
up,startpc:=pcdatavalue2(f,abi.PCDATA_UnsafePoint,pc)ifup==abi.UnsafePointUnsafe{// Unsafe-point marked by compiler. This includes// atomic sequences (e.g., write barrier) and nosplit// functions (except at calls).returnfalse,0}
If we chase down where this value is set, we’ll find that it is set explicitly for write barrier sequences, for any function that is “part of the runtime” (as defined by being built with the -+ flag) and for any nosplit function.
With a small modification of hoisting the go body into a nosplit function, the following program will run forever: it will never wake up from time.Sleep.
packagemainimport("fmt""os""runtime""time")//go:nosplitfuncforever(){for{}}funcmain(){forrangeruntime.GOMAXPROCS(0){goforever()}time.Sleep(time.Second)// Wait for all the other Gs to start.fmt.Println("Hello, world!")os.Exit(0)}
Even though there is work to do, every P is bound to a G that will never reach a safe point, so there will never be a P available to run the main goroutine.
This represents another potential danger of using nosplit functions: those that do not call preemptable functions must terminate promptly, or risk livelocking the whole runtime.
I use nosplit a lot, because I write high-performance, low-latency Go. This is a very insane thing to do, which has caused me to slowly generate bug reports whenever I hit strange corner cases.
For example, there are many cases where spill regions are allocated for functions that never use them, for example, functions which only call nosplit functions allocate space for them to spill their arguments, which they don’t do.3
This is a documented Go language feature which:
Isn’t very well-documented (the async preemption behavior certainly isn’t)!
Has very scary optimization-dependent build failures.
Can cause livelock and mysterious segfaults.
Can be used in user programs that don’t import "unsafe"!
And it makes code faster!
I’m surprised such a massive footgun exists at all, buuuut it’s a measureable benchmark improvement for me, so it’s impossible to tell if it’s bad or not.
The astute reader will observe that because preemption is not reentrant, only one of these spill regions will be in use at at time in a G. This is a known bug in the ABI, and is essentially a bodge to enable easy adoption of passing arguments by register, without needing all of the parts of the runtime that expect arguments to be spilled to the stack, as was the case in the slow old days when Go’s ABI on every platform was “i386-unknown-linux but worse”, i.e., arguments went on the stack and made the CPU’s store queue sad.
I recently filed a bug about this that boils down to “add a field to runtime.g to use a spill space”, which seems to me to be simpler than the alternatives described in the ABIInternal spec. ↩
Basically every bug report I write starts with these four words and it means you’re about to see the worst program ever written. ↩
The spill area is also used for spilling arguments across calls, but in this case, it is not necessary for the caller to allocate it for a nosplit function. ↩
You’d need a very specialized electron microscope to get down to the level to actually see a single strand of DNA. – Craig Venter
TL;DR: buf convert is a powerful tool for examining wire format dumps, by converting them to JSON and using existing JSON analysis tooling. protoscope can be used for lower-level analysis, such debugging messages that have been corrupted.
I’m editing a series of best practice pieces on Protobuf, a language that I work on which has lots of evil corner-cases.These are shorter than what I typically post here, but I think it fits with what you, dear reader, come to this blog for. These tips are also posted on the buf.build blog.
JSON’s human-readable syntax is a big reason why it’s so popular, possibly second only to built-in support in browsers and many languages. It’s easy to examine any JSON document using tools like online prettifiers and the inimitable jq.
But Protobuf is a binary format! This means that you can’t easily use jq -like tools with it…or can you?
The Buf CLI offers a utility for transcoding messages between the three Protobuf encoding formats: the wire format, JSON, and textproto; it also supports YAML. This is buf convert, and it’s very powerful.
To perform a conversion, we need four inputs:
A Protobuf source to get types out of. This can be a local .proto file, an encoded FileDescriptorSet , or a remote BSR module.
If not provided, but run in a directory that is within a local Buf module, that module will be used as the Protobuf type source.
The name of the top-level type for the message we want to transcode, via the --type flag.
The input message, via the --from flag.
A location to output to, via the --to flag.
buf convert supports input and output redirection, making it usable as part of a shell pipeline. For example, consider the following Protobuf code in our local Buf module:
Wait. That’s wrong. The answer should be 9. This illustrates one pitfall to keep in mind when using jq with Protobuf. Protobuf will sometimes serialize numbers as quoted strings (the C++ reference implementation only does this when they’re integers outside of the IEEE754 representable range, but Go is somewhat lazier, and does it for all 64-bit values).
jq ’s whole deal is JSON, so it brings with it all of JSON’s pitfalls. This is notable for Protobuf when trying to do arithmetic on 64-bit values. As we saw above, Protobuf serializes integers outside of the 64-bit float representable range (and in some runtimes, some integers inside it).
For example, if you have a repeated int64 that you want to sum over, it may produce incorrect answers due to floating-point rounding. For notes on conversions in jq, see https://jqlang.org/manual/#identity.
protoscope is a tool provided by the Protobuf team (which I originally wrote!) for decoding arbitrary data as if it were encoded in the Protobuf wire format. This process is called disassembly. It’s designed to work without a schema available, although it doesn’t produce especially clean output.
The field names are gone; only field numbers are shown. This example also reveals an especially glaring limitation of protoscope, which is that it can’t tell the difference between string and message fields, so it guesses according to some heuristics. For the first and third elements it was able to grok them as strings, but for orders[1].sku_name, it incorrectly guessed it was a message and produced garbage.
The tradeoff is that not only does protoscope not need a schema, it also tolerates almost any error, making it possible to analyze messages that have been partly corrupted. If we flip a random bit somewhere in orders[0], disassembling the message still succeeds:
Not only is the second order decoded correctly now, but protoscope shows the name of each field (via --print-field-names ). In this mode, protoscope still decodes partially-valid messages.
protoscope also provides a number of other flags for customizing its heuristic in the absence of a FileDescriporSet. This enables it to be used as a forensic tool for debugging messy data corruption bugs.
I’ve been very fortunate to dodge a nickname throughout my entire career. I’ve never had one. – Jimmie Johnson
TL;DR: Enum values can have aliases. This feature is poorly designed and shouldn’t be used. The ENUM_NO_ALLOW_ALIAS Buf lint rule prevents you from using them by default.
I’m editing a series of best practice pieces on Protobuf, a language that I work on which has lots of evil corner-cases.These are shorter than what I typically post here, but I think it fits with what you, dear reader, come to this blog for. These tips are also posted on the buf.build blog.
Protobuf permits multiple enum values to have the same number. Such enum values are said to be aliases of each other. Protobuf used to allow this by default, but now you have to set a special option, allow_alias, for the compiler to not reject it.
This can be used to effectively rename values without breaking existing code:
This works perfectly fine, and is fully wire-compatible! And unlike renaming a field (see TotW #1), it won’t result in source code breakages.
But if you use either reflection or JSON, or a runtime like Java that doesn’t cleanly allow enums with multiple names, you’ll be in for a nasty surprise.
For example, if you request an enum value from an enum using reflection, such as with protoreflect.EnumValueDescriptors.ByNumber(), the value you’ll get is the one that appears in the file lexically. In fact, both myapipb.MyEnum_MY_ENUM_BAD.String() and myapipb.MyEnum_MY_ENUM_MORE_SPECIFIC.String() return the same value, leading to potential confusion, as the old “bad” value will be used in printed output like logs.
You might think, “oh, I’ll switch the order of the aliases”. But that would be an actual wire format break. Not for the binary format, but for JSON. That’s because JSON preferentially stringifies enum values by using their declared name (if the value is in range). So, reordering the values means that what once serialized as {"my_field": "MY_ENUM_BAD"} now serializes as {"my_field": "MY_ENUM_MORE_SPECIFIC"} .
If an old binary that hasn’t had the new enum value added sees this JSON document, it won’t parse correctly, and you’ll be in for a bad time.
You can argue that this is a language bug, and it kind of is. Protobuf should include an equivalent of json_name for enum values, or mandate that JSON should serialize enum values with multiple names as a number, rather than an arbitrarily chosen enum name. The feature is intended to allow renaming of enum values, but unfortunately Protobuf hobbled it enough that it’s pretty dangerous.
Instead, if you really need to rename an enum value for usability or compliance reasons (ideally, not just aesthetics) you’re better off making a new enum type in a new version of your API. As long as the enum value numbers are the same, it’ll be binary-compatible, but it will somewhat reduce the risk of the above JSON confusion.
Buf provides a lint rule against this feature, ENUM_NO_ALLOW_ALIAS , and Protobuf requires that you specify a magic option to enable this behavior, so in practice you don’t need to worry about this. But remember, the consequences of enum aliases go much further than JSON—they affect anything that uses reflection. So even if you don’t use JSON, you can still get burned.
My dad had a guitar but it was acoustic, so I smashed a mirror and glued broken glass to it to make it look more metal. It looked ridiculous! –Max Cavalera
TL;DR: Avoid import public and import weak. The Buf lint rules IMPORT_NO_PUBLIC and IMPORT_NO_WEAK enforce this for you by default.
I’m editing a series of best practice pieces on Protobuf, a language that I work on which has lots of evil corner-cases.These are shorter than what I typically post here, but I think it fits with what you, dear reader, come to this blog for. These tips are also posted on the buf.build blog.
Protobuf imports allow you to specify two special modes: import public and import weak. The Buf CLI lints against these by default, but you might be tempted to try using them anyway, especially because some GCP APIs use import public. What are these modes, and why do they exist?
Importing a file dumps all of its symbols into the current file. For the purposes of name resolution, it’s as if all if the declarations in that file have been pasted into the current file. However, this isn’t transitive. If:
a.proto imports b.proto …
and b.proto imports c.proto …
and c.proto defines foo.Bar…
then, a.proto must import c.proto to refer to foo.Bar, even though b.proto imports it.
This is similar to how importing a package as . works in Go. When you write import . "strings", it dumps all of the declarations from the strings package into the current file, but not those of any files that "strings" imports.
Now, what’s nice about Go is that packages can be broken up into files in a way that is transparent to users; users of a package import the package, not the files of that package. Unfortunately, Protobuf is not like that, so the file structure of a package leaks to its callers.
import public was intended as a mechanism for allowing API writers to break up files that were getting out of control. You can define a new file new.proto for some of the definitions in big.proto, move them to the new file, and then add import public "new.proto"; to big.proto. Existing imports of big.proto won’t be broken, hooray!
Except this feature was designed for C++. In C++, each .proto file maps to a .proto.h header, which you #include in your application code. In C++, #include behaves like import public, so marking an import as public only changes name resolution in Protobuf—the C++ backend doesn’t have to do anything to maintain source compatibility when an import is changed to public.
But other backends, like Go, do not work this way: import in Go doesn’t pull in symbols transitively, so Go would need to explicitly add aliases for all of the symbols that come in through a public import. That is, if you had:
Then the Go backend has to generate a type Foo = foopb.Foo in bar.pb.go to emulate this behavior (in fact, I was surprised to learn Go Protobuf implements this at all). Go happens to implement public imports correctly, but not all backends are as careful, because this feature is obscure.
The spanner.proto example of an import public isn’t even used for breaking up an existing file; instead, it’s used to not make a huge file bigger and avoid making callers have to add an additional import. This is a bad use of a bad feature!
Using import public to effectively “hide” imports makes it harder to understand what a .proto file is pulling in. If Protobuf imports were at the package/symbol level, like Go or Java, this feature would not need to exist. Unfortunately, Protobuf is closely tailored for C++, and this is one of the consequences.
Instead of using import public to break up a file, simply plan to break up the file in the next version of the API.
The IMPORT_NO_PUBLIC Buf lint rule enforces that no one uses this feature by default. It’s tempting, but the footguns aren’t worth it.
Public imports have a good, if flawed, reason to exist. Their implementation details are the main thing that kneecaps them.
Weak imports, however, simply should not exist. They were added to the language to make it easier for some of Google’s enormous binaries to avoid running out of linker memory, by making it so that message types could be dropped if they weren’t accessed. This means that weak imports are “optional”—if the corresponding descriptors are missing at runtime, the C++ runtime can handle it gracefully.
This leads to all kinds of implementation complexity and subtle behavior differences across runtimes. Most runtimes implement (or implemented, in the case of those that removed support) import weak in a buggy or inconsistent way. It’s unlikely the feature will ever be truly removed, even though Google has tried.
Don’t use import weak. It should be treated as completely non-functional. The IMPORT_NO_WEAK Buf lint rule takes care of this for you.
Bad humor is an evasion of reality; good humor is an acceptance of it. –Malcolm Muggeridge
TL;DR: Protobuf’s distributed nature introduces evolution risks that make it hard to fix some types of mistakes. Sometimes the best thing to do is to just let it be.
I’m editing a series of best practice pieces on Protobuf, a language that I work on which has lots of evil corner-cases.These are shorter than what I typically post here, but I think it fits with what you, dear reader, come to this blog for. These tips are also posted on the buf.build blog.
Often, you’ll design and implement a feature for the software you work on, and despite your best efforts to test it, something terrible happens in production. We have a playbook for this, though: fix the bug in your program and ship or deploy the new, fixed version to your users. It might mean working late for big emergencies, but turnaround for most organizations is a day to a week.
Most bugs aren’t emergencies, though. Sometimes a function has a confusing name, or an integer type is just a bit too small for real-world data, or an API conflates “zero” and “null”. You fix the API, refactor all usages in your API in one commit, merge, and the fix rolls out gradually.
Unless, of course, it’s a bug in a communication API, like a serialization format: your Protobuf types, or your JSON schema, or the not-too-pretty code that parses fields out of dict built from a YAML file. Here, you can’t just atomically fix the world. Fixing bugs in your APIs (from here on, “APIs” means “Protobuf definitions”) requires a different mindset than fixing bugs in ordinary code.
Protobuf’s wire format is designed so that you can safely add new fields to a type, or values to an enum, without needing to perform an atomic upgrade. But other changes, like renaming fields or changing their type, are very dangerous.
This is because Protobuf types exist on a temporal axis: different versions of the same type exist simultaneously among programs in the field that are actively talking to each other. This means that writers from the future (that is, new serialization code) must be careful to not confuse the many readers from the past (old versions of the deserialization code). Conversely, future readers must tolerate anything past writers produce.
In a modern distributed deployment, the number of versions that exist at once can be quite large. This is true even in self-hosted clusters, but becomes much more fraught whenever user-upgradable software is involved. This can include mobile applications that talk to your servers, or appliance software managed by a third-party administrator, or even just browser-service communication.
The most important principle: you can’t easily control when old versions of a type or service are no longer relevant. As soon as a type escapes out of the scope of even a single team, upgrading types becomes a departmental effort.
There are many places where Protobuf could have made schema evolution easier, but didn’t. For example, changing int32 foo = 1; to sfixed32 foo = 1; is a breakage, even though at the wire format level, it is possible for a parser to distinguish and accept both forms of foo correctly. There too many other examples to list, but it’s important to understand that the language is not always working in our favor.
For example, if we notice a int32 value is too small, and should have been 64-bit, you can’t upgrade it without readers from the past potentially truncating it. But we really have to upgrade it! What are our options?
Issue a new version of the message and all of its dependencies. This is the main reason why sticking a version number in the package name, as enforced by Buf’s PACKAGE_VERSION_SUFFIX lint rule, is so important.
Do the upgrade anyway and hope nothing breaks. This can work for certain kinds of upgrades, if the underlying format is compatible, but it can have disastrous consequences if you don’t know what you’re doing, especially if it’s a type that’s not completely internal to a team’s project. Buf breaking change detection helps you avoid changes with potential for breakage.
Of course, there is a third option, which is to accept that some things aren’t worth fixing. When the cost of a fix is so high, fixes just aren’t worth it, especially when the language is working against us.
This means that even in Buf’s own APIs, we sometimes do things in a way that isn’t quite ideal, or is inconsistent with our own best practices. Sometimes, the ecosystem changes in a way that changes best practice, but we can’t upgrade to it without breaking our users. In the same way, you shouldn’t rush to use new, better language features if they would cause protocol breaks: sometimes, the right thing is to do nothing, because not breaking your users is more important.
Smart people learn from their mistakes. But the real sharp ones learn from the mistakes of others. –Brandon Mull
TL;DR: enums inherit some unfortunate behaviors from C++. Use the Buf lint rules ENUM_VALUE_PREFIX and ENUM_ZERO_VALUE_SUFFIX to avoid this problem (they’re part of the DEFAULT category).
I’m editing a series of best practice pieces on Protobuf, a language that I work on which has lots of evil corner-cases.These are shorter than what I typically post here, but I think it fits with what you, dear reader, come to this blog for. These tips are also posted on the buf.build blog.
Protobuf’s enums define data types that represent a small set of valid values. For example, google.rpc.Code lists status codes used by various RPC frameworks, such as GRPC. Under the hood, every enum is just an int32 on the wire, although codegen backends will generate custom types and constants for the enum to make it easier to use.
Unfortunately, enums were originally designed to match C++ enums exactly, and they inadvertently replicate many of those behaviors.
If you look at the source for google.rpc.Code, and compare it to, say, google.protobuf.FieldDescriptorProto.Type, you will notice a subtle difference:
packagegoogle.rpc;enumCode{OK=0;CANCELLED=1;UNKNOWN=2;// ...}packagegoogle.protobuf;messageFieldDescriptorProto{enumType{// 0 is reserved for errors.TYPE_DOUBLE=1;TYPE_FLOAT=2;TYPE_INT64=3;// ...}}
FieldDescriptorProto.Type has values starting with TYPE_, but Code ‘s values don’t have a CODE_ prefix. This is because the fully-qualified names (FQN) of an enum value don’t include the name of the enum. That is, TYPE_DOUBLE actually refers to google.protobuf.FieldDescriptorProto.TYPE_DOUBLE. Thus, OK is not google.rpc.Code.OK, but google.rpc.OK.
This is because it matches the behavior of unscoped C++ enums. C++ is the “reference” implementation, so the language often bends for the sake of the C++ backend.
When generating code, protoc’s C++ backend emits the above as follows:
And in C++, enums don’t scope their enumerators: you write google::rpc::OK, NOT google::rpc::Code::OK.
If you know C++, you might be thinking, “why didn’t they use enum class?!”? Enums were added in proto2, which was developed around 2007-2008, but Google didn’t start using C++11, which introduced enum class , until much, much later.
Now, if you’re a Go or Java programmer, you’re probably wondering why you even care about C++. Both Go and Java do scope enum values to the enum type (although Go does it in a somewhat grody way: rpcpb.Code_OK).
Unfortunately, this affects name collision detection in Protobuf. You can’t write the following code:
Because the enum name is not part of the FQN for an enum value, both UNSPECIFIEDs here have the FQN myapi.v1.UNSPECIFIED, so Protobuf complains about duplicate symbols.
Thus, the convention we see in FieldDescriptorProto.Type:
Buf provides a lint rule to enforce this convention: ENUM_VALUE_PREFIX. Even though you might think that an enum name will be unique, because top-level enums bleed their names into the containing package, the problem spreads across packages!
proto3 relies heavily on the concept of “zero values” – all non-message fields that are neither repeated nor optional are implicitly zero if they are not present. Thus, proto3 requires that enums specify a value equal to zero.
By convention, this value shouldn’t be a specific value of the enum, but rather a value representing that no value is specified. ENUM_ZERO_VALUE_SUFFIX enforces this, with a default of _UNSPECIFIED. Of course, there are situations where this might not make sense for you, and a suffix like _ZERO or _UNKNOWN might make more sense.
It may be tempting to have a specific “good default” value for the zero value. Beware though, because that choice is forever. Picking a generic “unknown” as the default reduces the chance you’ll burn yourself.
Name prefixes and zero values also teach us an important lesson: because Protobuf names are forever, it’s really hard to fix style mistakes, especially as we collectively get better at using Protobuf.
google.rpc.Code is intended to be source-compatible with very old existing C++ code, so it throws caution to the wind. FieldDescriptorProto.Type doesn’t have a zero value because in proto2 , which doesn’t have zero value footguns in its wire format, you don’t need to worry about that. The lesson isn’t just to use Buf’s linter to try to avoid some of the known pitfalls, but also to remember that even APIs designed by the authors of the language make unfixable mistakes, so unlike other programming languages, imitating “existing practice” isn’t always the best strategy.
It has very simple GC semantics that they’re mostly stuck with due to design decisions in the surface language.
These things mean that despite Go having a GC, it’s possible to do manual memory management in pure Go and in cooperation with the GC (although without any help from the runtime package). To demonstrate this, we will be building an untyped, garbage-collected arena abstraction in Go which relies on several GC implementation details.
I would never play this kind of game in Rust or C++, because LLVM is extremely intelligent and able to find all kinds of ways to break you over the course of frequent compiler upgrades. On the other hand, although Go does not promise any compatibility across versions for code that imports unsafe, in practice, two forces work against Go doing this:
Go does not attempt to define what is and isn’t allowed: unsafe lacks any operational semantics.
Go prioritizes not breaking the ecosystem; this allows to assume that Hyrum’s Law will protect certain observable behaviors of the runtime, from which we may infer what can or cannot break easily.
This is in contrast to a high-performance native compiler like LLVM, which has a carefully defined boundary around all UB, allowing them to arbitrarily break programs that cross it (mostly) without fear of breaking the ecosystem.
Our goal is to build an arena, which is a data structure for efficient allocation of memory that has the same lifetime. This reduces pressure on the general-purpose allocator by only requesting memory in large chunks and then freeing it all at once.
For a comparison in Go, consider the following program:
This program will print successive powers of 2: this is because append is implemented approximately like so:
funcappend[S~[]T,Tany](a,bS)S{// If needed, grow the allocation.ifcap(a)-len(a)<len(b){// Either double the size, or allocate just enough if doubling is// too little.newCap:=max(2*cap(a),len(a)+len(b))// Grow a.a2:=make([]T,len(a),newCap)copy(a2,a)a=a2}// Increase the length of a to fit b, then write b into the freshly// grown region.a=a[:len(a)+len(b)]copy(a[len(a)-len(b):],b)returna}
For appending small pieces, make is only called O(logn) times, a big improvement over calling it for every call to append. Virtually every programming language’s dynamic array abstraction makes this optimization.
An arena generalizes this concept, but instead of resizing exponentially, it allocates new blocks and vends pointers into them. The interface we want to conform to is as follows:
In go a size and and an alignment, out comes a pointer fresh memory with that layout. Go does not have user-visible uninitialized memory, so we additionally require that the returned region be zeroed. We also require that align be a power of two.
We can give this a type-safe interface by writing a generic New function:
// New allocates a fresh zero value of type T on the given allocator, and// returns a pointer to it.funcNew[Tany](aAllocator)*T{vartTp:=a.Alloc(unsafe.Sizeof(t),unsafe.Alignof(t))return(*T)(p)}
This all feels very fine and dandy to anyone used to hurting themselves with malloc or operator new in C++, but there is a small problem. What happens when we allocate pointer-typed memory into this allocator?
// Allocate a pointer in our custom allocator, and then// initialize it to a pointer on the Go heap.p:=New[*int](myAlloc)*p=new(int)runtime.GC()**p=42// Use after free!
Allocator.Alloc takes a size and an alignment, which is sufficient to describe the layout of any type. For example, on 64-bit systems, int and *int have the same layout: 8 bytes of size, and 8 bytes of alignment.
However, the Go GC (and all garbage collectors, generally) require one additional piece of information, which is somewhere between the layout of a value (how it is placed in memory) and the type of a value (rich information on its structure). To understand this, we need a brief overview on what a GC does.
For a complete overview on how to build a simple GC, take a look at a toy GC I designed some time ago: The Alkyne GC.
A garbage collector’s responsibility is to maintain a memory allocator and an accounting of:
What memory has been allocated.
Whether that memory is still in use.
Memory that is not in use can be reclaimed and marked as unallocated, for re-use.
The most popular way to accomplish this is via a “mark and sweep” architecture. The GC will periodically walk the entire object graph of the program from certain pre-determined roots; anything it finds is “marked” as alive. After a mark is complete, all other memory is “swept”, which means to mark it is unallocated for future re-use, or to return it to the OS, in the case of significant surplus.
The roots are typically entities that are actively being manipulated by the program. In the case of Go, this is anything currently on the stack of some G2, or anything in a global (of which there is a compile-time-known set).
The marking phase begins with stack scanning, which looks at the stack of each G and locates any pointers contained therein. The Go compiler generates metadata for each function that specifies which stack slots in a function’s frame contain pointers. All of these pointers are live by definition.
These pointers are placed into a queue, and each pointer is traced to its allocation on the heap. If the GC does not know anything about a particular address, it is discarded as foreign memory that does not need to be marked. If it does, each pointer in that allocation is pushed onto the queue if it has not already been marked as alive. The process continues until the queue is empty.
The critical step here is to take the address of some allocation, and convert it into all of the pointer values within. Go has precise garbage collection, which means that it only treats things declared as pointers in the surface language as pointers: an integer that happens to look like an address will not result in sweeping. This results in more efficient memory usage, but trades off some more complexity in the GC.
For example, the types *int, map[int]byte, string, struct {A int; B *int} all contain at least one pointer, while int, [1000]byte, struct {X bool; F uintptr} do not. The latter are called pointer-free types.
Go enhances the layout of a type into a shape by adding a bitset that specifies which pointer-aligned, pointer-sized words of the type’s memory region contain a pointer. These are called the pointer bits. For example, here are the shapes of a few Go types on a 64-bit system.
In the Go GC, each allocation is tagged with its shape (this is done in a variety of ways in the GC, either through an explicit header on the allocation, itself (a “malloc header”), a runtime type stored in the allocation’s runtime.mspan, or another mechanism). When scanning a value, it uses this information to determine where the pointers to scan through are.
The most obvious problem with our Allocator.Alloc type is that it does not discriminate shapes, so it cannot allocate memory that contains pointers: the GC will not be able to find the pointers, and will free them prematurely!
In our example where we allocated an *int in our custom allocator, we wind up with a **int on the stack. You would think that Go would simply trace through the first * to find an *int and mark it as being alive, but that is not what happens! Go instead finds a pointer into some chunk that the custom allocator grabbed from the heap, which is missing the pointer bits of its shape!
Why does go not look at the type of the pointer it steps through? Two reasons.
All pointers in Go are untyped from the runtime’s perspective; every *T gets erased into an unsafe.Pointer. This allows much of the Go runtime to be “generic” without using actual generics.
Pointee metadata can be aggregated, so that each pointer to an object does not have to remember its type at runtime.
The end result for us is that we can’t put pointers on the arena. This makes our New API unsafe, especially since Go does not provide a standard constraint for marking generic parameters as pointer-free: unsurprisingly, the don’t expect most users to care about such a detail.
It is possible to deduce the pointer bits of a type using reflection, but that’s very slow, and the whole point of using arenas is to go fast. As we design our arena, though, it will become clear that there is a safe way to have pointers on it.
Now that we have a pretty good understanding about what the Go GC is doing, we can go about designing a fast arena structure.
The ideal case is that a call to Alloc is very fast: just offsetting a pointer in the common case. One assumption we can make off the bat is that all memory can be forced to have maximum alignment: most objects are a pointer or larger, and Go does have a maximum alignment for ordinary user types, so we can just ignore the align parameter and always align to say, 8 bytes. This means that the pointer to the next unallocated chunk will always be well-aligned. Thus, we might come up with a structure like this one:
typeArenastruct{nextunsafe.Pointerleft,capuintptr}const(// Power of two size of the minimum allocation granularity.wordBytes=8// Depends on target, this is for 64-bit.minWords=8)func(a*Arena)Alloc(size,alignuintptr)unsafe.Pointer{// First, round the size up to the alignment of every object in// the arena.mask:=wordBytes-1size=(size+mask)&^mask// Then, replace the size with the size in pointer-sized words.// This does not result in any loss of size, since size is now// a multiple of the uintptr size.words:=size/wordBytes// Next, check if we have enough space left for this chunk. If// there isn't, we need to grow.ifa.left<words{// Pick whichever is largest: the minimum allocation size,// twice the last allocation, or the next power of two// after words.a.cap=max(minWords,a.cap*2,nextPow2(words))a.next=unsafe.Pointer(unsafe.SliceData(make([]uintptr,a.cap)))a.left=a.cap}// Allocate the chunk by incrementing the pointer.p:=a.nexta.left-=wordsifa.left>0{a.next=unsafe.Add(a.next,size)}else{// Beware, offsetting to one-past-the-end is one of the few// things explicitly not allowed by Go.a.next=nil}returnp}// nextPow2 returns the smallest power of two greater than n.funcnextPow2(nuintptr)uintptr{returnuintptr(1)<<bits.Len(uint(n))}
The focus of this benchmark is to measure the cost of allocating many objects of the same size. The number of times the for b.Loop() loop will execute is unknown, and determined by the benchmarking framework to try to reduce statistical anomaly. This means that if we instead just benchmark a single allocation, the result will be very sensitive to the number of runs.
We also use b.SetBytes to get a throughput measurement on the benchmark. This is a bit easier to interpret than the gross ns/op, the benchmark would otherwise produce. It tells us how much memory each allocator can allocate per unit time.
We want to compare against new, but just writing _ = new(T) will get optimized out, since the resulting pointer does not escape. Writing it to a global is sufficient to convince Go that it escapes.
Here’s the results, abbreviated to show only the bytes per second. All benchmarks were performed on my AMD Ryzen Threadripper 3960X. Larger is better.
This is quite nice, and certainly worth pursuing! The performance increase seems to scale up with the amount of memory allocated, for a 2x-4x improvement across different cases.
Now we need to contend with the fact that our implementation is completely broken if we want to have pointers in it.
In (*Arena).Alloc, when we assign a freshly-allocated chunk, we overwrite a.next, which means the GC can reclaim it. But this is fine: as long as pointers into that arena chunk are alive, the GC will not free it, independent of the arena. So it seems like we don’t need to worry about it?
However, the whole point of an arena is to allocate lots of memory that has the same lifetime. This is common for graph data structures, such as an AST or a compiler IR, which performs a lot of work that allocates a lot and then throws the result away.
We are not allowed to put pointers in the arena, because they would disappear from the view of the GC and become freed too soon. But, if a pointer wants to go on an arena, it necessarily outlive the whole arena, since it outlives part of the arena, and the arena is meant to have the same lifetime.
In particular, if we could make it so that holding any pointer returned by Alloc prevents the entire arena from being swept by the GC, the arena can safely contain pointers into itself! Consider this:
We have a pointer p **int. It is allocated on some arena a.
The GC sees our pointer (as a type-erased unsafe.Pointer) and marks its allocation as live.
Somehow, the GC also marks a as alive as a consequence.
Somehow, the GC then marks every chunk a has allocated as alive.
Therefore he chunk that *p points to is also alive, so *p does not need to be marked directly, and will not be freed early.
The step (3) is crucial. By forcing the whole arena to be marked, any pointers stored in the arena into itself will be kept alive automatically, without the GC needing to know how to scan for them.
So, even though *New[*int](a) = new(int) is still going to result in a use-after-free, *New[*int](a) = New[int](a) would not! This small improvement does not make arenas themselves safe, but a data structure with an internal arena can be completely safe, so long as the only pointers that go into the arena are from the arena itself.
How can we make this work? The easy part is (4), which we can implement by adding a []unsafe.Pointer to the arena, and sticking every pointer we allocate into it.
typeArenastruct{nextunsafe.Pointerleft,capuintptrchunks[]unsafe.Pointer// New field.}func(a*Arena)Alloc(size,alignuintptr)unsafe.Pointer{// ... snip ...ifa.left<words{// Pick whichever is largest: the minimum allocation size,// twice the last allocation, or the next power of two// after words.a.cap=max(minWords,a.cap*2,nextPow2(words))a.next=unsafe.Pointer(unsafe.SliceData(make([]uintptr,a.cap)))a.left=a.capa.chunks=append(a.chunks,a.next)}// ... snip ...}
The cost of the append is amortized: to allocate n bytes, we wind up allocating an additional O(loglogn) times. But what does this do to our benchmarks?
Now that the arena does not discard any allocated memory, we can focus on condition (3): making it so that if any pointer returned by Alloc is alive, then so is the whole arena.
Here we can make use of an important property of how Go’s GC works: any pointer into an allocation will keep it alive, as well as anything reachable from that pointer. But the chunks we’re allocating are []uintptrs, which will not be scanned. If there could somehow be a single pointer in this slice that was scanned, we would be able to stick the pointer a *Arena there, and so when anything that Alloc returns is scanned, it would cause a to be marked as alive.
So far, we have been allocating [N]uintptr using make([]T), but we would actually like to allocate struct { A [N]uintptr; P unsafe.Pointer }, where N is some dynamic value.
In its infintie wisdom, the Go standard library actually gives us a dedicated mechanism to do this: reflect.StructOf. This can be used to construct arbitrary anonymous struct types at runtime, which we can then allocate on the heap.
So, instead of calling make, we might call this function:
func(a*Arena)allocChunk(wordsuintptr)unsafe.Pointer{chunk:=reflect.New(reflect.StructOf([]reflect.StructField{{Name:"X0",Type:reflect.ArrayOf(int(words),reflect.TypeFor[uintptr]()),},{Name:"X1",Type:reflect.TypeFor[unsafe.Pointer]()},})).UnsafePointer()// Offset to the end of the chunk, and write a to it.end:=unsafe.Add(chunk,words*unsafe.Sizeof(uintptr(0)))*(**Arena)(end)=areturnchunk}
Looking back at Arena.Alloc, the end of this function has a branch:
func(a*Arena)Alloc(size,alignuintptr)unsafe.Pointer{// ... snip...// Allocate the chunk by incrementing the pointer.p:=a.nexta.left-=wordsifa.left>0{a.next=unsafe.Add(a.next,size)}else{// Beware, offsetting to one-past-the-end is one of the few// things explicitly not allowed by Go.a.next=nil}returnp}
This is the absolute hottest part of allocation, since it is executed every time we call this function. The branch is a bit unfortunate, but it’s necessary, as noted by the comment.
In C++, if we have an array of int with n elements in it, and int* p is a pointer to the start of the array, p + n is a valid pointer, even though it can’t be dereferenced; it points “one past the end” of the array. This is a useful construction, since, for example, you can use it to eliminate a loop induction variable:
// Naive for loop, has an induction variable i.for(inti=0;i<n;i++){do_something(p[i]);}// Faster: avoids the extra variable increment in the loop// body for doing p[i].for(autoend=p+n;p<end;p++){do_something(*p);}
Go, however, gets very upset if you do this, because it confuses the garbage collector. The GC can’t tell the difference between a one-past-the-end pointer for allocation A, and for the start of allocation B immediately after it. At best this causes memory to stay alive for longer, and at worst it triggers safety interlocks in the GC. The GC will panic if it happens to scan a pointer for an address that it knows has been freed.
But in our code above, every chunk now has an extra element at the very end that is not used for allocation, so we can have a pointer that is one-past-the-end of the [N]uintptr that we are vending memory from.
The updated allocation function would look like this:
func(a*Arena)Alloc(size,alignuintptr)unsafe.Pointer{// ... snip ...// Allocate the chunk by incrementing the pointer.p:=a.nexta.next=unsafe.Add(a.next,size)a.left-=wordsreturnp}
Notably, we do not replace a.left with an end pointer, because of the if a.left < words comparison. We can’t actually avoid the subtraction a.left -= words because we would have to do it to make this comparison work if we got rid of a.left.
Remarkably, not very! This is an improvement on the order of magnitude of one or two percentage points. This is because the branch we deleted is extremely predictable. Because Go’s codegen is relatively mediocre, the effect of highly predictable branches (assuming Go actually schedules the branches correctly 🙄) is quite minor.
Turns out there’s a bigger improvement we can make.
There’s a lot going on in this function, but most of it is a mix of Go not being great at register allocation, and lots of write barriers.
A write barrier is a mechanism for synchronizing ordinary user code with the GC. Go generates code for one any time a non-pointer-free type is stored. For example, writing to a **int, *string, or *[]int requires a write barrier.
Write barriers are implemented as follows:
runtime.writeBarrier is checked, which determines whether the write barrier is necessary, which is only when the GC is in the mark phase. Otherwise the branch is taken to skip the write barrier.
A call to one of the runtime.gcWriteBarrierN functions happens. N is the number of pointers that the GC needs to be informed of.
This function calls runtime.gcWriteBarrier, which returns a buffer onto which pointers the GC needs to now trace through should be written to.
The actual store happens.
A write barrier is required for a case like the following. Consider the following code.
This function will call runtime.newobject to allocate eight bytes of memory. The resulting pointer will be returned in rax. This function then stores rax into n and returns. If we Godbolt this function, we’ll find that it does, in fact, generate a write barrier:
TEXTx.allocCMPQSP,16(R14)JLSgrowStackPUSHQBPMOVQSP,BPSUBQ$16,SPMOVQAX,main.n+32(SP); new(int)LEAQtype:int(SB),AXCALLruntime.newobject(SB)MOVQmain.n+32(SP),CXTESTBAL,(CX); This is the write barrier.CMPLruntime.writeBarrier(SB),$0JEQskipMOVQ(CX),DXCALLruntime.gcWriteBarrier2(SB)MOVQAX,(R11)MOVQDX,8(R11)skip:MOVQAX,(CX); The actual store.ADDQ$16,SPPOPQBPRETgrowStack:NOPMOVQAX,8(SP)CALLruntime.morestack_noctxt(SB)MOVQ8(SP),AXJMPx.alloc
Note that two pointers get written: the pointer returned by new(int), and the old value of *n. This ensures that regardless of where in this function the GC happens to be scanning through *n, it sees both values during the mark phase.
Now, this isn’t necessary if the relevant pointers are already reachable in some other way… which is exactly the case in our arena (thanks to the chunks slice). So the write barrier in the fast path is redundant.
But, how do we get rid of it? There is //go:nowritebarrier, but that’s not allowed outside of a list of packages allowlisted in the compiler. It also doens’t disable write barriers; it simply generates a diagnostic if any are emitted.
But remember, write barriers only occur when storing pointer-typed memory… so we can just replace next unsafe.Pointer with next uintptr.
typeArenastruct{nextuintptr// A real pointer!left,capuintptrchunks[]unsafe.Pointer}func(a*Arena)Alloc(size,alignuintptr)unsafe.Pointer{mask:=wordBytes-1size=(size+mask)&^maskwords:=size/wordBytesifa.left<words{a.cap=max(minWords,a.cap*2,nextPow2(words))p:=a.allocChunk(a.cap)a.next=uintptr(p)a.left=a.capa.chunks=append(a.chunks,p)}p:=a.nexta.next+=sizea.left-=wordsreturnunsafe.Pointer(p)}
go vet hates this, because it doesn’t know that we’re smarter than it is. Does This make the code faster? To make it a little bit more realistic, I’ve written a separate variant of the benchmarks that hammers the GC really hard in a separate G:
The result indicates that this is a worthwhile optimization for churn-heavy contexts. Performance is much worse overall, but that’s because the GC is pre-empting everyone. The improvement seems to be on the order of 20% for very small allocations.
Another source of slowdown is the fact that any time we allocate from the heap, it’s forced to eagerly clear the huge allocated chunk every time, because it contains pointers. If you profile this code, a ton of time is spent in runtime.memclrNoHeapPointers. Because the chunks of memory we allocate are always of a specific size, we can use an array of sync.Pools to amortize the cost of allocating and clearing chunks.
First, we need an entry in this array of pools, one for each size of memory we allocate. Then, we need to set a finalizer on the arena to reclaim its memory once we’re done. Finally, we can change the contract of Alloc to require the caller to clear the value for us, and change New take a value as its argument:
What’s nice about this is that it avoids having to clear the value if a non-zero value would be allocated to it instead.
Putting this all together, it would look like this:
varpools[64]sync.Poolfuncinit(){fori:=rangepools{pools[i].New=func()any{returnreflect.New(reflect.StructOf([]reflect.StructField{{Name:"A",Type:reflect.ArrayOf(1<<i,reflect.TypeFor[uintptr]()),},{Name:"P",Type:reflect.TypeFor[unsafe.Pointer]()},})).UnsafePointer()}}}func(a*Arena)allocChunk(wordsuintptr)unsafe.Pointer{log:=bits.TrailingZeros(uint(words))chunk:=pools[log].Get().(unsafe.Pointer)// Offset to the end of the chunk, and write a to it.end:=unsafe.Add(chunk,words*unsafe.Sizeof(uintptr(0)))*(**Arena)(end)=a// If this is the first chunk allocated, set a finalizer.ifa.chunks==nil{runtime.SetFinalizer(a,(*Arena).finalize)}// Place the returned chunk at the offset in a.chunks that// corresponds to its log, so we can identify its size easily// in the loop above.a.chunks=append(a.chunks,make([]unsafe.Pointer,log+1-len(a.chunks))...)a.chunks[log]=chunkreturnchunk}func(a*Arena)finalize(){forlog,chunk:=rangea.chunks{ifchunk==nil{continue}words:=uintptr(1)<<logend:=unsafe.Add(chunk,words*unsafe.Sizeof(uintptr(0)))*(**Arena)(end)=nil// Make sure that we don't leak the arena.pools[log].Put(chunk)}}
Well. That’s a surprise. It does much better for small allocations, but it made really big allocations worse! It’s not immediately clear to me why this is, but note that new also got much faster, which tells me that because the allocations from the arena are longer-lived, the GC behaves somewhat differently, causing some of the cost from allocating really large things with new to be amortized.
Whether this optimization makes sense would require some profiling. An alternative is to manually manage arena re-use, by adding a very unsafe Reset() function that causes the arena to behave as if it was just constructed, but keeping all of its allocated chunks. This is analogous to reslicing to zero: x = x[:0].
This is very unsafe because it can lead to the same memory being allocated twice: this is only ok if the memory is not re-used.
Implementing this is very simple.
func(a*Arena)Reset(){a.next,a.left,a.cap=0,0,0}func(a*Arena)allocChunk(wordsuintptr)unsafe.Pointer{log:=bits.TrailingZeros(uint(words))iflen(a.chunks)>log{// If we've already allocated a chunk of this size in a previous arena// generation, return it.//// This relies on the fact that an arena never tries to allocate the same// size of chunk twice between calls to Reset().returna.chunks[log]}// ... snip ...}
That’s a massive improvement! There’s a couple of reasons this is faster. First, it doesn’t require waiting for the GC to collect old arenas to make their memory get reused. Second, the fast path is very fast with no synchronization.
On the flipside, this is very dangerous: arena re-use needs to be carefully managed, because you can wind up with unique pointers that aren’t.
Go does not offer an easy mechanism to “reallocate” an allocation, as with realloc() in C. This is because it has no mechanism for freeing pointers explicitly, which is necessary for a reallocation abstraction.
But we already don’t care about safety, so we can offer reallocation on our arena. Now, the reallocation we can offer is quite primitive: if a chunk happens to be the most recent one allocated, we can grow it. Otherwise we just allocate a new chunk and don’t free the old one.
This makes it possible to implement “arena slices” that can be constructed by appending, which will not trigger reallocation on slice growth as long as nothing else gets put on the arena.
Realloc would look something like this:
func(a*Arena)Realloc(ptrunsafe.Pointer,oldSize,newSize,alignuintptr,)unsafe.Pointer{mask:=wordBytes-1oldSize=(oldSize+mask)&^masknewSize=(newSize+mask)&^maskifnewSize<=oldSize{returnptr}// Check if this is the most recent allocation. If it is,// we can grow in-place.ifa.next-oldSize==uintptr(ptr){// Check if we have enough space available for the// requisite extra space.need:=(newSize-oldSize)/wordBytesifa.left>=need{// Grow in-place.a.left-=needreturnptr}}// Can't grow in place, allocate new memory and copy to it.new:=a.Alloc(newSize,align)copy(unsafe.Slice((*byte)(new),newSize),unsafe.Slice((*byte)(ptr),oldSize),)returnnew}
Then, whenever we append to our arena slice, we can call a.Realloc() to grow it. However, this does not work if the slice’s base pointer is not the original address returned by Alloc or Realloc. It is an exercise for the reader to:
Implement a Slice[T] type that uses an arena for allocation.
Make this work for any value of ptr within the most recent allocation, not just the base offset. This requires extra book-keeping.
Here is the entirety of the code that we have developed, not including the reallocation function above.
packagearenaimport("math/bits""reflect""unsafe")funcNew[Tany](a*Arena,vT)*T{p:=(*T)(a.Alloc(unsafe.Sizeof(v),unsafe.Alignof(v)))*p=vreturnp}typeArenastruct{nextunsafe.Pointerleft,capuintptrchunks[]unsafe.Pointer}const(maxAlignuintptr=8// Depends on target, this is for 64-bit.minWordsuintptr=8)func(a*Arena)Alloc(size,alignuintptr)unsafe.Pointer{// First, round the size up to the alignment of every object in the arena.mask:=maxAlign-1size=(size+mask)&^mask// Then, replace the size with the size in pointer-sized words. This does not// result in any loss of size, since size is now a multiple of the uintptr// size.words:=size/maxAlign// Next, check if we have enough space left for this chunk. If there isn't,// we need to grow.ifa.left<words{// Pick whichever is largest: the minimum allocation size, twice the last// allocation, or the next power of two after words.a.cap=max(minWords,a.cap*2,nextPow2(words))a.next=a.allocChunk(a.cap)a.left=a.capa.chunks=append(a.chunks,a.next)}// Allocate the chunk by incrementing the pointer.p:=a.nexta.next=unsafe.Add(a.next,size)a.left-=wordsreturnp}func(a*Arena)Reset(){a.next,a.left,a.cap=0,0,0}varpools[64]sync.Poolfuncinit(){fori:=rangepools{pools[i].New=func()any{returnreflect.New(reflect.StructOf([]reflect.StructField{{Name:"X0",Type:reflect.ArrayOf(1<<i,reflect.TypeFor[uintptr]()),},{Name:"X1",Type:reflect.TypeFor[unsafe.Pointer]()},})).UnsafePointer()}}}func(a*Arena)allocChunk(wordsuintptr)unsafe.Pointer{log:=bits.TrailingZeros(uint(words))iflen(a.chunks)>log{returna.chunks[log]}chunk:=pools[log].Get().(unsafe.Pointer)// Offset to the end of the chunk, and write a to it.end:=unsafe.Add(chunk,words*unsafe.Sizeof(uintptr(0)))*(**Arena)(end)=a// If this is the first chunk allocated, set a finalizer.ifa.chunks==nil{runtime.SetFinalizer(a,(*Arena).finalize)}// Place the returned chunk at the offset in a.chunks that// corresponds to its log, so we can identify its size easily// in the loop above.a.chunks=append(a.chunks,make([]unsafe.Pointer,log+1-len(a.chunks))...)a.chunks[log]=chunkreturnchunk}func(a*Arena)finalize(){forlog,chunk:=rangea.chunks{ifchunk==nil{continue}words:=uintptr(1)<<logend:=unsafe.Add(chunk,words*unsafe.Sizeof(uintptr(0)))*(**Arena)(end)=nil// Make sure that we don't leak the arena.pools[log].Put(chunk)}}funcnextPow2(nuintptr)uintptr{returnuintptr(1)<<bits.Len(uint(n))}
There are other optimizations that we could make here that I haven’t discussed. For example, arenas could be re-used; once an arena is done, it could be “reset” and placed into a sync.Pool. This arena would not need to go into the GC to request new chunks, re-using the ones previously allocated (and potentially saving on the cost of zeroing memory over and over again).
I did say that this relies very heavily on Go’s internal implementation details. Whats the odds that they get broken in the future? Well, the requirement that allocations know their shape is forced by the existence of unsafe.Pointer, and the requirement that a pointer into any part of an allocation keeps the whole thing alive essentially comes from slices being both sliceable and mutable; once a slice escapes to the heap (and thus multiple goroutines) coordinating copies for shrinking a slice would require much more complexity than the current write barrier implementation.
And in my opinion, it’s pretty safe to say that Hyrum’s Law has us covered here. ;)
Go does have some UB. For example, Go assumes that a G’s stack is never read or written to by any other G, except by the GC across a write barrier.
That said, what UB does exist is very, very difficult to trip on purpose. ↩
The pointer bits are in big endian order, so the first bit in left-to-right order corresponds to the first word. ↩
The “itab”, or interface table part of an interface value is not managed by the GC; it is allocated in persistent memory, so even though it is a pointer, it is not a pointer the GC needs to care about. ↩
This can be made better by caching the reflect.Types, but that is only a very slight improvement on the order of 1% speedup. Most of the slowdown is because Go is a bit more eager about zeroing allocations of values that contain pointers.
vartypes[]reflect.Typefuncinit(){// Pre-allocate the whole array. There aren't that many powers// of two. Don't need to go beyond 1<<61, since that's about as// large of an allocation as Go will service (trying to create// a larger array will panic).types=make([]reflect.Type,61)fori:=rangetypes{types[i]=reflect.StructOf([]reflect.StructField{{Name:"X0",Type:reflect.ArrayOf(int(1)<<i,reflect.TypeFor[uintptr]()),},{Name:"X1",Type:reflect.TypeFor[unsafe.Pointer]()},})}}func(a*Arena)allocChunk(wordsuintptr)unsafe.Pointer{log:=bits.TrailingZeros(uint(words))chunk:=reflect.New(types[log]).UnsafePointer()// Offset to the end of the chunk, and write a to it.end:=unsafe.Add(chunk,words*unsafe.Sizeof(uintptr(0)))*(**Arena)(end)=areturnchunk}
However, with this in place, we can be assured that property (3) now holds, so it’s perfectly safe to place arena pointers into arena-allocated memory, so long as it’s across the same arena. ↩
As a matter of fact, when compression technology came along, we thought the future in 1996 was about voice. We got it wrong. It is about voice, video, and data, and that is what we have today on these cell phones. –Steve Buyer
TL;DR: Compression is everywhere: CDNs, HTTP servers, even in RPC frameworks like Connect. This pervasiveness means that wire size tradeoffs matter less than they used to twenty years ago, when Protobuf was designed.
I’m editing a series of best practice pieces on Protobuf, a language that I work on which has lots of evil corner-cases.These are shorter than what I typically post here, but I think it fits with what you, dear reader, come to this blog for. These tips are also posted on the buf.build blog.
Protobuf’s wire format is intended to be relatively small. It makes use of variable-width integers so that smaller values take up less space on the wire. Fixed width integers might be larger on the wire, but often have faster decoding times.
But what if I told you that doesn’t matter?
See, most internet traffic is compressed. Bandwidth is precious, and CDN operators don’t want to waste time sending big blobs full of zeros. There are many compression algorithms available, but the state of the art for HTTP requests (which dominates much of global internet traffic) is Brotli, an algorithm developed at Google in 2013 and standardized in IETF RFC7932 in 2016. There is a very good chance that this article was delivered to your web browser as a Brotli-compressed blob.
How compression is applied in your case will vary, but both Connect RPC and gRPC support native compression. For example, Connect has an API for injecting compression providers: https://pkg.go.dev/connectrpc.com/connect#WithCompression.
Connect uses gzip by default, which uses the DEFLATE compression algorithm. Providing your own compression algorithm (such as Brotli) is pretty simple, as shown by this third-party package.
Other services may compress for you transparently. Any competent CDN will likely use Brotli (or gzip or zlib, but probably Brotli) to compress any files it serves for you. (In fact, JavaScript and HTML minimization can often be rendered irrelevant by HTTP compression, too.)
It’s important to remember that Protobuf predates pervasive compression: if it didn’t, it would almost certainly not use variable-width integers for anything. It only uses them because they offer a primitive form of compression in exchange for being slower to decode. If that tradeoff was eliminated, Protobuf would almost certainly only use fixed-width integers on the wire.
There are two fields that contain essentially the same data, which can be encoded in four different ways: as old-style repeated fields, as packed fields, and the integers can be encoded as varints or fixed32 values.
Using Protoscope, we can create some data that exercises these four cases:
Each blob contains the integers from 1 to 1000 encoded in different ways. I’ll compress each one using gzip, zlib, and Brotli, using their default compression levels, and arrange their sizes, in bytes, in the table below.
File
Uncompressed
gzip (DEFLATE)
zlib
Brotli
a.pb
2875
1899
1878
1094
b.pb
1877
1534
1524
885
c.pb
5005
1577
1567
1140
d.pb
4007
1440
1916
1140
Compression achieves incredible results: Brotli manages to get all of the files down to around 1.1 kB, except for the packed varints, which it gets about 250 bytes smaller! Of course, that’s only because most of the values in that repeated field are small. If the values range from 100000 to 101000, b.pb and d.pb are 3006 and 4007 bytes respectively (see that d.pb’s size is unchanged!), but when compressed with brotli, the lead for b.pb starts to disappear: 1039 bytes vs. 1163 bytes. Now it’s only 120 bytes smaller.
Applying compression can often have similar results to replacing everything with varints, but not exactly: using a varint will likely always be slightly smaller, at least when using state-of-the-art compression like Brotli. But you can pretty much always assume you will be using compression, such as to compress HTTP headers and other ancillary content in your request. Compression is generic and highly optimized—it applies to all data, regardless of schema, and is often far more optimized than application-level codecs like those in a Protobuf library.
Not to mention, you should definitely be compressing any large data blobs you’re storing on disk, too!
As a result, you can usually disregard many encoded size concerns when making tradeoffs in designing a Protobuf type. Fixed integer types will decode faster, so if decoding speed is important to you, and you’re worried about the size on the wire, don’t. It’s almost certainly already taken care of at a different layer of the stack.
Cross-compiling is taking a computer program and compiling it for a machine that isn’t the one hosting the compilation. Although historically compilers would only compile for the host machine, this is considered an anachronism: all serious native compilers are now cross-compilers.
After all, you don’t want to be building your iPhone app on literal iPhone hardware.
Many different compilers have different mechanisms for classifying and identifying targets. A target is a platform that the compiler can produce executable code for. However, due to the runaway popularity of LLVM, virtually all compilers now use target triples. You may have already encountered one, such as the venerable x86_64-unknown-linux, or the evil x86_64-pc-windows. This system is convoluted and almost self-consistent.
But what is a target triple, and where did they come from?
So if you go poking around the Target Triplet page on OSDev, you will learn both true and false things about target triples, because this page is about GCC, not native compilers in general.
Generally, there is no “ground truth” for what a target triple is. There isn’t some standards body that assigns these names. But as we’ll see, LLVM is the trendsetter.
If you run the following command you can learn the target triple for your machine:
Now if you’re at all familiar with any system that makes pervasive use of target triples, you will know that this is not a target triple, because this target’s name is x86_64-unknown-linux-gnu, which is what both clang and rustc call-
Well, GCC is missing the the pc or unknown component, and that’s specifically a GCC thing; it allows omitting parts of the triple in such a way that is unambiguous. And they are a GCC invention, so perhaps it’s best to start by assessing GCC’s beliefs.
According to GCC, a target triple is a string of the form <machine>-<vendor>-<os>. The “machine” part unambiguously identifies the architecture of the system. Practically speaking, this is the assembly language that the compiler will output at the end. The “vendor” part is essentially irrelevant, and mostly is of benefit for sorting related operating systems together. Finally, the “os” part identifies the operating system that this code is being compiled for. The main thing this identifies for a compiler is the executable format: COFF/PE for Windows, Mach-O for Apple’s operating systems, ELF for Linux and friends, and so on (this, however, is an oversimplification).
But you may notice that x86_64-unknown-linux-gnu has an extra, fourth entry1, which plays many roles but is most often called the target’s “ABI”. For linux, it identifies the target’s libc, which has consequences for code generation of some language features, such as thread locals and unwinding. It is optional, since many targets only have one ABI.
A critical piece of history here is to understand the really stupid way in which GCC does cross compiling. Traditionally, each GCC binary would be built for one target triple. The full name of a GCC binary would include the triple, so when cross-compiling, you would compile with x86_64-unknown-linux-gcc, link with x86_64-unknown-linux-ld, and so on (here, gcc is not the fourth ABI component of a triple; it’s just one of the tools in the x86_64-unknown-linux toolchain).
Nobody with a brain does this2. LLVM and all cross compilers that follow it instead put all of the backends in one binary, and use a compiler flag like --target to select the backend.
But regardless, this is where target triples come from, and why they look the way they look: they began as prefixes for the names of binaries in autoconf scripts.
But GCC is ancient technology. In the 21st century, LLVM rules all native compilers.
LLVM’s target triple list is the one that should be regarded as “most official”, for a few reasons:
Inertia. Everyone and their mother uses LLVM as a middleend and backend, so its naming conventions bubble up into language frontends like clang, rustcswiftc, icc, and nvcc.
Upstream work by silicon and operating system vendors. LLVM is what people get hired to work on for the most part, not GCC, so its platform-specific conventions often reflect the preferences of vendors.
These are in no small part because Apple, Google, and Nvidia have armies of compiler engineers contributing to LLVM.
The sources for “official” target triples are many. Generally, I would describe a target triple as “official” when:
A major compiler (so, clang or rustc) uses it. Rust does a way better job than LLVM of documenting their targets, so I prefer to give it deference. You can find Rust’s official triples here.
A platform developer (e.g., a hardware manufacturer, OS vendor) distributes a toolchain with a target triple in the arch-vendor-os format.
So, what are the names in class (1)? LLVM does not really go out of its way to provide such a list. But we gotta start somewhere, so source-diving it is.
We can dig into Triple.cpp in LLVM’s target triple parser. It lists all of the names LLVM recognizes for each part of a triple. Looking at Triple::parseArch(), we have the following names, including many, many aliases. The first item on the right column is LLVM’s preferred name for the architecture, as indicated by Triple::getArchTypeName().
Here we begin to see that target triples are not a neat system. They are hell. Where a list of architecture names contains a “…”, it means that LLVM accepts many more names.
The problem is that architectures often have versions and features, which subtly change how the compiler generates code. For example, when compiling for an x86_64, we may want to specify that we want AVX512 instructions to be used. On LLVM, you might do that with -mattr=+avx512. Every architecture has a subtly-different way of doing this, because every architecture had a different GCC! Each variant of GCC would put different things behind -mXXX flags (-m for “machine”), meaning that the interface is not actually that uniform. The meanings of -march, -mcpu, -mtune, and -mattr thus vary wildly for this reason.
Because LLVM is supposed to replace GCC (for the most part), it replicates a lot of this wacky behavior.
So uh, we gotta talk about 32-bit ARM architecture names.
There is a hellish file in LLVM dedicated to parsing ARM architecture names. Although members of the ARM family have many configurable features (which you can discover with llc -march aarch64 -mattr help10), the name of the architecture is somewhat meaningful, and can hav many options, mostly relating to the many versions of ARM that exist.
How bad is it? Well, we can look at all of the various ARM targets that rustc supports with rustc --print target-list:
Most of these are 32-bit ARM versions, with profile information attached. These correspond to the names given here. Why does ARM stick version numbers in the architecture name, instead of using -mcpu like you would on x86 (e.g. -mcpu alderlake)? I have no idea, because ARM is not my strong suit. It’s likely because of how early ARM support was added to GCC.
Internally, LLVM calls these “subarchitectures”, although ARM gets special handling because there’s so many variants. SPIR-V, Direct X, and MIPS all have subarchitectures, so you might see something like dxilv1.7 if you’re having a bad day.
Of course, LLVM’s ARM support also sports some naughty subarchitectures not part of this system, with naughty made up names.
arm64e is an Apple thing, which is an enhancement of aarch64 present on some Apple hardware, which adds their own flavor of pointer authentication and some other features.
arm64ec is a completely unrelated Microsoft invention that is essentially “aarch64 but with an x86_64-ey ABI” to make x86_64 emulation on what would otherwise be aarch64-pc-windows-msvc target somewhat more amenable.
Why the Windows people invented a whole other ABI instead of making things clean and simple like Apple did with Rosetta on ARM MacBooks? I have no idea, but http://www.emulators.com/docs/abc_arm64ec_explained.htm contains various excuses, none of which I am impressed by. My read is that their compiler org was just worse at life than Apple’s, which is not surprising, since Apple does compilers better than anyone else in the business.
Actually, since we’re on the topic of the names of architectures, I have a few things I need to straighten out.
x86 and ARM both seem to attract a lot of people making up nicknames for them, which leads to a lot of confusion in:
What the “real” name is.
What name a particular toolchain wants.
What name you should use in your own cosmopolitan tooling.
Let’s talk about the incorrect names people like to make up for them. Please consider the following a relatively normative reference on what people call these architectures, based on my own experience with many tools.
When we say “x86” unqualified, in 2025, we almost always mean x86_64, because 32-bit x86 is dead. If you need to talk about 32-bit x86, you should either say “32-bit x86”, “protected mode”11, or “i386” (the first Intel microarchitecture that implemented protected mode)12. You should not call it x86_32 or just x86.
You might also call it IA-32 for Intel Architecture 32, (or ia32), but nobody calls it that and you risk confusing people with ia64, or IA-64, the official name of Intel’s failed general-purpose VLIW architecture, Itanium, which is in no way compatible with x86. ia64 was what GCC and LLVM named Itanium triples with. Itanium support was drowned in a bathtub during the Obama administration, so it’s not really relevant anymore. Rust has never had official Itanium support.
32-bit x86 is extremely not called “x32”; this is what Linux used to call its x86 ILP324 variant before it was removed (which, following the ARM names, would have been called x86_6432).
There are also many ficticious names for 64-bit x86, which you should avoid unless you want the younger generation to make fun of you. amd64 refers to AMD’s original implementation of long mode in their K8 microarchitecture, first shipped in their Athlon 64 product. AMD still makes the best x86 chips (I am writing this on a machine socketed with a Zen2 Threadripper), sure, but calling it amd64 is silly and also looks a lot like arm64, and I am honestly kinda annoyed at how much Go code I’ve seen with files named fast_arm64.s and fast_amd64.s. Debian also uses amd64/arm64, which makes browsing packages kind of annoying.
On that topic, you should absolutely not call 64-bit mode k8, after the AMD K8. Nobody except for weird computer taxonomists like me know what that is. But Bazel calls it that, and it’s really irritating13.
You should also not call it x64. Although LLVM does accept amd64 for historical purposes, no one calls it x64 except for Microsoft. And even though it is fairly prevalent on Windows, I absolutely give my gamedev friends a hard time when they write x64.
On the ARM side, well. Arm14 has a bad habit of not using consistent naming for 64-bit ARM, since they used both AArch64 and ARM64 for it. However, in compiler land, aarch64 appears to be somewhat more popular.
You should also probably stick to the LLVM names for the various architectures, instead of picking your favorite Arm Cortex name (like cortex_m0).
The worst is over. Let’s now move onto examinining the rest of the triple: the platform vendor, and the operating system.
The vendor is intended to identify who is responsible for the ABI definition for that target. Although provides little to no value to the compiler itself, but it does help to sort related targets together. Sort of.
Returning to llvm::Triple, we can examine Triple::VendorType. Vendors almost always correspond to companies which develop operating systems or other platforms that code runs on, with some exceptions.
We can also get the vendors that rustc knows about with a handy dandy command:
Most vendors are the names of organizations that produce hardware or operating systems. For example suse and redhat are used for those organizations’ Linux distributions, as a funny branding thing. Some vendors are projects, like the mesa vendor used with the Mesa3D OpenGL implementation’s triples.
The unknown vendor is used for cases where the vendor is not specified or just not important. For example, the canonical Linux triple is x86_64-unknown-linux… although one could argue it should be x86_64-torvalds-linux. It is not uncommon for companies that sell/distribute Linux distributions to have their own target triples, as do SUSE and sometimes RedHat. Notably, there are no triples with a google vendor, even though aarch64-linux-android and aarch64-unknown-fuchsia should really be called aarch64-google-linux-android and aarch64-google-fuchsia. The target triple system begins to show cracks here.
The pc vendor is a bit weirder, and is mostly used by Windows targets. The standard Windows target is x86_64-pc-windows-msvc, but really it should have been x86_64-microsoft-windows-msvc. This is likely complicated by the fact that there is also a x86_64-pc-windows-gnu triple, which is for MinGW code. This platform, despite running on Windows, is not provided by Microsoft, so it would probably make more sense to be called x86_64-unknown-windows-gnu.
But not all Windows targets are pc! UWP apps use a different triple, that replaces the pc with uwp. rustc provides targets for Windows 7 backports that use a win7 “vendor”.
The third (or sometimes second, ugh) component of a triple is the operating system, or just “system”, since it’s much more general than that. The main thing that compilers get from this component relates to generating code to interact with the operating system (e.g. SEH on Windows) and various details related to linking, such as object file format and relocations.
It’s also used for setting defines like __linux__ in C, which user code can use to determine what to do based on the target.
We’ve seen linux and windows, but you may have also seen x86_64-apple-darwin. Darwin?
The operating system formerly known as Mac OS X (now macOS16) is a POSIX operating system. The POSIX substrate that all the Apple-specific things are built on top of is called Darwin. Darwin is a free and open source operating system based on Mach, a research kernel whose name survives in Mach-O, the object file format used by all Apple products.
All of the little doodads Apple sells use the actual official names of their OSes, like aarch64-apple-ios. For, you know, iOS. On your iPhone. Built with Xcode on your iMac.
none is a common value for this entry, which usually means a free-standing environment with no operating system. The object file format is usually specified in the fourth entry of the triple, so you might see something like riscv32imc-unknown-none-elf.
Sometimes the triple refers not to an operating system, but to a complete hardware product. This is common with game console triples, which have “operating system” names like ps4, psvita, 3ds, and switch. (Both Sony and Nintendo use LLVM as the basis for their internal toolchains; the Xbox toolchain is just MSVC).
The fourth entry of the triple (and I repeat myself, yes, it’s still a triple) represents the binary interface for the target, when it is ambiguous.
For example, Apple targets never have this, because on an Apple platform, you just shut up and use CoreFoundation.framework as your libc. Except this isn’t true, because of things like x86_64-apple-ios-sim, the iOS simulator running on an x86 host.
On the other hand, Windows targets will usually specify -msvc or -gnu, to indicate whether they are built to match MSVC’s ABI or MinGW. Linux targets will usually specify the libc vendor in this position: -gnu for glibc, -musl for musl, -newlib for newlib, and so on.
This doesn’t just influence the calling convention; it also influences how language features, such as thread locals and dynamic linking, are handled. This usually requires coordination with the target libc.
On ARM free-standing (armxxx-unknown-none) targets, -eabi specifies the ARM EABI, which is a standard embeded ABI for ARM. -eabihf is similar, but indicates that no soft float support is necessary (hf stands for hardfloat). (Note that Rust does not include a vendor with these architectures, so they’re more like armv7r-none-eabi).
A lot of jankier targets use the ABI portion to specify the object file, such as the aforementioned riscv32imc-unknown-none-elf.
One last thing to note are the various WebAssembly targets, which completely ignore all of the above conventions. Their triples often only have two components (they are still called triples, hopefully I’ve made that clear by now). Rust is a little bit more on the forefront here than clang (and anyways I don’t want to get into Emscripten) so I’ll stick to what’s going on in rustc.
There’s a few variants. wasm32-unknown-unknown (here using unknown instead of none as the system, oops) is a completely bare WebAssebly runtime where none of the standard library that needs to interact with the outside world works. This is essentially for building WebAssembly modules to deploy in a browser.
There are also the WASI targets, which provide a standard ABI for talking to the host operating system. These are less meant for browsers and more for people who are using WASI as a security boundary. These have names like wasm32-wasip1, which, unusually, lack a vendor! A “more correct” formulation would have been wasm32-unknown-wasip1.
Go does the correct thing and distributes a cross compiler. This is well and good.
Unfortunately, they decided to be different and special and do not use the target triple system for naming their targets. Instead, you set the GOARCH and GOOS environment variables before invoking gc. This will sometimes be shown printed with a slash between, such as linux/amd64.
Thankfully, they at least provide documentation for a relevant internal package here, which offers the names of various GOARCH and GOOS values.
They use completely different names from everyone else for a few things, which is guaranteed to trip you up. They use call the 32- and 64-bit variants of x86 386 (note the lack of leading i) and amd64. They call 64-bit ARM arm64, instead of aarch64. They call little-endian MIPSes mipsle instead of mipsel.
They also call 32-bit WebAssembly wasm instead of wasm32, which is a bit silly, and they use js/wasm as their equivalent of wasm32-unknown-unknown, which is very silly.
Android is treated as its own operating system, android, rather than being linux with a particular ABI; their system also can’t account for ABI variants in general, since Go originally wanted to not have to link any system libraries, something that does not actually work.
If you are building a new toolchain, don’t be clever by inventing a cute target triple convention. All you’ll do is annoy people who need to work with a lot of different toolchains by being different and special.
Realistically, you probably shouldn’t. But if you must, you should probably figure out what you want out of the triple.
Odds are there isn’t anything interesting to put in the vendor field, so you will avoid people a lot of pain by picking unknown. Just include a vendor to avoid pain for people in the future.
You should also avoid inventing a new name for an existing architecture. Don’t name your hobby operating system’s triple amd64-unknown-whatever, please. And you definitely don’t want to have an ABI component. One ABI is enough.
If you’re inventing a triple for a free-standing environment, but want to specify something about the hardware configuration, you’re probably gonna want to use -none-<abi> for your system. For some firmware use-cases, though, the system entry is a better place, such as for the UEFI triples. Although, I have unforunately seen both x86_64-unknown-uefi and x86_64-pc-none-uefi in the wild.
And most imporantly: this sytem was built up organically. Disabuse yourself now of the idea that the system is consistent and that target triples are easy to parse. Trying to parse them will make you very sad.
And no, a “target quadruple” is not a thing and if I catch you saying that I’m gonna bonk you with an Intel optimization manual. ↩
I’m not sure why GCC does this. I suspect that it’s because computer hard drives used to be small and a GCC with every target would have been too large to cram into every machine. Maybe it has some UNIX philosophy woo mixed into it.
Regardless, it’s really annoying and thankfully no one else does this because cross compiling shouldn’t require hunting down a new toolchain for each platform. ↩
This is for Apple’s later-gen x86 machines, before they went all-in on ARM desktop. ↩
ILP32 means that the int, long, and pointer types in C are 32-bit, despite the architecture being 64-bit. This allows writing programs that are small enough top jive in a 32-bit address space, while taking advantage of fast 64-bit operations. It is a bit of a frankentarget. Also existed once as a process mode on x86_64-unknown-linux by the name of x32. ↩↩2
Not to be confused with POWER, an older IBM CPU. ↩
No idea what this is, and Google won’t help me. ↩↩2
llc is the LLVM compiler, which takes LLVM IR as its input. Its interface is much more regular than clang’s because it’s not intended to be a substitute for GCC the way clang is. ↩
Very kernel-hacker-brained name. It references the three processor modes of an x86 machine: real mode, protected mode, long mode, which correspond to 16-, 32-, and 64-bit modes. There is also a secret fourth mode called unreal mode, which is just what happens when you come down to real mode from protected mode after setting up a protected mode GDT.
If you need to refer to real mode, call it “real mode”. Don’t try to be clever by calling it “8086” because you are almost certainly going to be using features that were not in the original Intel 8086. ↩
I actually don’t like this name, but it’s the one LLVM uses so I don’t really get to complain. ↩
Bazel also calls 32-bit x86 piii, which stands for, you guessed it, “Pentium III”. Extremely unserious. ↩
The intelectual property around ARM, the architecture famility, is owned by the British company Arm Holdings. Yes, the spelling difference is significant.
Relatedly, ARM is not an acronym, and is sometimes styled in all-lowercase as arm. The distant predecesor of Arm Holdings is Acorn Computers. Their first compute, the Acorn Archimedes, contained a chip whose target triple name today might have been armv1. Here, ARM was an acronym, for Acorn RISC Machine. Wikipedia alleges without citation that the name was at once point changed to Advanced RISC Machine at the behest of Apple, but I am unable to find more details. ↩
“You are not cool enough for your company to be on the list.” ↩
Which I pronounce as one word, “macos”, to drive people crazy. ↩
I wake up every morning and grab the morning paper. Then I look at the obituary page. If my name is not on it, I get up. –Ben Franklin
TL;DR: Don’t rename fields. Even though there are a slim number of cases where you can get away with it, it’s rarely worth doing, and is a potential source of bugs.
I’m editing a series of best practice pieces on Protobuf, a language that I work on which has lots of evil corner-cases.These are shorter than what I typically post here, but I think it fits with what you, dear reader, come to this blog for. These tips are also posted on the buf.build blog.
Protobuf message fields have field tags that are used in the binary wire format to discriminate fields. This means that the wire format serialization does not actually depend on the names of the fields. For example, the following messages will use the exact same serialization format.
In fact, the designers of Protobuf intended for it to be feasible to rename an in-use field. However, they were not successful: it can still be a breaking change.
If your schema is public, the generated code will change. For example, renaming a field from first_name to given_name will cause the corresponding Go accessor to change from FirstName to GivenName, potentially breaking downstream consumers.
Renaming a field to a “better” name is almost never a worthwhile change, simply because of this breakage.
Wire format serialization doesn’t look at names, but JSON does! This means that Foo and Foo2 above serialize as {"bar":"content"} and {"bar2":"content"} respectively, making them non-interchangeable.
This can be partially mitigated by using the [json_name = "..."] option on a field. However, this doesn’t actually work, because many Protobuf runtimes’ JSON codecs will accept both the name set in json_name, and the specified field name. So string given_name = 1 [json_name = "firstName"]; will allow deserializing from a key named given_name, but not first_name like it used to. This is still a breaking protocol change!
This is a place where Protobuf could have done better—if json_name had been a repeated string, this wire format breakage would have been avoidable. However, for reasons given below, renames are still a bad idea.
Even if you could avoid source and JSON breakages, the names are always visible to reflection. Although it’s very hard to guard against reflection breakages in general (since it can even see the order fields are declared in), this is one part of reflection that can be especially insidious—for example, if callers choose to sort fields by name, or if some middleware is using the name of a field to identify its frequency, or logging/redaction needs.
Don’t change the name, because reflection means you can’t know what’ll go wrong!
There are valid reasons for wanting to rename a field, such as expanding its scope. For example, first_name and given_name are not the same concept: in the Sinosphere, as well as in Hungary, the first name in a person’s full name is their family name, not their given name.
Or maybe a field that previously referred to a monetary amount, say cost_usd, is being updated to not specify the currency:
In cases like this, renaming the field is a terrible idea. Setting aside source code or JSON breakage, the new field has completely different semantics. If an old consumer, expecting a price in USD, receives a new wire format message serialized from {"cost":990,"currency":"CURRENCY_USD_1000TH"}, it will incorrectly interpret the price as 990USD, rather than 0.99USD. That’s a disastrous bug!
Instead, the right plan is to add cost and currency side-by-side cost_usd. Then, readers should first check for cost_usd when reading cost, and take that to imply that currency is CURRENCY_USD (it’s also worth generating an error if cost and cost_usd are both present).
cost_usd can then be marked as [deprecated = true] . It is possible to even delete cost_usd in some cases, such as when you control all readers and writers — but if you don’t, the risk is very high. Plus, you kind of need to be able to re-interpret cost_usd as the value of cost in perpetuity.
If you do wind up deleting them, make sure to reserve the field’s number and name, to avoid accidental re-use.
Every modern programming language needs a formatter to make your code look pretty and consistent. Formatters are source-transformation tools that parse source code and re-print the resulting AST in some canonical form that normalizes whitespace and optional syntactic constructs. They remove the tedium of matching indentation and brace placement to match a style guide.
Go is particularly well-known for providing a formatter as part of its toolchain from day one. It is not a good formatter, though, because it cannot enforce a maximum column width. Later formatters of the 2010s, such as rustfmt and clang-format, do provide this feature, which ensure that individual lines of code don’t get too long.
The reason Go doesn’t do this is because the naive approach to formatting code makes it intractable to do so. There are many approaches to implementing this, which can make it seem like a very complicated layout constraint solving problem.
So what’s so tricky about formatting code? Aren’t you just printing out an AST?
An AST1 (abstract syntax tree) is a graph representation of a program’s syntax. Let’s consider something like JSON, whose naively-defined AST type might look something like this.
This AST has some pretty major problems. A formatter must not change the syntactic structure of the program (beyond removing things like redundant braces). Formatting must also be deterministic.
First off, Json::Object is a HashMap, which is unordered. So it will immediately discard the order of the keys. Json::String does not retain the escapes from the original string, so "\n" and "\u000a" are indistinguishable. Json::Number will destroy information: JSON numbers can specify values outside of the f64 representable range, but converting to f64 will quantize to the nearest float.
Now, JSON doesn’t have comments, but if it did, our AST has no way to record it! So it would destroy all comment information! Plus, if someone has a document that separates keys into stanzas2, as shown below, this information is lost too.
{"this":"is my first stanza","second":"line","here":"is my second stanza","fourth":"line"}
Truth is, the AST for virtually all competent toolchains are much more complicated than this. Here’s some important properties an AST needs to have to be useful.
Retain span information. Every node in the graph remembers what piece of the file it was parsed from.
Retain whitespace information. “Whitespace” typically includes both whitespace characters, and comments.
Retain ordering information. The children of each node need to be stored in ordered containers.
The first point is achieved in a number of ways, but boils down to somehow associating to each token a pair of integers3, identifying the start and end offsets of the token in the input file.
Given the span information for each token, we can then define the span for each node to be the join of its tokens’ spans, namely the start is the min of its constituent tokens’ starts and its end is the max of the ends. This can be easily calculated recursively.
Once we have spans, it’s easy to recover the whitespace between any two adjacent syntactic constructs by calculating the text between them. This approach is more robust than, say, associating each comment with a specific token, because it makes it easier to discriminate stanzas for formatting.
Being able to retrieve the comments between any two syntax nodes is crucial. Suppose the user writes the following Rust code:
letx=false&&// HACK: disable this check.some_complicated_check();
If we’re formatting the binary expression containing the &&, and we can’t query for comments between the LHS and the operator, or the operator and the RHS, the // HACK comment will get deleted on format, which is pretty bad!
An AST that retains this level of information is sometimes called a “concrete syntax tree”. I do not consider this a useful distinction, because any useful AST must retain span and whitespace information, and it’s kind of pointless to implement the same AST more than once. To me, an AST without spans is incomplete.
With all this in mind, the bare minimum for a “good” AST is gonna be something like this.
structJson{kind:JsonKind,span:(usize,usize),}enumJsonKind{Null,Bool(bool),Number(f64),String(String),Array(Vec<Json>),Object(Vec<(String,Json)>),// Vec, not HashMap.}
There are various layout optimizations we can do: for example, the vast majority of strings exist literally in the original file, so there’s no need to copy them into a String; it’s only necessary if the string contains escapes. My byteyarn crate, which I wrote about here, is meant to make handling this case easy. So we might rewrite this to be lifetime-bound to the original file.
structJson<'src>{kind:JsonKind<'src>,span:(usize,usize),}enumJsonKind<'src>{Null,Bool(bool),Number(f64),String(Yarn<'src,str>),Array(Vec<Json>),Object(Vec<(Yarn<'src,str>,Json)>),// Vec, not HashMap.}
But wait, there’s some things that don’t have spans here. We need to include spans for the braces of Array and Object, their commas, and the colons on object keys. So what we actually get is something like this:
Implementing an AST is one of my least favorite parts of writing a toolchain, because it’s tedious to ensure all of the details are recorded and properly populated.
In Rust, you can easily get a nice recursive print of any struct using the #[derive(Debug)] construct. This is implemented by recursively calling Debug::fmt() on the elements of a struct, but passing modified Formatter state to each call to increase the indentation level each time.
This enables printing nested structs in a way that looks like Rust syntax when using the {:#?} specifier.
The whole point of a formatter is to work with monospaced text, which is text formatted using a monospaced or fixed-width typeface, which means each character is the same width, leading to the measure of the width of lines in columns.
So how many columns does the string cat take up? Three, pretty easy. But we obviously don’t want to count bytes, this isn’t 1971. If we did, кішка, when UTF-8 encoded, it would be 10, rather than 5 columns wide. So we seem to want to count Unicode characters instead?
Oh, but what is a Unicode character? Well, we could say that you’re counting Unicode scalar values (what Rust’s char and Go’s rune) types represent. Or you could count grapheme clusters (like Swift’s Character).
But that would give wrong answers. CJK languages’ characters, such as 猫, usually want to be rendered as two columns, even in monospaced contexts. So, you might go to Unicode and discover UAX#11, and attempt to use it for assigning column widths. But it turns out that the precise rules that monospaced fonts use are not written down in a single place in Unicode. You would also discover that some scripts, such as Arabic, have complex ligature rules that mean that the width of a single character depends on the characters around it.
This is a place where you should hunt for a library. unicode_width is the one for Rust. Given that Unicode segmentation is a closely associated operation to width, segmentation libraries are a good place to look for a width calculation routine.
But most such libraries will still give wrong answers, because of tabs. The tab character U+0009 CHARACTER TABULATION’s width depends on the width of all characters before it, because a tab is as wide as needed to reach the next tabstop, which is a column position an integer multiple of the tab width (usually 2, 4, or, on most terminals, 8).
With a tab width of 4, "\t", "a\t", and "abc\t" are all four columns wide. Depending on the context, you will either want to treat tabs as behaving as going to the next tabstop (and thus being variable width), or having a fixed width. The former is necessary for assigning correct column numbers in diagnostics, but we’ll find that the latter is a better match for what we’re doing.
The reason for being able to calculate the width of a string is to enable line wrapping. At some point in the 2010s, people started writing a lot of code on laptops, where it is not easy to have two editors side by side on the small screen. This removes the motivation to wrap all lines at 80 columns4, which in turn results in lines that tend to get arbitrarily long.
Line wrapping helps ensure that no matter how wide everyone’s editors are, the code I have to read fits on my very narrow editors.
A lot of folks’ first formatter recursively formats a node by formatting its children to determine if they fit on one line or not, and based on that, and their length if they are single-line, determine if their parent should break.
This is a naive approach, which has several disadvantages. First, it’s very easy to accidentally backtrack, trying to only break smaller and smaller subexpressions until things fit on one line, which can lead to quadratic complexity. The logic for whether a node can break is bespoke per node and that makes it easy to make mistakes.
Consider formatting {"foo": [1, 2]}. In our AST, this will look something like this:
To format the whole document, we need to know the width of each field in the object to decide whether the object fits on one line. To do that, we need to calculate the width of each value, and add to it the width of the key, and the width of the : separating them.
How can this be accidentally quadratic? If we simply say “format this node” to obtain its width, that will recursively format all of the children it contains without introducing line breaks, performing work that is linear in how many transitive children that node contains. Having done this, we can now decide if we need to introduce line breaks or not, which increases the indentation at which the children are rendered. This means that the children cannot know ahead of time how much of the line is left for them, so we need to recurse into formatting them again, now knowing the indentation at which the direct children are rendered.
Thus, each node performs work equal to the number of nodes beneath it. This has resulted in many slow formatters.
Now, you could be more clever and have each node be capable of returning its width based on querying its children’s width directly, but that means you need to do complicated arithmetic for each node that needs to be synchronized with the code that actually formats it. Easy to make mistakes.
The solution is to invent some kind of model for your document that specifies how lines should be broken if necessary, and which tracks layout information so that it can be computed in one pass, and then used in a second pass to figure out whether to actually break lines or not.
This is actually how HTML works. The markup describes constraints on the layout of the content, and then a layout engine, over several passes, calculates sizes, solves constraints, and finally produces a raster image representing that HTML document. Following the lead of HTML, we can design…
The HTML DOM is a markup document: a tree of tags where each tag has a type, such as <p>, <a>, <hr>, or <strong>, properties, such as <a href=...>, and content consisting of nested tags (and bare text, which every HTML engine just handles as a special kind of tag), such as <p>Hello <em>World</em>!</p>.
We obviously want to have a tag for text that should be rendered literally. We also want a tag for line breaks that is distinct from the text tag, so that they can be merged during rendering. It might be good to treat text tags consisting of just whitespace, such as whitespace, specially: two newlines \n\n are a blank line, but we might want to merge consecutive blank lines. Similarly, we might want to merge consecutive spaces to simplify generating the DOM.
Consider formatting a language like C++, where a function can have many modifiers on it that can show up in any order, such as inline, virtual, constexpr, and explicit. We might want to canonicalize the order of these modifiers. We don’t want to accidentally wind up printing inline constexpr Foo() because we printed an empty string for virtual. Having special merging for spaces means that all entities are always one space apart if necessary. This is a small convenience in the DOM that multiplies to significant simplification when lowering from AST to DOM.
Another useful tag is something like <indent by=" ">, which increases the indentation level by some string (or perhaps simply a number of spaces; the string just makes supporting tabs easier) for the tags inside of it. This allows control of indentation in a carefully-scoped manner.
Finally, we need some way to group tags that are candidates for “breaking”: if the width of all of the tags inside of a <group> is greater than the maximum width that group can have (determined by indentation and any elements on the same line as that group), we can set that group to “broken”, and… well, what should breaking do?
We want breaking to not just cause certain newlines (at strategic locations) to appear, but we also want it to cause an indentation increase, and in languages with trailing commas like Rust and Go, we want (or in the case of Go, need) to insert a trailing comma only when broken into multiple lines. We can achieve this by allowing any tag to be conditioned on whether the enclosing group is broken or not.
Taken all together, we can render the AST for our {"foo": [1, 2]} document into this DOM, according to the tags we’ve described above.
Notice a few things: All of the newlines are set to appear only if=broken. The space between the two commas only appears if the enclosing group is not broken, that is if=flat. The groups encompass everything that can move due to a break, which includes the outer braces. This is necessary because if that brace is not part of the group, and it is the only character past the line width limit, it will not cause the group to break.
The first pass is easy: it measures how wide every node is. But we don’t know whether any groups will break, so how can we measure that without calculating breaks, which depend on indentation, and the width of their children, and…
This is one tricky thing about multi-pass graph algorithms (or graph algorithms in general): it can be easy to become overwhelmed trying to factor the dependencies at each node so that they are not cyclic. I struggled with this algorithm, until I realized that the only width we care about is the width if no groups are ever broken.
Consider the following logic: if a group needs to break, all of its parents must obviously break, because the group will now contain a newline, so its parents must break no matter what. Therefore, we only consider the width of a node when deciding if a group must break intrinsically, i.e., because all of its children decided not to break. This can happen for a document like the following, where each inner node is quite large, but not large enough to hit the limit.
Because we prefer to break outer groups rather than inner groups, we can measure the “widest a single line could be” in one pass, bottom-up: each node’s width is the sum of the width of its children, or its literal contents for <text> elements. However, we must exclude all text nodes that are if=broken, because they obviously do not contribute to the single-line length. We can also ignore indentation because indentation never happens in a single line.
However, this doesn’t give the full answer for whether a given group should break, because that depends on indentation and what nodes came before on the same line.
This means we need to perform a second pass: having laid everything out assuming no group is broken, we must lay things out as they would appear when we render them, taking into account breaking. But now that we know the maximum width of each group if left unbroken, we can make breaking decisions.
As we walk the DOM, we keep track of the current column and indentation value. For each group, we decide to break it if either:
Its width, plus the current column value, exceeds the maximum column width.
It contains any newlines, something that can be determined in the first pass.
The first case is why we can’t actually treat tabs as if they advance to a tabstop. We cannot know the column at which a node will be placed at the time that we measure its width, so we need to assume the worst case.
Whenever we hit a newline, we update the current width to the width induced by indentation, simulating a newline plus indent. We also need to evaluate the condition, if present, on each tag now, since by the time we inspect a non-group tag, we have already made a decision as to whether to break or not.
Now that everything is determined, rendering is super easy: just walk the DOM and print out all the text nodes that either have no condition or whose condition matches the innermost group they’re inside of.
And, of course, this is where we need to be careful with indentation: you don’t want to have lines that end in whitespace, so you should make sure to not print out any spaces until text is written after a newline. This is also a good opportunity to merge adjacent only-newlines text blocks. The merge algorithm I like is to make sure that when n and m newline blocks are adjacent, print max(n, m) newlines. This ensures that a DOM node containing \n\n\n is respected, while deleting a bunch of \ns in a row that would result in many blank lines.
What’s awesome about this approach is that the layout algorithm is highly generic: you can re-use it for whatever compiler frontend you like, without needing to fuss with layout yourself. There is a very direct conversion from AST to DOM, and the result is very declarative.
YAML is a superset of JSON that SREs use to write sentient configuration files. It has a funny list syntax that we might want to use for multi-line lists, but we might want to keep JSON-style lists for short ones.
A document of nested lists might look something like this:
Here, we’ve made the [] and the comma only appear in flat mode, while in broken mode, we have a - prefix for each item. The inserted newlines have also changed somewhat, and the indentation blocks have moved: now only the value is indented, since YAML allows the -s of list items to be at the same indentation level as the parent value for lists nested in objects. (This is a case where some layout logic is language-specific, but now the output is worrying about declarative markup rather than physical measurements.)
There are other enhancements you might want to make to the DOM I don’t describe here. For example, comments want to be word-wrapped, but you might not know what the width is until layout happens. Having a separate tag for word-wrapped blocks would help here.
Similarly, a mechanism for “partial breaks”, such as for the document below, could be implemented by having a type of line break tag that breaks if the text that follows overflows the column, which can be easily implemented by tracking the position of the last such break tag.
I think that a really good formatter is essential for any programming language, and I think that a high-quality library that does most of the heavy-lifting is important to make it easier to demand good formatters.
So I wrote a Rust library. I haven’t released it on crates.io because I don’t think it’s quite at the state I want, but it turns out that the layout algorithm is very simple, so porting this to other languages should be EZ.
Now you have no excuse. :D
Everyone pronounces this acronym “ay ess tee”, but I have a friend who really like to say ast, rhyming with mast, so I’m making a callout post my twitter dot com. ↩
In computing, a group of lines not separated by blank lines is called a stanza, in analogy to the stanzas of a poem, which are typeset with no blank lines between the lines of the stanza. ↩
You could also just store a string, containing the original text, but storing offsets is necessary for diagnostics, which is the jargon term for a compiler error. Compiler errors are recorded using an AST node as context, and to report the line at which the error occurred, we need to be able to map the node back to its offset in the file.
Once we have the offset, we can calculate the line in O(logn) time using binary search. Having pre-computed an array of the offset of each \n byte in the input file, binary search will tell us the index and offset of the \n before the token; this index is the zero-indexed line number, and the string from that \n to the offset can be used to calculate the column.
useunicode_width::UnicodeWidthStr;/// Returns the index of each newline. Can be pre-computed and re-used/// multiple times.fnnewlines(file:&str)->Vec<usize>{file.bytes().enumerate().filter_map(|(i,b)|(b==b'\n').then_some(i+1))}/// Returns the line and column of the given offset, given the line/// tarts of the file.fnlocation(file:&str,newlines:&[usize],offset:usize,)->(usize,usize){matchnewlines.binary_search(offset){// Ok means that offset refers to a newline, so this means// we want to return the width of the line that it ends as// the column.//// Err means that this is after the nth newline, except Err(0),// which means it is before the first one.Ok(0)|Err(0)=>(1,file[..offset].width()),Ok(n)=>(n+1,file[newlines[n-1]..offset].width()),Err(n)=>(n+2,file[newlines[n]..offset].width()),}}
The Rust people keep trying to convince me that it should be 100. They are wrong. 80 is perfect. They only think they need 100 because they use the incorrect tab width of four spaces, rather than two. This is the default for clang-format and it’s perfect. ↩
2024-12-16 • 3570 words • 39 minutes •#dark-arts • #go
A second post on Go silliness (Miguel, aren’t you a C++ programmer?): in 1.23, Go finally added custom iterators. Now, back when I was at Google and involved in the Go compiler as “the annoying Rust guy who gets lunch with us”, there were proposals suggesting adding something like this, implemented as either an interface or a func:
An iterator, in the context of programming language design, is a special type of value that can be used to walk through a sequence of values, without necessarily materializing the sequence as whatever the language’s array type is.
But, a proper iterator must fit with the language’s looping construct. An iterable type is one which can be used in a for-each loop, such as C++’s for (T x : y) or Python’s for x in y (modern languages usually only have a for-each loop as their only for loop, because C-style for loops are not in anymore).
Every language defines a desugaring that defines how custom iteration works in term of the more primitive loops. For example, in C++, when we write for (T x : y) { ... } (called a range-based for loop, added in C++11), desugars as follows1:
break, continue, and return inside of the loop body require no special handling: they Just Work, because this is just a plain ol for loop.
This begin and end weirdness is because, if the iterator backs an actual array, begin and end can just be pointers to the first element and one-past-the-end and this will Just Work. Before C++11, the convention for C++ iterators was to construct types that imitated pointers; you would usually write loops over non-array types like this:
C++ simply codified common (if gross) practice. It is very tedious to implement C++ iterators, though. You need to provide a dummy end iterator, you need to provide some kind of comparison operator, and iterators that don’t return a reference out of operator*() are… weird.
Begin and end can be different types (which is how C++20 ranges pretend to be iterable), but being able to query done-ness separately from the next value makes implementation annoying: it means that an iterator that has not begun iteration (i.e., ++ has not been executed yet, because it occurs in the loop’s latch, not its header2) needs to do extra work to answer != end, which usually means an extra bool to keep track of whether iteration has started or not.
Here’s what writing an iterator (that is also an iterable usable in a range for-loop) over the non-zero elements of a std::span<const int> might look like.
In this case, operator== is notconst, which is a bit naughty. Purists might argue that this type should have a constructor, which adjusts ints to point to the first non-zero element on construction, and operator++ to perform the mutation. That would look like this:
std::sentinel_for (C++’s iterator concepts are terribly named) really wants operator== to be const, but I could have also just marked ints as mutable to avoid that. It it’s not already clear, I really dislike this pattern. See here for some faffing about with C++ iterators on my part.
Do you see the problem here? Although Java now provides a standard interface, doesn’t require annoying equality comparisons, and doesn’t require an end value, these things are still a pain to implement! You still need to be able to query if you’re done before you’ve had a chance to step through the iterator.
Like before, suppose we have an int[], and we want to yield every non-zero value in it. How do we construct an iterator for that?
What a pain. Java’s anonymous classes being wordy aside, it’s annoying and error-prone to do this: it’s tempting to accidentally implement hasNext by simply checking if the array is empty. (Aside, I hate that xs.length throws on null arrays. Just return zero like in Go, c’mon).
Also, it’s no a single-abstract-method interface, so I can’t use a lambda to create an iterator.
At least break, continue, and return Just Work, because the underlying operation is a for loop like before.
// mod core::iterpubtraitIntoIterator{typeItem;typeIter:Iterator<Item=Self::Item>;fninto_iter()->Self::Iter;}pubtraitIterator{typeItem;fnnext()->Option<Self::Item>;}
This is so straightforward that it’s not so unusual to write it yourself, when you don’t plan on consuming the entire iterator. Alternatively, you can partially iterate over an iterator by taking a mutable reference to it. This is useful for iterators that can yield their remainder.
break, continue, and return work in the obvious way.
The interface solves the problems C++ and Java had very cleanly: next both computes the next item and whether the iterator has more elements. Rust even allows iterators to resume yielding Some after yielding None, although few algorithms will make use of this.
Implementing the non-zero iterator we’ve been writing so far is quite simple:
It requires a little bit of effort to implement some iterators, but most of the common cases are easy to put together with composition.
Python iterators are basically the same thing, but there’s no interface to implement (because Python doesn’t believe in type safety). Lua iterators are similar. The Rust pattern of a function that returns the next item (or a special end-of-sequence value) is relatively popular because of this simplicity and composability, and because they can model a lot of iteration strategies.
The x can be a list of places, and the := can be plain assignment, =. You can also write for range y { ... } if the iteration values aren’t needed.
The behavior of this construct, like many others in Go, depends explicitly on the type after range. Each range iteration can yield zero or more values; the
These are:
For []T, [n]T, and *[n]T, each step yields an index of the slice and the value at that offset, in order.
For map[K]V, each step yields a key and a value, in a random order.
This function will call yield for each element in the map. If the function returns false, iteration will stop. This pattern is not uncommon, but sometimes libraries omit the bool return (like container/ring.Ring.Do). Some, like filepath.WalkDir, have a more complex interface involving errors.
This is the template for what became rangefuncs, a mechanism for using the for-range syntax with certain function values.
The word “rangefunc” does not appear in Go’s specification. It is a term used to refer to them in some documentation, within the compiler, and in the runtime.
A rangefunc is any function with one of the following signatures:
func(yield func() bool)
func(yield func(V) bool)
func(yield func(K, V) bool)
They work like sync.Map.Range does: the function calls yield (hereafter simply called “the yield”) for each element, and stops early if yield returns false. The iter package contains types for the second and third of these:
For example, the slices package provides an adaptor for converting a slice into an iterator that ranges over it.
packageslices// All returns an iterator over index-value pairs in the slice// in the usual order.funcAll[Slice~[]E,Eany](sSlice)iter.Seq2[int,E]{returnfunc(yieldfunc(int,E)bool){fori,v:=ranges{if!yield(i,v){return}}}}
So. These things are actually pretty nuts. They break my brain somewhat, because this is the opposite of how iterators usually work. Go calls what I’ve described all the other languages do a “pull iterator”, whereas rangefuncs are “push iterators”.
They have a few obvious limitations. For one, you can’t do smart sizing like with Rust or C++ iterators5. Another is that you can’t easily “pause” iteration.
But they do have one advantage, which I think is the real reason Go went to so much trouble to implement them (and yes, I will dig into how insane that part is). Using push iterators by default means that users “only” need to write an ordinary for loop packaged into a function. Given that Go makes major performance sacrifices in order to be easy to learn6, trying to make it so that an iterator packages the actual looping construct it represents makes quite a bit of sense.
Rangefuncs are actually really cool in some respects, because they enable unusual patterns. For example, you can use a rangefunc to provide RAII blocks.
Being a block that you can put an epilog onto after yielding a single element is quite powerful! You can also use a nilary rangefunc to simply create a block that you can break out of, instead of having to use goto.
The desugaring for rangefuncs is very complicated. This is because break, continue, goto, and return all work in a rangefunc! How does this work? Let’s Godbolt it.
Let’s start with something really basic: a loop body that just calls a function.
This produces the following assembly output (which I’ve reformatted into Intel syntax, and removed some extraneous ABI things, including a writer barrier where (*) is below).
x.run:pushrbpmovrbp,rspaddrsp,-24mov[rsp+40],raxlearax,[type:int]callruntime.newobjectmov[rsp+16],raxmov[rax],internal/abi.RF_READYlearax,["type:noalg.struct { F uintptr; X0 *int }"]callruntime.newobjectlearcx,x.run-range1mov[rax],rcx// (*)movrcx,[rsp+16]mov[rax+8],rcxmovrdx,[rsp+40]movrbx,[rdx]callrbxmovrcx,[rsp+16]cmp[rcx],internal/abi.RF_PANICjeqpanicmov[rcx],internal/abi.RF_EXHAUSTEDaddrsp,24poprbpretpanic:movrax,internal/abi.RF_MISSING_PANICcallruntime.panicrangestatex.run-range1:pushrbpmovrbp,rspaddrsp,-24mov[rsp+8],rdxmovrcx,[rdx+8]movrdx,[rcx]cmpqwordptr[rdx],internal/abi.RF_READYjnepanic2mov[rsp+16],rcxmovqwordptr[rcx],internal/api.RF_PANICcallx.sinkmovrcx,[rsp+16]movqwordptr[rcx],internal/abi.RF_READYmovrax,1addrsp,24poprpbretpanic2:movrax,rdxcallruntime.panicrangestate
Go will actually enforce invariants on the yield it synthesizes in a range for, in order to catch buggy code. In particular, __state escapes because s is an arbitrary function, so it gets spilled to the heap.
So, what happens when the loop body contains a break? Consider:
The reason __next is an int is because it is also used when exiting the loop via goto or a break/continue with label. It specifies where to jump to after the call into the rangefunc returns. Each potential control flow out of the loop is assigned some negative number.
The precise details of the lowering have been exquisitely documented by Russ Cox and David Chase, the primary implementers of the feature.
You might be curious what runtime.panicrangestate does. It’s pretty simple, and it lives in runtime/panic.go:
packageruntime//go:noinlinefuncpanicrangestate(stateint){switchabi.RF_State(state){caseabi.RF_DONE:panic(rangeDoneError)caseabi.RF_PANIC:panic(rangePanicError)caseabi.RF_EXHAUSTED:panic(rangeExhaustedError)caseabi.RF_MISSING_PANIC:panic(rangeMissingPanicError)}throw("unexpected state passed to panicrangestate")}
If you visit this function in runtime/panic.go, you will be greeted by this extremely terrifying comment from Russ Cox immediately after it.
// deferrangefunc is called by functions that are about to// execute a range-over-function loop in which the loop body// may execute a defer statement. That defer needs to add to// the chain for the current function, not the func literal synthesized// to represent the loop body. To do that, the original function// calls deferrangefunc to obtain an opaque token representing// the current frame, and then the loop body uses deferprocat// instead of deferproc to add to that frame's defer lists.//// The token is an 'any' with underlying type *atomic.Pointer[_defer].// It is the atomically-updated head of a linked list of _defer structs// representing deferred calls. At the same time, we create a _defer// struct on the main g._defer list with d.head set to this head pointer.//// The g._defer list is now a linked list of deferred calls,// but an atomic list hanging off://// (increasingly terrifying discussion of concurrent data structures)
This raises one more thing that works in range funcs, seamlessly: defer. Yes, despite the yield executing multiple call stacks away, possibly on a different goroutine… defer still gets attached to the calling function.
The way defer works is that each G (the goroutine struct, runtime.g) holds a linked list of defer records, of type _defer. Each call to defer sticks one of these onto this list. On function return, Go calls runtime.deferreturn(), which essentially executes and pops defers off of the list until it finds one whose stack pointer is not the current function’s stack pointer (so, it must belong to another function).
Rangefuncs throw a wrench in that mix: if myFunc.range-n defers, that defer has to be attached to myFunc’s defer records somehow. So the list must have a way of inserting in the middle.
This is what this comment is about: when defer occurs in the loop body, that defer gets attached to a defer record for that function, using a token that the yield captures; this is later canonicalized when walking the defer list on the way out of myFunc. Because the yield can escape onto another goroutine, this part of the defer chain has to be atomic.
Incredibly, this approach is extremely robust. For example, if we spawn the yield as a goroutine, and carefully synchronize between that and the outer function, we can force the runtime to hard-crash when defering to a function that has returned.
packagemainimport("fmt""sync")funcbad()(outfunc()){varw1,w2sync.WaitGroupw1.Add(1)w2.Add(1)out=w2.Donedeferfunc(){recover()}()iter:=func(yieldfunc()bool){goyield()w1.Wait()// Wait to enter yield().// This panics once w1.Done() executes, because// we exit the rangefunc while yield() is still// running. The runtime incorrectly attributes// this to recovering in the rangefunc.}forrangeiter{w1.Done()// Allow the outer function to exit the loop.w2.Wait()// Wait for bad() to return.deferfmt.Println("bang")}returnnil// Unreachable}funcmain(){resume:=bad()resume()select{}// Block til crash.}
This gets us fatal error: defer after range func returned. Pretty sick! It accomplishes this by poisoning the token the yield func uses to defer.
I have tried various other attempts at causing memory unsafety with rangefuncs, but Go actually does a really good job of avoiding this. The only thing I’ve managed to do that’s especially interesting is to tear the return slot on a function without named returns, but that’s no worse than tearing any other value (which is still really bad, because you can tear interface values, but it’s not worse).
Of course we’re not done. Go provides a mechanism for converting push iterators into pull iterators. Essentially, there is a function that looks like this:
Essentially, you can request values with next(), and stop() can be used if you finish early. But also, this spawns a whole goroutine and uses channels to communicate and synchronize, which feels very unnecessary.
The implementation doesn’t use goroutines. It uses coroutines.
Spawning a goroutine is expensive. Doing so expends scheduler and memory resources. It’s overkill for a helper like this (ironic, because the original premise of Go was that goroutines would be cheap enough to allocate willy-nilly).
Go instead implements this using “coroutines”, a mechanism for concurrency without parallelism. This is intended to make context switching very cheap, because it does not need to go through the scheduler: instead, it uses cooperative multitasking.
The coroutine interface is something like the following. My “userland” implementation will not be very efficient, because it relies on the scheduler to transfer control. The goroutines may run on different CPUs, so synchronization is necessary for communication, even if they are not running concurrently.
When we create a coroutine with coro.New(), it spawns a goroutine that waits on a mutex. Another goroutine can “take its place” as the mutex holder by calling c.Resume(), which allows the coroutine spawned by coro.New to resume and enter f().
Using the coroutine as a rendezvous point, two goroutines can perform concurrent work: in the case of iter.Pull, one can be deep inside of whatever loops the iterator wants to do, and the other can request values.
Here’s what using my coro.Coro to implement iter.Pull might look like:
packageiterfuncPull[Vany](seqSeq[V])(nextfunc()(V,bool),stopfunc()){var(doneboolv,zV)c:=coro.New(func(){s(func(v1V)bool{c.Resume()// Wait for a request for a value.ifdone{// This means we resumed from stop(). Break out of the// loop.returnfalse}v=v1})if!done{// Yield the last value.c.Resume()}v=zdone=true})next=func()(V,bool){ifdone{returnz,false}c.Resume()// Request a value.returnv,true// Return it.}stop=func(){ifdone{return}done=true// Mark iteration as complete.c.Resume()// Resume the iteration goroutine to it can exit.}returnnext,stop}
If you look at the implementation in iter.go, it’s basically this, but with a lot of error checking and race detection, to prevent misuse, such as if next or stop escape to other goroutines.
Now, the main thing that runtime support brings here is that Resume() is immediate: it does not go to the scheduler, which might not decide to immediately run the goroutine that last called Resume() for a variety of reasons (for example, to ensure wakeup fairness). Coroutines sidestep fairness, by making Resume() little more than a jump to the last Resume() (with registers fixed up accordingly).
This is not going to be that cheap: a goroutine still needs to be allocated, and switching needs to poke and prod the underlying Gs a little bit. But it’s a cool optimization, and I hope coroutines eventually make their way into more things in Go, hopefully as a language or sync primitive.
Congratulations, you have survived over 3000 words of me going on about iterators. Go’s push iterators are a unique approach to a common language design problem (even if it took a decade for them to materialize).
I encountered rangefuncs for the first time earlier this year and have found them absolutely fascinating, both from a “oh my god they actually did that” perspective and from a “how do we express iteration” perspective. I don’t think the result was perfect by any means, and it is unsuitable for languages that need the performance you can only get from pull iterators. I think they would be a great match for a language like Python or Java, though.
I’d like to thank David Chase, an old colleague, for tolerating my excited contrived questions about the guts of this feature.
Ugh, ok. This is the C++20 desugaring, and there are cases where we do not just call std::begin(). In particular, array references and class type references with .begin() and .end() do not call std::begin() and are open-coded. This means that you can’t use ADL to override these types’ iterator. ↩
In compiler jargon, a loop is broken up into three parts: the header, which is where the loop is entered, the body, which is one step of iteration, and the latch, which is the part that jumps back to the start of the body. This is where incrementation in a C-style for loop happens. ↩
And with better performance. Rust’s iterators can provide a size hint to help size containers before a call to collect(), via the FromIterator trait. ↩
Some people observed that you can use a channel as a custom iterator, by having a parallel goroutine run a for loop to feed the channel. Do not do this. It is slow: it has to transit each element through the heap, forcing anything it points to escape. It takes up an extra M and a P in the scheduler, and requires potentially allocating a stack for a G. It’s probably faster to just build a slice and return that, especially for small iterations. ↩
For this reason, I wish that Go had instead defined something along these lines.
I don’t think there’s an easy way to patch this up, at this point. ↩
Disclaimer: I am not going to dig into Go’s rationale for rangefuncs. Knowing how the sausage is made, most big Go proposals are a mix of understandable reasoning and less reasonable veiled post-hoc justification to compensate for either Google planning/approvals weirdness or because the design was some principal engineer’s pony. This isn’t even a Go thing, it’s a Google culture problem. I say this as the architect of Protobuf Editions, the biggest change to Protobuf since Rob’s misguided proto37 experiment. I have written this kind of language proposal, on purpose, because bad culture mandated it.
The purpose of a system is what it does. It is easier to understand a system by observing its response to stimuli, rather than what it says on the tin. So let’s use that lens.
Go wants to be easy to learn. It intended to replace C++ at Google (lol, lmao), which, of course, failed disastrously, because performance of the things already written in C++ is tied to revenue. They have successfully pivoted to being an easy-to-learn language that makes it easy to onboard programmers regardless of what they already use, as opposed to onboarding them to C++.
This does not mean that Go is user-friendly. In fact, user-friendliness is clearly not a core value. Rob and his greybeard crowd didn’t seem to care about the human aspect of interacting with a toolchain, so Go tooling rarely provides good diagnostics, nor did the language, until the last few years, try to reduce toil. After all, if it is tedious to use but simple, that does make it easy to onboard new programmers.
Rust is the opposite: it is very difficult to learn with a famously steep learning curve; however, it is very accessible, because the implementors have sanded down every corner and sharp edge using diagnostics, error messages, and tooling. C++ is neither of these things. It is very difficult to learn, and most compilers are pretty unhelpful (if they diagnose anything at all).
I think that Go has at least realized the language can be a pain to use in some situations, which is fueled in part by legitimate UX research. This is why Go has generics and other recent advanced language features, like being able to use the for syntax with integers or with custom iterators.
I think that rangefuncs are easy to learn in the way Go needs them to be. If you expect more users to want to write rangefuncs than users want to write complicated uses of rangefuncs, I think push iterators are the easiest to learn how to use.
I think this is a much more important reason for all the trouble that rangefuncs generate for the compiler and runtime than, say, compatibility with existing code; I have not seen many cases in the wild or in the standard library that conform to the rangefunc signatures. ↩
But please don’t use proto3. I’m telling you that as the guy who maintained the compiler. Just don’t. ↩
Lately I’ve been finding myself writing a bit of Go, and I’ve picked up various fun “layout secrets” that help inform how I write code to minimize hidden allocations, and generally be kind to the optimizer. This article is a series of notes on the topic.
This post is about Go implementation details, so they can probably break you at any time if you rely on it. On the other hand, Hyrum’s law is a bitch, so taking your chances may not be that bad. After all, they’re probably never going to be able to properly clean up the mess people made with //go:linkname with runtime symbols…
As with many of my other posts, I’ll assume a basic familiarity with being able to read assembly. I’m using x86 for this post, but it’s worth looking at my RISC-V post for a refresher.
The most basic Go-specific concept when it comes to type layouts is the shape of a type. This is an implementation detail of Go’s garbage collector that leaks through the unsafe package.
Like in most native programming languages, every Go type has a size (the number of bytes that type takes up in memory) and an alignment (a power of two that every pointer to that type must be divisible by). Go, like most other languages, requires that size be divisible by the alignment: that is, the size is equal to the stride of an array of that type.
The size an alignment of a type can be queried by the intrinsics unsafe.Sizeof and unsafe.Alignof. These are very unwieldy in generic code, so I like to define a couple of helpers1:
Together, these two quantities are called the layout of a type (a term common to many native languages). However, the shape of a type also records what pieces thereof contain pointers. This is because memory visible to the GC (such as globals, heap memory, or stack roots) is typed, and the GC needs to know which parts of those types are pointers that it needs to trace through.
Because all pointers have the same size and alignment (4 or 8 bytes depending on the system) the pointer words of a type can be represented as a bitset, one bit for every 4 or 8 bytes in the type. This, in fact, is the representation used by the GC2.
In particular, this means that whether a field is to be interpreted as an unsafe.Pointer or as a uintptr is a static property of the type. As we will see when we discuss interfaces, this restriction prevents a few layout optimizations.
len and cap are extracted by their eponymous builtins, and data can be obtained using unsafe.SliceData (or &s[0] if the slice is nonempty, but that costs a bounds-check).
A string has the same layout as a []byte, except for a capacity:
Despite essentially being slices, Go treats strings subtly differently. Strings are comparable, so they can be used as map keys. They are also immutable, which enables a handful of optimizations. Immutability is also why they are comparable: Go made the mistake of not keeping const from C, but they really want map keys to be const.
There is nothing stopping us from aliasing strings to data pointed to by a slice: after all, strings.Builder does it to avoid a copy in String(). We can implement this easily enough with some unsafe:
Doing this is perfectly safe, so long as data is not mutated while the returned string is accessible. This allows virtually any slice type to be used as a key in a map, with some caveats.
Types which contain alignment padding cannot be used, because Go does not promise that it zeros memory returned by new.
Types which contain pointers will cause those pointers to become unreachable if the only reference is the aliased string; this is because the pointed to data’s shape contains no pointer words.
Incomparable types and interfaces will be compared by address (that is, maps, channels and funcs).
Now, this isn’t the only to accomplish this: you can create dynamically-sized array types using reflection, like so:
funcSlice2Array[Tany](s[]T)any{ifs==nil{returnnil}varvTelem:=reflect.TypeOf(v)array:=reflect.ArrayOf(len(s),elem)// NOTE: NewAt will return a reflect.Value containing a// pointer, not an array!refl:=reflect.NewAt(array,unsafe.SliceData(s))refl=refl.Elem()// Dereference to get a pointer-to-array.returnrefl.Interface()}
This will return an any whose type is [len(s)]T. You can even type assert it for static array sizes. This any is suitable for placing into a map[any]T, just as if we had built it with e.g. any([...]byte("foo"))
However, and this is not at all obvious from the code here, calling refl.Interface() will perform a copy of the whole array. Interface() delegates through a few functions until it calls reflect.packEface().
The code this function (found here) is reproduced below:
packagereflect// packEface converts v to the empty interface.funcpackEface(vValue)any{t:=v.typ()varianye:=(*abi.EmptyInterface)(unsafe.Pointer(&i))// First, fill in the data portion of the interface.switch{caset.IfaceIndir():ifv.flag&flagIndir==0{panic("bad indir")}// Value is indirect, and so is the interface we're making.ptr:=v.ptrifv.flag&flagAddr!=0{c:=unsafe_New(t)typedmemmove(t,c,ptr)ptr=c}e.Data=ptrcasev.flag&flagIndir!=0:// Value is indirect, but interface is direct. We need// to load the data at v.ptr into the interface data word.e.Data=*(*unsafe.Pointer)(v.ptr)default:// Value is direct, and so is the interface.e.Data=v.ptr}// Now, fill in the type portion. We're very careful here not// to have any operation between the e.word and e.typ assignments// that would let the garbage collector observe the partially-built// interface value.e.Type=treturni}
The switch determines precisely how the interface data pointer is computed. It turns out that (almost all) array types return true for t.IfaceIndr(), so the first case is selected, which triggers a copy (that being the call to unsafe_New() followed by a typedmemmove). This copy is to ensure that the value of the resulting interface cannot be mutated.
Now, if only we knew the layout of Go’s interfaces, we might be able to get somewhere here…
Oh, yes, that’s what this article is about. So, if we look at the runtime2.go file in the runtime (yes, that’s what it’s called), nestled among the giant scheduler types for Gs, Ps, and Ms, we’ll find a couple of structs that really elucidate what’s going on:
packageruntimetypefuncvalstruct{fnuintptr// variable-size, fn-specific data here}typeifacestruct{tab*itabdataunsafe.Pointer}typeefacestruct{_type*_typedataunsafe.Pointer}
funcval is the layout of a func(), more on that later. iface is the layout of your “usual” interface, consisting of an itab (an interface table, or what Go calls a vtable) and a pointer to some data. eface is the layout of any (the artist formerly known as interface{}, hence the name: empty interface).
eface having its own layout is an optimization. Because any exists to be downcast from dynamically, storing the type directly cuts out a pointer load when doing a type switch on an any specifically. If we look at what an itab is (which is “just” an abi.ITab):
packageabi// The first word of every non-empty interface type contains an *ITab.// It records the underlying concrete type (Type), the interface type// it is implementing (Inter), and some ancillary information.//// allocated in non-garbage-collected memorytypeITabstruct{Inter*InterfaceTypeType*TypeHashuint32// copy of Type.Hash. Used for type switches.Fun[1]uintptr// fun[0]==0 means Type does not implement Inter.}
In the register ABI, the x86 argument (and return) registers are rax, rbx, rcx, rdi, rsi, r8, r9, r10 and r11 (with rdx reserved for passing a closure capture, more on that later; r14 holds a pointer to the currently running G).
The *ITab comes in on rax and the data pointer on rbx. First, we need to check if this is the nil interface, identified by having a nil itab (or type, in the case of any). If it is nil, we just return: rax:rbx already contain the data of a nil any. Otherwise, we load ITab.Type, at offset 8, into rax, and return.
This function seems to be doing a lot more than it actually is. Part of it is that its prologue has to do a call to runtime.morestack_noctxt(), which is simply a call to runtime.morestack that clobbers rdx, the closure capture parameter. The meat of it comes when it loads [rax + 24], the first element of ITab.Fun. It then moves the data pointer in rbx to rax, the argument into rbx, and issues the call.
What about upcasts? An upcast to a concrete type is quite simple: simply compare the type in the interface (either directly or in the *ITab) to a particular statically-known one. Downcasting to an interface (sometimes called a sidecast) is much more complicated, because it essentially requires a little bit of reflection.
foo.Downcast:cmprsp,[r14+16]jlsgrowpushrpbmovrbp,rspaddrsp,-24mov[rsp],raxmov[rsp+8],rbxtestrax,raxjeqnilmovrcx,[foo..typeAssert0]movrdx,[rcx]movrsi,[rax+16]hashProbe:movrdi,rsiandrsi,rdxshlrsi,4movr8,[rcx+rsi+8]cmprax,r8jeqfoundlearsi,[rdi+1]testr8,r8jnzhashProbemov[rsp+8],rbxmovrbx,raxleqrax,[foo..typeAssert0]callruntime.typeAssertmovrbx,[rsp+8]jmpdonefound:movrax,[rcx+rsi+16]done:addrsp,24poprpbretnil:learax,[type:foo.MyIface]callruntime.panicnildottypegrow:// Same as it was in foo.Call above.jmpfoo.Downcast
When we request an interface downcast, the Go compiler synthesizes a symbol of type abi.TypeAssert. Its definition is reproduced below.
packageabitypeTypeAssertstruct{Cache*TypeAssertCacheInter*InterfaceTypeCanFailbool}typeTypeAssertCachestruct{MaskuintptrEntries[1]TypeAssertCacheEntry}typeTypeAssertCacheEntrystruct{// type of source value (a *runtime._type)Typuintptr// itab to use for result (a *runtime.itab)// nil if CanFail is set and conversion would fail.Itabuintptr}
The first thing this function does is check if rax contains 0, i.e., if this is a nil any, and panics if that’s the case (that’s a call to runtime.panicnildottype). It then loads foo..typeAssert0, a synthetic global variable containing an abi.TypeAssert value. It loads the Cache field, as well as the Hash field of the abi.Type attached to the any. It masks off the low bits using typeAssert0.Cache.Mask, and uses that to start probing the very simple open-addressed hash table located in typeAssert0.Cache.Entries.
If it finds a TypeAssertCacheEntry with the type we’re looking for (compared by address), we’ve found it. We load that entry’s Itab value into rax to change the value from being an any to being a MyIface, and we’re done.
If it finds a TypeAssertCacheEntry with a nil Typ pointer, we’re forced to hit the slow path, implemented at runtime.typeAssert(). This dynamically builds an itab by searching the method set of the type inside the any.
This then calls the reflection code in runtime.getitab(), which is what actually performs the messy search through the method set, comparing the names and signatures of methods with those in the interface, to produce an itab at runtime.
Then, it shoves this the resulting itab into the global itab cache, which is protected by a global lock! There are lots of scary atomics in this code. There are many places where this can potentially panic, bubbling up a type assertion failure to the user.
When runtime.getitab() returns, runtime.typeAssert() will maybe4 update the type assertion cache, and return the new itab. This allows the code in our function to return directly, without needing to take another trip into the hashProbe loop.
In theory, PGO could be used to pre-fill the cache, but I couldn’t find any code in the compiler that indicates that this is something they do. In the meantime, you can optimize a hot type assert ahead of time by asserting to a known common type:
funcDoSomething(rio.Reader){varrsio.ReadSeekeriff,ok:=r.(*os.File);ok{// Check for a known implementation first. This only costs// a pointer comparison with the *abi.Type in the itab.rs=f}elseiff,ok:=r.(io.ReadSeeker);ok{// Do an interface type assertion. This would eventually// learn os.File, but the branch above skips that "warmup"// time. It also lets the hardware branch predictor allocate// a prediction slot just for os.File.rs=f}else{// ...}}
Back when we were hacking arrays into existence with reflection, there was some trouble in reflect.Value.Interface(), where it would do a seemingly unnecessary copy.
This is because an interface’s data pointer must be a pointer. If you cram, say, an int into an any, Go will spill it to the heap. This is often called boxing, but the Go runtime refers to it as an “indirect interface”.
Like many other managed languages, Go will skip boxing very small values by instead returning pointers into some global array.
Now, this boxing could be avoided: after all, an int is no larger than a pointer, so we could cram it into the data pointer field directly. However, the GC really doesn’t like that: the GC assumes it can trace through any pointer. Now, the GC could treat interfaces differently, and look at the type/itab pointer to determine if the data value pointer or a scalar. However, this would add significant complexity to both the representation of shapes, and to the tracing code in the GC, resulting in more branches and slower tracing.
However, if the type being wrapped in an interface happens to be a pointer, it can just use that pointer value directly.
Any type that has the same shape as a pointer will be indirect. This includes maps, channels, and funcs. It also includes one element arrays of such types, such as [1]*int and [1]chan error, and single-field structs of such types. Curiously, this does not include structs which contain a zero-sized field before the pointer-sized field, even though those have the same shape as a pointer.
This means it’s generally not safe to play games with forging an interface out of a pointer to some type: whether that type is indirect in an interface is a subtle implementation detail of the compiler.
And of course, it’s important to remember that if you want to return a value by interface, you had best hope it can get inlined, so the compiler can promote the heap allocation to the stack.
The last thing to look at are Go’s function pointers. For the longest time, I assumed they had the same layout as an interface: a pointer to closure data, and a hardware function pointer.
It turns out the layout is weirder: let’s revisit the runtime.funcval we found in runtime2.go earlier.
packageruntimetypefuncvalstruct{fnuintptr// variable-size, fn-specific data here}
To call f, first we interpret it as a *funcval and load f.fn into a temporary. That is, the first word pointed to by rax (which holds f on function entry). Then, we place f in rdx, the closure context register. The reason for using this extra magic register will become clear shorter. Then, we arrange the rest of the arguments in their usual registers, and we jump to the address stored in f.fn.
Inside of f, captures are accessed by offsetting from rdx. What does one of those closures look like?
foo.Capture:cmprsp,[r14+16]jlsgrowpushrpbmovrpb,rspaddrsp,-16mov[rsp],raxlearax,["type:noalg.struct { F uintptr; X0 int }"]callruntime.newobjectlearcx,foo.Capture.func1mov[rax],rcxmovrcx,[rsp]mov[rax+8],rcxaddrsp,16poprbpretgrow:// Same as before.jmpfoo.Capturefoo.Capture.func1:movrcx,[rdx+8]imulrax,rcxret
All Capture is doing is allocating a funcval with a single int capture; that’s the { F uintptr; X0 int } in the code above. It then places the address of Capture.func1, which implements the callback, into F, and the argument of Capture into X0.
What about when returning a reference to a function? In that case, all that happens is it returns a reference to a global containing the address of the function.
Because we pass the closure arguments in an extra register not used by regular functions, we don’t need to create a thunk for this case.
Unfortunately, we do need to create a thunk for methods, even methods with a pointer receiver. This is because of the following incompatible constraints:
The receiver pointer for a method must point exactly to the value the method is called on. It can’t be a fixed offset before, because that would create an out-of-bounds pointer, which the GC does not tolerate.
The closure pointer must point to the start of the funcval, not its captures, because adjusting the pointer to point to the captures would cause it to point one-past-the-end of a value, which the GC also does not tolerate!
Thus, even if methods accepted a pointer receiver via rdx, closures and methods disagree about where that pointer should be passed.
Of course, there are adjustments we can make to fix this problem. For example, we could require that all funcval values have at least one capture. No-capture funcvals would have a synthetic _ byte field. This is not unlike how a non-empty struct whose final field is empty will be padded with an extra _ byte field: this is specifically to avoid a pointer to that field being a past-the-end pointer. The cost is that every non-capturing closure costs twice as much binary size.
Another fix is to make the GC blind to the pointer in rdx. This will never be the only pointer by which a value is reachable, so it would be safe to replace mov rdx, rax with a lea rdx, [rax + 8]. The GC would never know!
Until then, beware that writing return foo.Method secretly allocates 16 bytes or so. (Aside: I used to sit next to the Go team at Google, and I remember having a conversation with Austin Clements about this. Apparently I misremembered, because until recently I thought Go already implemented this optimization!)
If you made it this far this is probably you right now:
This isn’t intended to be as polished as most of my articles, but there’s been enough things I’ve come across that I wanted to write this all up for my own reference.
Sizeof and Alignof are intrinsics, so the compiler will turn them into constants. However, they are only constants if the type being measured is not generic, so wrapping them in a function like this doesn’t actually hurt in generic code. ↩
Except for very large types that would have more words than can be recorded by an array of size abi.MaxPtrmaskBytes. For larger types, we use GC programs! A GC program is an LZ-compressed bitset serving the same purpose as the pointer bitset most smaller types use. See gcprog.go.
In fact, reflection knows how to create programs on the fly for most types! See reflect/type.go. ↩
I will be writing assembly examples in Intel-syntax x86. Go’s assembly syntax is horrible and an impediment to the point I’m making. ↩
Maybe? Well, the cache will only get updated about 0.1% of the time. This is to amortize the costs of growing the cache. I assume they benchmarked this, and found that the cost of growing the cache makes it only worthwhile when that assertion is getting hammered. ↩
JSON is extremely popular but deeply flawed. This article discusses the details of JSON’s design, how it’s used (and misused), and how seemingly helpful “human readability” features cause headaches instead. Crucially, you rarely find JSON-based tools (except dedicated tools like jq) that can safely handle arbitrary JSON documents without a schema—common corner cases can lead to data corruption!
JSON is famously simple. In fact, you can fit the entire grammar on the back of a business card. It’s so omnipresent in REST APIs that you might assume you already know JSON quite well. It has decimal numbers, quoted strings, arrays with square brackets, and key-value maps (called “objects”) with curly braces. A JSON document consists of any of these constructs: null, 42, and {"foo":"bar"} are all valid JSON documents.
However, the formal definition of JSON is quite complicated. JSON is defined by the IETF document RFC8259 (if you don’t know what the IETF is, it’s the standards body for Internet protocols). However, it’s also normatively defined by ECMA-404, which is from ECMA, the standards body that defines JavaScript[^json.org].
[^json.org]: Of course, some wise guy will probably want to cite . I should underscore: is __NOT__ a standard. It is __NOT__ normative. the documents produced by the IETF and by ECMA, which are international standards organizations that represent the industry __ARE__ normative. When a browser implementer wants to implement JSON to the letter, they go to ECMA, not to some dude's 90's ass website.
JavaScript? Yes, JSON (JavaScript Object Notation) is closely linked with JavaScript and is, in fact, (almost) a subset of it. While JSON’s JavaScript ancestry is the main source of its quirks, several other poor design decisions add additional unforced errors.
However, the biggest problem with JSON isn’t any specific design decision but rather the incredible diversity of parser behavior and non-conformance across and within language ecosystems. RFC8259 goes out of its way to call this out:
JSON numbers are encoded in decimal, with an optional minus sign, a fractional part after a decimal point, and a scientific notation exponent. This is similar to how many programming languages define their own numeric literals.
Presumably, JSON numbers are meant to be floats, right?
Wrong.
RFC8259 reveals that the answer is, unfortunately, “whatever you want.”
This specification allows implementations to set limits on the range and precision of numbers accepted. Since software that implements IEEE 754 binary64 (double precision) numbers is generally available and widely used, good interoperability can be achieved by implementations that expect no more precision or range than these provide, in the sense that implementations will approximate JSON numbers within the expected precision.
binary64 is the “standards-ese” name for the type usually known as double or float64. Floats have great dynamic range but often can’t represent exact values. For example, 1.1 isn’t representable as a float because all floats are fractions of the form n / 2^m for integers n and m, but 1.1 = 11/10, which has a factor of 5 in its denominator. The closest float64 value is
Of course, you might think to declare “all JSON values map to their closest float64 value”. Unfortunately, this value might not be unique. For example, the value 900000000000.00006103515625 isn’t representable as a float64, and it’s precisely between two exact float64 values. Depending on the rounding mode, this rounds to either or 900000000000 or 900000000000.0001220703125 .
IEEE 754 recommends “round ties to even” as the default rounding mode, so for almost all software, the result is 900000000000. But remember, floating-point state is a global variable implemented in hardware, and might just happen to be clobbered by some dependency that calls fesetround() or a similar system function.
You’re probably thinking, “I don’t care about such fussy precision stuff. None of my numbers have any fractional parts—and there is where you would be wrong. The n part of n / 2^m only has 53 bits available, but int64 values fall outside of that range. This means that for very large 64-bit integers, such as randomly generated IDs, a JSON parser that converts integers into floats results in data loss. Go’s encoding/json package does this, for example.
How often does this actually happen for randomly-generated numbers? We can do a little Monte Carlo simulation to find out.
It turns out that almost all randomly distributed int64 values are affected by round-trip data loss. Roughly, the only numbers that are safe are those with at most 16 digits (although not exactly: 9,999,999,999,999,999, for example, gets rounded up to a nice round 10 quadrillion).
How does this affect you? Suppose you have a JSON document somewhere that includes a user ID and a transcript of their private messages with another user. Data loss due to rounding would result in the wrong user ID being associated with the private messages, which could result in leaking PII or incorrect management of privacy consent (such as GDPR requirements).
This isn’t just about your user IDs, mind you. Plenty of other vendors’ IDs are nice big integers, which the JSON grammar can technically accommodate and which random tools will mangle. Some examples:
License keys: for example, Adobe uses 24 digits for their serial numbers, which may be tempting to store as an integer.
Visa and Mastercard credit card numbers happen to fit in the “safe” range for binary64 , which may lull you into a false sense of security, since they’re so common. But not all credit cards have 16 digit numbers: some now support 19.
These are pretty bad compliance consequences purely due to a data serialization format.
This problem is avoidable with care. After all, Go can parse JSON into any arbitrary type using reflection. For example, if we replace the inner loop of the Monte Carlo simulation with something like the following:
We suddenly see that x == y in every trial. This is because with type information, Go’s JSON library knows exactly what the target precision is. If we were parsing to an any instead of to a struct { N int64 }, we’d be in deep trouble: the outer object would be parsed into a map[string]any, and the N field would become a float64.
This means that your system probably can’t safely handle JSON documents with unknown fields. Tools like jq must be extremely careful about number handling to avoid data loss. This is an easy mistake for third-party tools to make.
But again, float64 isn’t the standard—there is no standard. Some implementations might only have 32-bit floats available, making the problem worse. Some implementations might try to be clever, using a float64 for fractional values and an int64 for integer values; however, this still imposes arbitrary limits on the parsed values, potentially resulting in data loss.
Some implementations such as Python use bignums, so they appear not to have this problem. However, this can lead to a false sense of security where issues are not caught until it’s too late: some database now contains ostensibly valid but non-interoperable JSON.
Protobuf is forced to deal with this in a pretty non-portable way. To avoid data loss, large 64-bit integers are serialized as quoted strings when serializing to JSON. So, instead of writing {"foo":6574404881820635023}, it emits {"foo":"6574404881820635023"}. This solves the data loss issue but does not work with other JSON libraries such as Go’s, producing errors like this one:
json: cannot unmarshal string into Go struct field .N of type int64
The special floating point values Infinity, -Infinity, and NaN are not representable: it’s the wild west as to what happens when you try to serialize the equivalent of {x:1.0/0.0}.
Go refuses to serialize, citing json: unsupported value: +Inf.
Protobuf serializes it as {"x":"inf"} (or should—it’s unclear which implementations get it right).
JavaScript won’t even bother trying: JSON.stringify({x:Infinity}) prints {"x":null}.
Python is arguably the worst offender: json.dumps({"x":float("inf")}) prints {"x":Infinity}, which isn’t even valid JSON per RFC8259.
NaN is arguably an even worse offender, because the NaN payload (yes, NaNs have a special payload) is discarded when converting to "nan" or however your library represents it.
Does this affect you? Well, if you’re doing anything with floats, you’re one division-by-zero or overflow away from triggering serialization errors. At best, it’s “benign” data corruption (JavaScript). At worst, when the data is partially user-controlled, it might result in crashes or unparseable output, which is the making of a DoS vector.
In comparison, Protobuf serialization can’t fail except due to non-UTF-8 string fields or cyclic message references, both of which are comparatively unlikely to a NaN popping up in a calculation.
The upshot is that all the parsers end up parsing a bunch of crazy things for the special floating-point values over time because of Postel’s law. RFC8259 makes no effort to provide suggestions for dealing with such real-world situations beyond “tough luck, not interoperable.”
JSON strings are relatively tame, with some marked (but good) divergence from JavaScript. Specifically, JavaScript, being a language of a certain age (along with Java), uses UTF-16 as its Unicode text encoding. Most of the world has realized this is a bad idea (it doubles the size of ASCII text, which makes up almost all of Internet traffic), so JSON uses UTF-8 instead. RFC8259 actually specifies that the whole document MUST be encoded in UTF-8.
But when we go to read about Unicode characters in §8.2, we are disappointed: it merely says that it’s really great when all quoted strings consist entirely of Unicode characters, which means that unpaired surrogates are allowed. In effect, the spec merely requires that JSON strings be WTF-8: UTF-8 that permits unpaired surrogates.
What’s an unpaired surrogate? It’s any encoded Unicode 32-bit value in the range U+D800 to U+DFFF , which form a gap in the Unicode codepoint range. UTF-8’s variable-length integer encoding can encode them, but their presence in a bytestream makes it invalid UTF-8. WTF-8 is UTF-8 but permitting the appearance of these values.
So, who actually supports parsing (or serializing) these? Consider the document {"x":"\udead"}, which contains an unpaired surrogate, U+DEAD.
Go gladly deserializes AND serializes it (Go’s strings are arbitrary byte strings, not UTF-8). However, Go serializes a non-UTF-8 string such as "\xff" as "\ufffd", having replaced the invalid byte with a U+FFFD replacement character (this thing: �).
Most Java parsers seem to follow the same behavior as Go, but there are many different parsers available, and we’ve already learned that different JSON parsers may behave differently.
JavaScript and Python similarly gladly parse unpaired surrogates, but they also serialize them back without converting them into U+FFFD.
Different Protobuf runtimes may not handle this identically, but the reference C++ implementation (whose JSON codec I wrote!) refuses to parse unpaired surrogates.
There are other surprising pitfalls around strings: are "x" and “\x78" the same string? RFC8259 feels the need to call out that they are, for the purposes of checking that object keys are equal. The fact that they feel the need to call it out indicates that this is also a source of potential problems.
What if I don’t want to send text? A common type of byte blob to send is a cryptographic hash that identifies a document in a content-addressed blobstore, or perhaps a digital signature (an encrypted hash). JSON has no native way of representing byte strings.
You could send a quoted string full of ASCII and \xNN escapes (for bytes which are not in the ASCII range), but this is wasteful in terms of bandwidth, and has serious interoperability problems (as noted above, Go actively destroys data in this case). You could also encode it as an array of JSON numbers, which is much worse for bandwidth and serialization speed.
What everyone winds up doing, one way or another, is to rely on base64 encoding. Protobuf, for example, encodes bytes fields into base64 strings in JSON. This has the unfortunate side-effect of defeating JSON’s human-readable property: if the blob contains mostly ASCII, a human reader can’t tell.
Because this isn’t part of JSON, virtually no JSON codec does this decoding for you, particularly because in a schema-less context, there’s nothing to distinguish a byte blob encoded with base64 from an actual textual string that happens to contain valid base64, such as an alphanumeric username.
A less obvious problem with JSON is that it can’t be streamed. Almost all JSON documents are objects or arrays and are therefore incomplete until they reach the closing } or ], respectively. This means you can’t send a stream of JSON documents that form a part of a larger document without some additional protocol for combining them in post-processing.
JSONL is the world’s silliest spec that “solves” this problem in the simplest way possible: a JSONL document is a sequence of JSON documents separated by newlines. JSONL is streamable, but because it’s done in the simplest way possible, it only supports streaming a giant array. You can’t, for example, stream an object field-by-field or stream an array within that object.
Protobuf doesn’t have this problem: in a nutshell, the Protobuf wire format is as if we removed the braces and brackets from the top-level array or object of a document, and made it so that values with the same key get merged. In the wire format, the equivalent of the JSONL document
This forms the basis of the “message merge” operation, which is intimately connected to how the wire format was designed. We’ll dive into this fundamental operation in a future article.
Thanks to RFC7519 and RFC7515, which define JSON Web Tokens (JWT) and JSON Web Signatures (JWS), digitally signing JSON documents is a very common operation. However, digital signatures can only sign specific byte blobs and are sensitive to things that JSON isn’t, such as whitespace and key ordering.
This results in specifications like RFC8785 for canonicalization of JSON documents. This introduces a new avenue by which existing JSON documents, which accidentally happen to contain non-interoperable (or, thanks to non-conforming implementations such as Python’s) invalid JSON that must be manipulated and reformatted by third-party tools. RFC8785 itself references ECMA-262 (the JavaScript standard) for how to serialize numbers, meaning that it’s required to induce data loss for 64-bit numerical values!
Plainly? No. JSON can’t be fixed because of how extremely popular it is. Common mistakes are baked into the format. Are comments allowed? Trailing commas? Number formats? Nobody knows!
What tools are touching your JSON? Are they aware of all of the rakes they can step on? Do they emit invalid JSON (like Python does)? How do you even begin to audit that?
Thankfully, you don’t have to use JSON. There are alternatives—BSON, UBJSON, MessagePack, and CBOR are just a few binary formats that try to replicate JSON’s data model. Unfortunately, many of them have their own problems.
Protobuf, however, has none of these problems, because it was designed to fulfill needs JSON couldn’t meet. Using a strongly-typed schema system, like Protobuf, makes all of these problems go away.
I will often say that the so-called “C ABI” is a very bad one, and a relatively unimaginative one when it comes to passing complicated types effectively. A lot of people ask me “ok, what would you use instead”, and I just point them to the Go register ABI, but it seems most people have trouble filling in the gaps of what I mean. This article explains what I mean in detail.
I have discussed calling conventions in the past, but as a reminder: the calling convention is the part of the ABI that concerns itself with how to pass arguments to and from a function, and how to actually call a function. This includes which registers arguments go in, which registers values are returned out of, what function prologues/epilogues look like, how unwinding works, etc.
This particular post is primarily about x86, but I intend to be reasonably generic (so that what I’ve written applies just as well to ARM, RISC-V, etc). I will assume a general familiarity with x86 assembly, LLVM IR, and Rust (but not rustc’s internals).
Today, like many other natively compiled languages, Rust defines an unspecified0- calling convention that lets it call functions however it likes. In practice, Rust lowers to LLVM’s built-in C calling convention, which LLVM’s prologue/epilogue codegen generates calls for.
Rust is fairly conservative: it tries to generate LLVM function signatures that Clang could have plausibly generated. This has two significant benefits:
Good probability debuggers won’t choke on it. This is not a concern on Linux, though, because DWARF is very general and does not bake-in the Linux C ABI. We will concern ourselves only with ELF-based systems and assume that debuggability is a nonissue.
It is less likely to tickle LLVM bugs due to using ABI codegen that Clang does not exercise. I think that if Rust tickles LLVM bugs, we should actually fix them (a very small number of rustc contributors do in fact do this).
However, we are too conservative. We get terrible codegen for simple functions:
arr is 12 bytes wide, so you’d think it would be passed in registers, but no! It is passed by pointer! Rust is actually more conservative than what the Linux C ABI mandates, because it actually passes the [i32; 3] in registers when extern "C" is requested.
The array is passed in rdi and rsi, with the i32s packed into registers. The function moves rdi into rax, the output register, and shifts the upper half down.
Not only does clang produce patently bad code for passing things by value, but it also knows how to do it better, if you request a standard calling convention! We could be generating way better code than Clang, but we don’t!
Let’s suppose that we keep the current calling convention for extern "Rust"1, but we add a flag -Zcallconv that sets the calling convention for extern "Rust" when compiling a crate. The supported values will be -Zcallconv=legacy for the current one, and -Zcallconv=fast for the one we’re going to design. We could even let -O set -Zcallconv=fast automatically.
Why keep the old calling convention? Although I did sweep debugability under the rug, one nice property -Zcallconv=fast will not have is that it does not place arguments in the C ABI order, which means that a reader replying on the “Diana’s silk dress cost $89” mnemonic on x86 will get fairly confused.
I am also assuming we may not even support -Zcallconv=fast for some targets, like WASM, where there is no concept of “registers” and “spilling”. It may not even make sense to enable it for for debug builds, because it will produce much worse code with optimizations turned off.
There is also a mild wrinkle with function pointers, and extern "Rust" {} blocks. Because this flag is per-crate, even though functions can advertise which version of extern "Rust" they use, function pointers have no such luxury. However, calling through a function pointer is slow and rare, so we can simply force them to use -Zcallconv=legacy. We can generate a shim to translate calling conventions as needed.
Similarly, we can, in principle, call any Rust function like this:
However, this mechanism can only be used to call unmangled symbols. Thus, we can simply force #[no_mangle] symbols to use the legacy calling convention.
In an ideal world, LLVM would provide a way for us to specify the calling convention directly. E.g., this argument goes in that register, this return goes in that one, etc. Unfortunately, adding a calling convention to LLVM requires writing a bunch of C++.
However, we can get away with specifying our own calling convention by following the following procedure.
First, determine, for a given target triple, the maximum number of values that can be passed “by register”. I will explain how to do this below.
Decide how to pass the return value. It will either fit in the output registers, or it will need to be returned “by reference”, in which case we pass an extra ptr argument to the function (tagged with the sret attribute) and the actual return value of the function is that pointer.
Decide which arguments that have been passed by value need to be demoted to being passed by reference. This will be a heuristic, but generally will be approximately “arguments larger than the by-register space”. For example, on x86, this comes out to 176 bytes.
Decide which arguments get passed by register, so as to maximize register space usage. This problem is NP-hard (it’s the knapsack problem) so it will require a heuristic. All other arguments are passed on the stack.
Generate the function signature in LLVM IR. This will be all of the arguments that are passed by register encoded as various non-aggregates, such as i64, ptr, double, and <2 x i64>. What valid choices are for said non-aggregates depends on the target, but the above are what you will generally get on a 64-bit architecture. Arguments passed on the stack will follow the “register inputs”.
Generate a function prologue. This is code to decode each Rust-level argument from the register inputs, so that there are %ssa values corresponding to those that would be present when using -Zcallconv=legacy. This allows us to generate the same code for the body of the function regardless of calling convention. Redundant decoding code will be eliminated by DCE passes.
Generate a function exit block. This is a block that contains a single phi instruction for the return type as it would be for -Zcallconv=legacy. This block will encode it into the requisite output format and then ret as appropriate. All exit paths through the function should br to this block instead of ret-ing.
If a non-polymorphic, non-inline function may have its address taken (as a function pointer), either because it is exported out of the crate or the crate takes a function pointer to it, generate a shim that uses -Zcallconv=legacy and immediately tail-calls the real implementation. This is necessary to preserve function pointer equality.
The main upshot here is that we need to cook up heuristics for figuring out what goes in registers (since we allow reordering arguments to get better throughput). This is equivalent to the knapsack problem; knapsack heuristics are beyond the scope of this article. This should happen early enough that this information can be stuffed into rmeta to avoid needing to recompute it. We may want to use different, faster heuristics depending on -Copt-level. Note that correctness requires that we forbid linking code generated by multiple different Rust compilers, which is already the case, since Rust breaks ABI from release to release.
Assuming we do that, how do we actually get LLVM to pass things in the way we want it to? We need to determine what the largest “by register” passing LLVM will permit is. The following LLVM program is useful for determining this on a particular version of LLVM:
When you pass an aggregate by-value to an LLVM function, LLVM will attempt to “explode” that aggregate into as many registers as possible. There are distinct register classes on different systems. For example, on both x86 and ARM, floats and vectors share the same register class (kind of2).
The above values are for x863. LLVM will pass six integers and eight SSE vectors by register, and return half as many (3 and 4) by register. Increasing any of the values generates extra loads and stores that indicate LLVM gave up and passed arguments on the stack.
The values for aarch64-unknown-linux are 8 integers and 8 vectors for both inputs and outputs, respectively.
This is the maximum number of registers we get to play with for each class. Anything extra gets passed on the stack.
I recommend that every function have the same number of by-register arguments. So on x86, EVERY -Zcallconv=fast function’s signature should look like this:
declare{[3xi64],[4x<2xi64>]}@my_func(i64%rdi,i64%rsi,i64%rdx,i64%rcx,i64%r8,i64%r9,<2xi64>%xmm0,<2xi64>%xmm1,<2xi64>%xmm2,<2xi64>%xmm3,<2xi64>%xmm4,<2xi64>%xmm5,<2xi64>%xmm6,<2xi64>%xmm7,; other args...)
When passing pointers, the appropriate i64s should be replaced by ptr, and when passing doubles, they replace <2 x i64>s.
But you’re probably saying, “Miguel, that’s crazy! Most functions don’t pass 176 bytes!” And you’d be right, if not for the magic of LLVM’s very well-specified poison semantics.
We can get away with not doing extra work if every argument we do not use is passed poison. Because poison is equal to “the most convenient possible value at the present moment”, when LLVM sees poison passed into a function via register, it decides that the most convenient value is “whatever happens to be in the register already”, and so it doesn’t have to touch that register!
For example, if we wanted to pass a pointer via rcx, we would generate the following code.
; This is a -Zcallconv=fast-style function.%Out=type{[3xi64],[4x<2xi64>]}define%Out@load_rcx(i64%rdi,i64%rsi,i64%rdx,ptr%rcx,i64%r8,i64%r9,<2xi64>%xmm0,<2xi64>%xmm1,<2xi64>%xmm2,<2xi64>%xmm3,<2xi64>%xmm4,<2xi64>%xmm5,<2xi64>%xmm6,<2xi64>%xmm7){%load=loadi64,ptr%rcx%out=insertvalue%Outpoison,i64%load,0,0ret%Out%out}declareptr@malloc(i64)definei64@make_the_call(){%1=callptr@malloc(i648)storei6442,ptr%1%2=call%Out@by_rcx(i64poison,i64poison,i64poison,ptr%1,i64poison,i64poison,<2xi64>poison,<2xi64>poison,<2xi64>poison,<2xi64>poison,<2xi64>poison,<2xi64>poison,<2xi64>poison,<2xi64>poison)%3=extractvalue%Out%2,0,0%4=addi64%3,42reti64%4}
It is perfectly legal to pass poison to a function, if it does not interact with the poisoned argument in any proscribed way. And as we see, load_rcx() receives its pointer argument in rcx, whereas make_the_call() takes no penalty in setting up the call: loading poison into the other thirteen registers compiles down to nothing4, so it only needs to load the pointer returned by malloc into rcx.
This gives us almost total control over argument passing; unfortunately, it is not total. In an ideal world, the same registers are used for input and output, to allow easier pipelining of calls without introducing extra register traffic. This is true on ARM and RISC-V, but not x86. However, because register ordering is merely a suggestion for us, we can choose to allocate the return registers in whatever order we want. For example, we can pretend the order registers should be allocated in is rdx, rcx, rdi, rsi, r8, r9 for inputs, and rdx, rcx, rax for outputs.
square generates extremely simple code: the input and output register is rdi, so no extra register traffic needs to be generated. Similarly, when we effectively do @square(@square(%0)), there is no setup between the functions. This is similar to code seen on aarch64, which uses the same register sequence for input and output. We can see that the “naive” version of this IR produces the exact same code on aarch64 for this reason.
Now that we’ve established total control on how registers are assigned, we can turn towards maximizing use of these registers in Rust.
For simplicity, we can assume that rustc has already processed the users’s types into basic aggregates and unions; no enums here! We then have to make some decisions about which portions of the arguments to allocate to registers.
First, return values. This is relatively straightforward, since there is only one value to pass. The amount of data we need to return is not the size of the struct. For example, [(u64, u32); 2] measures 32 bytes wide. However, eight of those bytes are padding! We do not need to preserve padding when returning by value, so we can flatten the struct into (u64, u32, u64, u32) and sort by size into (u64, u64, u32, u32). This has no padding and is 24 bytes wide, which fits into the three return registers LLVM gives us on x86. We define the effective size of a type to be the number of non-undef bits it occupies. For [(u64, u32); 2], this is 192 bits, since it excludes the padding. For bool, this is one. For char this is technically 21, but it’s simpler to treat char as an alias for u32.
The reason for counting bits this way is that it permits significant compaction. For example, returning a struct full of bools can simply bit-pack the bools into a single register.
So, a return value is converted to a by-ref return if its effective size is smaller than the output register space (on x86, this is three integer registers and four SSE registers, so we get 88 bytes total, or 704 bits).
Argument registers are much harder, because we hit the knapsack problem, which is NP-hard. The following relatively naive heuristic is where I would start, but it can be made infinitely smarter over time.
First, demote to by-ref any argument whose effective size is larget than the total by-register input space (on x86, 176 bytes or 1408 bits). This means we get a pointer argument instead. This is beneficial to do first, since a single pointer might pack better than the huge struct.
Enums should be replaced by the appropriate discriminant-union pair. For example, Option<i32> is, internally, (union { i32, () }, i1), while Option<Option<i32>> is (union { i32, (), () }, i2). Using a small non-power-of-two integer improves our ability to pack things, since enum discriminants are often quite tiny.
Next, we need to handle unions. Because mucking about with unions’ uninitialized bits behind our backs is allowed, we need to either pass it as an array of u8, unless it only has a single non-empty variant, in which case it is replaced with that variant5.
Now, we can proceed to flatten everything. All of the converted arguments are flattened into their most primitive components: pointers, integers, floats, and bools. Every field should be no larger than the smallest argument register; this may require splitting large types such as u128 or f64.
This big list of primitives is next sorted by effective size, from smallest to largest. We take the largest prefix of this that will fit in the available register space; everything else goes on the stack.
If part of a Rust-level input is sent to the stack in this way, and that part is larger than a small multiple of the pointer size (e.g., 2x), it is demoted to being passed by pointer-on-the-stack, to minimize memory traffic. Everything else is passed directly on the stack in the order those inputs were before the sort. This helps keep regions that need to be copied relatively contiguous, to minimize calls to memcpy.
The things we choose to pass in registers are allocated to registers in reverse size order, so e.g. first 64-bit things, then 32-bit things, etc. This is the same layout algorithm that repr(Rust) structs use to move all the padding into the tail. Once we get to the bools, those are bit-packed, 64 to a register.
Here’s a relatively complicated example. My Rust function is as follows:
The codegen for this function is quite complex, so I’ll only cover the prologue and epilogue. After sorting and flattening, our raw argument LLVM types are something like this:
Everything fits in registers! So, what does the LLVM function look like on x86?
%Out=type{[3xi64],[4x<2xi64>]}define%Out@do_thing(i64%rdi,ptr%rsi,ptr%rdx,ptr%rcx,i64%r8,i64%r9,<4xi32>%xmm0,<4xi32>%xmm1,; Unused.<2xi64>%xmm2,<2xi64>%xmm3,<2xi64>%xmm4,<2xi64>%xmm5,<2xi64>%xmm6,<2xi64>%xmm7){; First, unpack all the primitives.%r9.0=trunci64%r9toi32%r9.1.i64=lshri64%r9,32%r9.1=trunci64%r9.1.i64toi32%xmm0.0=extractelement<4xi32>%xmm0,i320%xmm0.1=extractelement<4xi32>%xmm0,i321%xmm0.2=extractelement<4xi32>%xmm0,i322%xmm0.3=extractelement<4xi32>%xmm0,i323%xmm1.0=extractelement<4xi32>%xmm1,i320%xmm1.1=extractelement<4xi32>%xmm1,i321%xmm1.1.0=trunci32%xmm1.1toi1%xmm1.1.1.i32=lshri32%xmm1.1,1%xmm1.1.1=trunci32%xmm1.1.1.i32toi1%xmm1.1.2.i32=lshri32%xmm1.1,2%xmm1.1.2=trunci32%xmm1.1.2.i32toi1%xmm1.1.3.i32=lshri32%xmm1.1,3%xmm1.1.3=trunci32%xmm1.1.3.i32toi1; Next, reassemble them into concrete values as needed.%op_count.0=insertvalue{i64,i1}poison,i64%rdi,0%op_count=insertvalue{i64,i1}%op_count.0,i1%xmm1.1.0,1%context.0=insertvalue{ptr,ptr}poison,ptr%rsi,0%context=insertvalue{ptr,ptr}%context.0,ptr%rdx,1%name.0=insertvalue{ptr,i64}poison,ptr%rcx,0%name=insertvalue{ptr,i64}%name.0,i64%r8,1%code.0=insertvalue[6xi32]poison,i32%r9.0,0%code.1=insertvalue[6xi32]%code.0,i32%r9.1,1%code.2=insertvalue[6xi32]%code.1,i32%xmm0.0,2%code.3=insertvalue[6xi32]%code.2,i32%xmm0.1,3%code.4=insertvalue[6xi32]%code.3,i32%xmm0.2,4%code=insertvalue[6xi32]%code.4,i32%xmm0.3,5%options.0=insertvalue{i32,i1,i1,i1}poison,i32%xmm1.0,0%options.1=insertvalue{i32,i1,i1,i1}%options.0,i1%xmm1.1.1,1%options.2=insertvalue{i32,i1,i1,i1}%options.1,i1%xmm1.1.2,2%options=insertvalue{i32,i1,i1,i1}%options.2,i1%xmm1.1.3,3; Codegen as usual.; ...}
Above, !dbg metadata for the argument values should be attached to the instruction that actually materializes it. This ensures that gdb does something halfway intelligent when you ask it to print argument values.
On the other hand, in current rustc, it gives LLVM eight pointer-sized parameters, so it winds up spending all six integer registers, plus two values passed on the stack. Not great!
This is not a complete description of what a completely over-engineered calling convention could entail: in some cases we might know that we have additional registers available (such as AVX registers on x86). There are cases where we might want to split a struct across registers and the stack.
This also isn’t even getting into what returns could look like. Results are often passed through several layers of functions via ?, which can result in a lot of redundant register moves. Often, a Result is large enough that it doesn’t fit in registers, so each call in the ? stack has to inspect an ok bit by loading it from memory. Instead, a Result return might be implemented as an out-parameter pointer for the error, with the ok variant’s payload, and the is ok bit, returned as an Option<T>. There are some fussy details with Into calls via ?, but the idea is implementable.
Now, because we’re Rust, we’ve also got a trick up our sleeve that C doesn’t (but Go does)! When we’re generating the ABI that all callers will see (for -Zcallconv=fast), we can look at the function body. This means that a crate can advertise the precise ABI (in terms of register-passing) of its functions.
This opens the door to a more extreme optimization-based ABIs. We can start by simply throwing out unused arguments: if the function never does anything with a parameter, don’t bother spending registers on it.
Another example: suppose that we know that an &T argument is not retained (a question the borrow checker can answer at this point in the compiler) and is never converted to a raw pointer (or written to memory a raw pointer is taken of, etc). We also know that T is fairly small, and T: Freeze. Then, we can replace the reference with the pointee directly, passed by value.
The most obvious candidates for this is APIs like HashMap::get(). If the key is something like an i32, we need to spill that integer to the stack and pass a pointer to it! This results in unnecessary, avoidable memory traffic.
Profile-guided ABI is a step further. We might know that some arguments are hotter than others, which might cause them to be prioritized in the register allocation order.
You could even imagine a case where a function takes a very large struct by reference, but three i64 fields are very hot, so the caller can preload those fields, passing them both by register and via the pointer to the large struct. The callee does not see additional cost: it had to issue those loads anyway. However, the caller probably has those values in registers already, which avoids some memory traffic.
Instrumentation profiles may even indicate that it makes sense to duplicate whole functions, which are identical except for their ABIs. Maybe they take different arguments by register to avoid costly spills.
This is a bit more advanced (and ranty) than my usual writing, but this is an aspect of Rust that I find really frustrating. We could be doing so much better than C++ ever can (because of their ABI constraints). None of this is new ideas; this is literally how Go does it!
So why don’t we? Part of the reason is that ABI codegen is complex, and as I described above, LLVM gives us very few useful knobs. It’s not a friendly part of rustc, and doing things wrong can have nasty consequences for usability. The other part is a lack of expertise. As of writing, only a handful of people contributing to rustc have the necessary grasp of LLVM’s semantics (and mood swings) to emit the Right Code such that we get good codegen and don’t crash LLVM.
Another reason is compilation time. The more complicated the function signatures, the more prologue/epilogue code we have to generate that LLVM has to chew on. But -Zcallconv is intended to only be used with optimizations turned on, so I don’t think this is a meaningful complaint. Nor do I think the project’s Goodhartization of compilation time as a metric is healthy… but I do not think this is ultimately a relevant drawback.
I, unfortunately, do not have the spare time to dive into fixing rustc’s ABI code, but I do know LLVM really well, and I know that this is a place where Rust has a low bus factor. For that reason, I am happy to provide the Rust compiler team expert knowledge on getting LLVM to do the right thing in service of making optimized code faster.
Or just switch it to the codepath for extern "C" or extern "fastcall" since those are clearly better. We will always need to know how to generate code for the non-extern "Rust" calling conventions. ↩
It’s Complicated. Passing a double burns a whole <2 x i64> slot. This seems bad, but it can be beneficial since keeping a double in vector registers reduces register traffic, since usually, fp instructions use the vector registers (or the fp registers shadow the vector registers, like on ARM). ↩
On the one hand, you might say this “extended calling convention” isn’t an explicitly supported part of LLVM’s ccc calling convention. On the other hand, Hyrum’s Law cuts both ways: Rust is big enough of an LLVM user that LLVM cannot simply miscompile all Rust programs at this point, and the IR I propose Rust emits is extremely reasonable.
If Rust causes LLVM to misbehave, that’s an LLVM bug, and we should fix LLVM bugs, not work around them. ↩
Only on -O1 or higher, bizarrely. At -O0, LLVM decides that all of the poisons must have the same value, so it copies a bunch of registers around needlessly. This seems like a bug? ↩
There are other cases where we might want to replace a union with one of its variants: for example, there’s a lot of cases where Result<&T, Error> is secretly a union { ptr, u32 }, in which case it should be replaced with a single ptr. ↩
Another explainer on a fun, esoteric topic: optimizing code with SIMD (single instruction multiple data, also sometimes called vectorization). Designing a good, fast, portable SIMD algorithm is not a simple matter and requires thinking a little bit like a circuit designer.
Here’s the mandatory performance benchmark graph to catch your eye.
“SIMD” often gets thrown around as a buzzword by performance and HPC (high performance computing) nerds, but I don’t think it’s a topic that has very friendly introductions out there, for a lot of reasons.
It’s not something you will really want to care about unless you think performance is cool.
APIs for programming with SIMD in most programming languages are garbage (I’ll get into why).
SIMD algorithms are hard to think about if you’re very procedural-programming-brained. A functional programming mindset can help a lot.
This post is mostly about vb64 (which stands for vector base64), a base64 codec I wrote to see for myself if Rust’s std::simd library is any good, but it’s also an excuse to talk about SIMD in general.
What is SIMD, anyways? Let’s dive in.
If you want to skip straight to the writeup on vb64, click here.
Unfortunately, computers exist in the real world[citation-needed], and are bound by the laws of nature. SIMD has relatively little to do with theoretical CS considerations, and everything to do with physics.
In the infancy of modern computing, you could simply improve performance of existing programs by buying new computers. This is often incorrectly attributed to Moore’s law (the number of transistors on IC designs doubles every two years). Moore’s law still appears to hold as of 2023, but some time in the last 15 years the Dennard scaling effect broke down. This means that denser transistors eventually means increased power dissipation density. In simpler terms, we don’t know how to continue to increase the clock frequency of computers without literally liquefying them.
So, since the early aughts, the hot new thing has been bigger core counts. Make your program more multi-threaded and it will run faster on bigger CPUs. This comes with synchronization overhead, since now the cores need to cooperate. All control flow, be it jumps, virtual calls, or synchronization will result in “stall”.
The main causes of stall are branches, instructions that indicate code can take one of two possible paths (like an if statement), and memory operations. Branches include all control flow: if statements, loops, function calls, function returns, even switch statements in C. Memory operations are loads and stores, especially ones that are cache-unfriendly.
There’s no reason for the CPU to wait to finish computing a before it begins computing b; it does not depend on a, and while the add is being executed, the xor circuits are idle. Computers say “program order be damned” and issue the add for a and the xor for b simultaneously. This is called instruction-level parallelism, and dependencies that get in the way of it are often called data hazards.
Of course, the Zen 2 in the machine I’m writing this with does not have one measly adder per core. It has dozens and dozens! The opportunities for parallelism are massive, as long as the compiler in your CPU’s execution pipeline can clear any data hazards in the way.
The better the core can do this, the more it can saturate all of the “functional units” for things like arithmetic, and the more numbers it can crunch per unit time, approaching maximum utilization of the hardware. Whenever the compiler can’t do this, the execution pipeline stalls and your code is slower.
Branches stall because they need to wait for the branch condition to be computed before fetching the next instruction (speculative execution is a somewhat iffy workaround for this). Memory operations stall because the data needs to physically arrive at the CPU, and the speed of light is finite in this universe.
Trying to reduce stall by improving opportunities for single-core parallelism is not a new idea. Consider the not-so-humble GPU, whose purpose in life is to render images. Images are vectors of pixels (i.e., color values), and rendering operations tend to be highly local. For example, a convolution kernel for a Gaussian blur will be two or even three orders of magnitude smaller than the final image, lending itself to locality.
Thus, GPUs are built for divide-and-conquer: they provide primitives for doing batched operations, and extremely limited control flow.
“SIMD” is synonymous with “batching”. It stands for “single instruction, multiple data”: a single instruction dispatches parallel operations on multiple lanes of data. GPUs are the original SIMD machines.
“SIMD” and “vector” are often used interchangeably. The fundamental unit a SIMD instruction (or “vector instruction”) operates on is a vector: a fixed-size array of numbers that you primarily operate on component-wise These components are called lanes.
SIMD vectors are usually quite small, since they need to fit into registers. For example, on my machine, the largest vectors are 256 bits wide. This is enough for 32 bytes (a u8x32), 4 double-precision floats (an f64x8), or all kinds of things in between.
Although this doesn’t seem like much, remember that offloading the overhead of keeping the pipeline saturated by a factor of 4x can translate to that big of a speedup in latency.
The simplest vector operations are bitwise: and, or, xor. Ordinary integers can be thought of as vectors themselves, with respect to the bitwise operations. That’s literally what “bitwise” means: lanes-wise with lanes that are one bit wide. An i32 is, in this regard, an i1x32.
In fact, as a warmup, let’s look at the problem of counting the number of 1 bits in an integer. This operation is called “population count”, or popcnt. If we view an i32 as an i1x32, popcnt is just a fold or reduce operation:
In other words, we interpret the integer as an array of bits and then add the bits together to a 32-bit accumulator. Note that the accumulator needs to be higher precision to avoid overflow: accumulating into an i1 (as with the Iterator::reduce() method) will only tell us whether the number of 1 bits is even or odd.
Of course, this produces… comically bad code, frankly. We can do much better if we notice that we can vectorize the addition: first we add all of the adjacent pairs of bits together, then the pairs of pairs, and so on. This means the number of adds is logarithmic in the number of bits in the integer.
Visually, what we do is we “unzip” each vector, shift one to line up the lanes, add them, and then repeat with lanes twice as big.
This is what that looks like in code.
pubfnpopcnt(mutx:u32)->u32{// View x as a i1x32, and split it into two vectors// that contain the even and odd bits, respectively.leteven=x&0x55555555;// 0x5 == 0b0101.letodds=x&0xaaaaaaaa;// 0xa == 0b1010.// Shift odds down to align the bits, and then add them together.// We interpret x now as a i2x16. When adding, each two-bit// lane cannot overflow, because the value in each lane is// either 0b00 or 0b01.x=even+(odds>>1);// Repeat again but now splitting even and odd bit-pairs.leteven=x&0x33333333;// 0x3 == 0b0011.letodds=x&0xcccccccc;// 0xc == 0b1100.// We need to shift by 2 to align, and now for this addition// we interpret x as a i4x8.x=even+(odds>>2);// Again. The pattern should now be obvious.leteven=x&0x0f0f0f0f;// 0x0f == 0b00001111.letodds=x&0xf0f0f0f0;// 0xf0 == 0b11110000.x=even+(odds>>4);// i8x4leteven=x&0x00ff00ff;letodds=x&0xff00ff00;x=even+(odds>>8);// i16x2leteven=x&0x0000ffff;letodds=x&0xffff0000;// Because the value of `x` is at most 32, although we interpret this as a// i32x1 add, we could get away with just one e.g. i16 add.x=even+(odds>>16);x// Done. All bits have been added.}
This still won’t optimize down to a popcnt instruction, of course. The search scope for such a simplification is in the regime of superoptimizers. However, the generated code is small and fast, which is why this is the ideal implementation of popcnt for systems without such an instruction.
It’s especially nice because it is implementable for e.g. u64 with only one more reduction step (remember: it’s O(logn)!), and does not at any point require a full u64 addition.
Even though this is “just” using scalars, divide-and-conquer approaches like this are the bread and butter of the SIMD programmer.
Proper SIMD vectors provide more sophisticated semantics than scalars do, particularly because there is more need to provide replacements for things like control flow. Remember, control flow is slow!
What’s actually available is highly dependent on the architecture you’re compiling to (more on this later), but the way vector instruction sets are usually structured is something like this.
We have vector registers that are kind of like really big general-purpose registers. For example, on x86, most “high performance” cores (like my Zen 2) implement AVX2, which provides 256 bit ymm vectors. The registers themselves do not have a “lane count”; that is specified by the instructions. For example, the “vector byte add instruction” interprets the register as being divided into eight-byte lanes and adds them. The corresponding x86 instruction is vpaddb, which interprets a ymm as an i8x32.
The operations you usually get are:
Bitwise operations. These don’t need to specify a lane width because it’s always implicitly 1: they’re bitwise.
Lane-wise arithmetic. This is addition, subtraction, multiplication, division (both int and float), and shifts1 (int only). Lane-wise min and max are also common. These require specifying a lane width. Typically the smallest number of lanes is two or four.
Lane-wise compare. Given a and b, we can create a new mask vectorm such that m[i] = a[i] < b[i] (or any other comparison operation). A mask vector’s lanes contain boolean values with an unusual bit-pattern: all-zeros (for false) or all-ones (for true)2.
Masks can be used to select between two vectors: for example, given m, x, and y, you can form a fourth vector z such that z[i] = m[i] ? a[i] : b[i].
Shuffles (sometimes called swizzles). Given a and x, create a third vector s such that s[i] = a[x[i]]. a is used as a lookup table, and x as a set of indices. Out of bounds produces a special value, usually zero. This emulates parallelized array access without needing to actually touch RAM (RAM is extremely slow).
Often there is a “shuffle2” or “riffle” operation that allows taking elements from one of two vectors. Given a, b, and x, we now define s as being s[i] = (a ++ b)[x[i]], where a ++ b is a double-width concatenation. How this is actually implemented depends on architecture, and it’s easy to build out of single shuffles regardless.
(1) and (2) are ordinary number crunching. Nothing deeply special about them.
The comparison and select operations in (3) are intended to help SIMD code stay “branchless”. Branchless code is written such that it performs the same operations regardless of its inputs, and relies on the properties of those operations to produce correct results. For example, this might mean taking advantage of identities like x * 0 = 0 and a ^ b ^ a = b to discard “garbage” results.
The shuffles described in (4) are much more powerful than meets the eye.
For example, “broadcast” (sometimes called “splat”) makes a vector whose lanes are all the same scalar, like Rust’s [42; N] array literal. A broadcast can be expressed as a shuffle: create a vector with the desired value in the first lane, and then shuffle it with an index vector of [0, 0, ...].
“Interleave” (also called “zip” or “pack”) takes two vectors a and b and creates two new vectors c and d whose lanes are alternating lanes from a and b. If the lane count is n, then c = [a[0], b[0], a[1], b[1], ...] and d = [a[n/2], b[n/2], a[n/2 + 1], b[n/2 + 1], ...]. This can also be implemented as a shuffle2, with shuffle indices of [0, n, 1, n + 1, ...]. “Deinterleave” (or “unzip”, or “unpack”) is the opposite operation: it interprets a pair of vectors as two halves of a larger vector of pairs, and produces two new vectors consisting of the halves of each pair.
Interleave can also be interpreted as taking a [T; N], transmuting it to a [[T; N/2]; 2], performing a matrix transpose to turn it into a [[T; 2]; N/2], and then transmuting that back to [T; N] again. Deinterleave is the same but it transmutes to [[T; 2]; N/2] first.
“Rotate” takes a vector a with n lanes and produces a new vector b such that b[i] = a[(i + j) % n], for some chosen integer j. This is yet another shuffle, with indices [j, j + 1, ..., n - 1, 0, 1, ... j - 1].
Shuffles are worth trying to wrap your mind around. SIMD programming is all about reinterpreting larger-than-an-integer-sized blocks of data as smaller blocks of varying sizes, and shuffling is important for getting data into the right “place”.
Earlier, I mentioned that what you get varies by architecture. This section is basically a giant footnote.
So, there’s two big factors that go into this.
We’ve learned over time which operations tend to be most useful to programmers. x86 might have something that ARM doesn’t because it “seemed like a good idea at the time” but turned out to be kinda niche.
Instruction set extensions are often market differentiators, even within the same vendor. Intel has AVX-512, which provides even more sophisticated instructions, but it’s only available on high-end server chips, because it makes manufacturing more expensive.
Toolchains generalize different extensions as “target features”. Features can be detected at runtime through architecture-specific magic. On Linux, the lscpu command will list what features the CPU advertises that it recognizes, which correlate with the names of features that e.g. LLVM understands. What features are enabled for a particular function affects how LLVM compiles it. For example, LLVM will only emit ymm-using code when compiling with +avx2.
So how do you write portable SIMD code? On the surface, the answer is mostly “you don’t”, but it’s more complicated than that, and for that we need to understand how the later parts of a compiler works.
When a user requests an add by writing a + b, how should I decide which instruction to use for it? This seems like a trick question… just an add right? On x86, even this isn’t so easy, since you have a choice between the actual add instruction, or a lea instruction (which, among other things, preserves the rflags register). This question becomes more complicated for more sophisticated operations. This general problem is called instruction selection.
Because which “target features” are enabled affects which instructions are available, they affect instruction selection. When I went over operations “typically available”, this means that compilers will usually be able to select good choices of instructions for them on most architectures.
Compiling with something like -march=native or -Ctarget-cpu=native gets you “the best” code possible for the machine you’re building on, but it might not be portable3 to different processors. Gentoo was quite famous for building packages from source on user machines to take advantage of this (not to mention that they loved using -O3, which mostly exists to slow down build times with little benefit).
There is also runtime feature detection, where a program decides which version of a function to call at runtime by asking the CPU what it supports. Code deployed on heterogenous devices (like cryptography libraries) often make use of this. Doing this correctly is very hard and something I don’t particularly want to dig deeply into here.
The situation is made worse by the fact that in C++, you usually write SIMD code using “intrinsics”, which are special functions with inscrutable names like _mm256_cvtps_epu32 that represent a low-level operation in a specific instruction set (this is a float to int cast from AVX2). Intrinsics are defined by hardware vendors, but don’t necessarily map down to single instructions; the compiler can still optimize these instructions by merging, deduplication, and through instruction selection.
As a result you wind up writing the same code multiple times for different instruction sets, with only minor maintainability benefits over writing assembly.
The alternative is a portable SIMD library, which does some instruction selection behind the scenes at the library level but tries to rely on the compiler for most of the heavy-duty work. For a long time I was skeptical that this approach would actually produce good, competitive code, which brings us to the actual point of this article: using Rust’s portable SIMD library to implement a somewhat fussy algorithm, and measuring performance.
Let’s design a SIMD implementation for a well-known algorithm. Although it doesn’t look like it at first, the power of shuffles makes it possible to parse text with SIMD. And this parsing can be very, very fast.
In this case, we’re going to implement base64 decoding. To review, base64 is an encoding scheme for arbitrary binary data into ASCII. We interpret a byte slice as a bit vector, and divide it into six-bit chunks called sextets. Then, each sextet from 0 to 63 is mapped to an ASCII character:
0 to 25 go to 'A' to 'Z'.
26 to 51 go to 'a' to 'z'.
52 to 61 go to '0' to '9'.
62 goes to +.
63 goes to /.
There are other variants of base64, but the bulk of the complexity is the same for each variant.
There are a few basic pitfalls to keep in mind.
Base64 is a “big endian” format: specifically, the bits in each byte are big endian. Because a sextet can span only parts of a byte, this distinction is important.
We need to beware of cases where the input length is not divisible by 4; ostensibly messages should be padded with = to a multiple of 4, but it’s easy to just handle messages that aren’t padded correctly.
The length of a decoded message is given by this function:
Given all this, the easiest way to implement base64 is something like this.
fndecode(data:&[u8],out:&mutVec<u8>)->Result<(),Error>{// Tear off at most two trailing =.letdata=matchdata{[p@..,b'=',b'=']|[p@..,b'=']|p=>p,};// Split the input into chunks of at most 4 bytes.forchunkindata.chunks(4){letmutbytes=0u32;for&byteinchunk{// Translate each ASCII character into its corresponding// sextet, or return an error.letsextet=matchbyte{b'A'..=b'Z'=>byte-b'A',b'a'..=b'z'=>byte-b'a'+26,b'0'..=b'9'=>byte-b'0'+52,b'+'=>62,b'/'=>63,_=>returnErr(Error(...)),};// Append the sextet to the temporary buffer.bytes<<=6;bytes|=sextetasu32;}// Shift things so the actual data winds up at the// top of `bytes`.bytes<<=32-6*chunk.len();// Append the decoded data to `out`, keeping in mind that// `bytes` is big-endian encoded.letdecoded=decoded_len(chunk.len());out.extend_from_slice(&bytes.to_be_bytes()[..decoded]);}Ok(())}
So, what’s the process of turning this into a SIMD version? We want to follow one directive with inexorable, robotic dedication.
Eliminate all branches.
This is not completely feasible, since the input is of variable length. But we can try. There are several branches in this code:
The for chunk in line. This one is is the length check: it checks if there is any data left to process.
The for &byte in line. This is the hottest loop: it branches once per input byte.
The match byte line is several branches, to determine which of the five “valid” match arms we land in.
The return Err line. Returning in a hot loop is extra control flow, which is not ideal.
The call to decoded_len contains a match, which generates branches.
The call to Vec::extend_from_slice. This contains not just branches, but potential calls into the allocator. Extremely slow.
(5) is the easiest to deal with. The match is mapping the values 0, 1, 2, 3 to 0, 1, 1, 2. Call this function f. Then, the sequence given by x - f(x) is 0, 0, 1, 1. This just happens to equal x / 2 (or x >> 1), so we can write a completely branchless version of decoded_len like so.
The superpower of SIMD is that because you operate on so much data at a time, you can unroll the loop so hard it becomes branchless.
The insight is this: we want to load at most four bytes, do something to them, and then spit out at most three decoded bytes. While doing this operation, we may encounter a syntax error so we need to report that somehow.
Here’s some facts we can take advantage of.
We don’t need to figure out how many bytes are in the “output” of the hot loop: our handy branchless decoded_len() does that for us.
Invalid base64 is extremely rare. We want that syntax error to cost as little as possible. If the user still cares about which byte was the problem, they can scan the input for it after the fact.
A is zero in base64. If we’re parsing a truncated chunk, padding it with A won’t change the value5.
This suggests an interface for the body of the “hottest loop”. We can factor it out as a separate function, and simplify since we can assume our input is always four bytes now.
fndecode_hot(ascii:[u8;4])->([u8;3],bool){letmutbytes=0u32;letmutok=true;forbyteinascii{letsextet=matchbyte{b'A'..=b'Z'=>byte-b'A',b'a'..=b'z'=>byte-b'a'+26,b'0'..=b'9'=>byte-b'0'+52,b'+'=>62,b'/'=>63,_=>!0,};bytes<<=6;bytes|=sextetasu32;ok&=byte==!0;}// This is the `to_be_bytes()` call.let[b1,b2,b3,_]=bytes.to_le_bytes();([b3,b2,b1],ok)}// In decode()...forchunkindata.chunks(4){letmutascii=[b'A';4];ascii[..chunk.len()].copy_from_slice(chunk);let(bytes,ok)=decode_hot(ascii);if!ok{returnErr(Error)}letlen=decoded_len(chunk.len());out.extend_from_slice(&bytes[..decoded]);}
You’re probably thinking: why not return Option<[u8; 3]>? Returning an enum will make it messier to eliminate the if !ok branch later on (which we will!). We want to write branchless code, so let’s focus on finding a way of producing that three-byte output without needing to do early returns.
Now’s when we want to start talking about vectors rather than arrays, so let’s try to rewrite our function as such.
Note that the output is now four bytes, not three. SIMD lane counts need to be powers of two, and that last element will never get looked at, so we don’t need to worry about what winds up there.
The callsite also needs to be tweaked, but only slightly, because Simd<u8, 4> is From<[u8; 4]>.
Let’s look at the first part of the for byte in ascii loop. We need to map each lane of the Simd<u8, 4> to the corresponding sextet, and somehow signal which ones are invalid. First, notice something special about the match: almost every arm can be written as byte - C for some constant C. The non-range case looks a little silly, but humor me:
So, it should be sufficient to build a vector offsets that contains the appropriate constant C for each lane, and then let sextets = ascii - offsets;
How can we build offsets? Using compare-and-select.
// A lane-wise version of `x >= start && x <= end`.fnin_range(bytes:Simd<u8,4>,start:u8,end:u8)->Mask<i8,4>{bytes.simd_ge(Simd::splat(start))&bytes.simd_le(Simd::splat(end))}// Create masks for each of the five ranges.// Note that these are disjoint: for any two masks, m1 & m2 == 0.letuppers=in_range(ascii,b'A',b'Z');letlowers=in_range(ascii,b'a',b'z');letdigits=in_range(ascii,b'0',b'9');letpluses=ascii.simd_eq([b'+';N].into());letsolidi=ascii.simd_eq([b'/';N].into());// If any byte was invalid, none of the masks will select for it,// so that lane will be 0 in the or of all the masks. This is our// validation check.letok=(uppers|lowers|digits|pluses|solidi).all();// Given a mask, create a new vector by splatting `value`// over the set lanes.fnmasked_splat(mask:Mask<i8,N>,value:i8)->Simd<i8,4>{mask.select(Simd::splat(val),Simd::splat(0))}// Fill the the lanes of the offset vector by filling the// set lanes with the corresponding offset. This is like// a "vectorized" version of the `match`.letoffsets=masked_splat(uppers,65)|masked_splat(lowers,71)|masked_splat(digits,-4)|masked_splat(pluses,-19)|masked_splat(solidi,-16);// Finally, Build the sextets vector.letsextets=ascii.cast::<i8>()-offsets;
This solution is quite elegant, and will produce very competitive code, but it’s not actually ideal. We need to do a lot of comparisons here: eight in total. We also keep lots of values alive at the same time, which might lead to unwanted register pressure.
Let’s look at the byte representations of the ranges. A-Z, a-z, and 0-9 are, as byte ranges, 0x41..0x5b, 0x61..0x7b, and 0x30..0x3a. Notice they all have different high nybbles! What’s more, + and / are 0x2b and 0x2f, so the function byte >> 4 is almost enough to distinguish all the ranges. If we subtract one if byte == b'/', we have a perfect hash for the ranges.
In other words, the value (byte >> 4) - (byte == '/') maps the ranges as follows:
A-Z goes to 4 or 5.
a-z goes to 6 or 7.
0-9 goes to 3.
+ goes to 2.
/ goes to 1.
This is small enough that we could cram a lookup table of values for building the offsets vector into another SIMD vector, and use a shuffle operation to do the lookup.
This is not my original idea; I came across a GitHub issue where an anonymous user points out this perfect hash.
Our new ascii-to-sextet code looks like this:
// Compute the perfect hash for each lane.lethashes=(ascii>>Simd::splat(4))+Simd::simd_eq(ascii,Simd::splat(b'/')).to_int()// to_int() is equivalent to masked_splat(-1, 0)..cast::<u8>();// Look up offsets based on each hash and subtract them from `ascii`.letsextets=ascii// This lookup table corresponds to the offsets we used to build the// `offsets` vector in the previous implementation, placed in the// indices that the perfect hash produces.-Simd::<i8,8>::from([0,16,19,4,-65,-65,-71,-71]).cast::<u8>().swizzle_dyn(hashes);
There is a small wrinkle here: Simd::swizzle_dyn() requires that the index array be the same length as the lookup table. This is annoying because right now ascii is a Simd<u8, 4>, but that will not be the case later on, so I will simply sweep this under the rug.
Note that we no longer get validation as a side-effect of computing the sextets vector. The same GitHub issue also provides an exact bloom-filter for checking that a particular byte is valid; you can see my implementation here. I’m not sure how the OP constructed the bloom filter, but the search space is small enough that you could have written a little script to brute force it.
Now comes a much tricker operation: we need to somehow pack all four sextets into three bytes. One way to try to wrap our head around what the packing code in decode_hot() is doing is to pass in the all-ones sextet in one of the four bytes, and see where those ones end up in the return value.
This is not unlike how they use radioactive dyes in biology to track the moment of molecules or cells through an organism.
Bingo. Playing around with the inputs lets us verify which pieces of the bytes wind up where. For example, by passing 0b110000 as input[1], we see that the two high bits of input[1] correspond to the low bits of output[0]. I’ve written the code so that the bits in each byte are printed in little-endian order, so bits on the left are the low bits.
Putting this all together, we can draw a schematic of what this operation does to a general Simd<u8, 4>.
Now, there’s no single instruction that will do this for us. Shuffles can be used to move bytes around, but we’re dealing with pieces of bytes here. We also can’t really do a shift, since we need bits that are overshifted to move into adjacent lanes.
The trick is to just make the lanes bigger.
Among the operations available for SIMD vectors are lane-wise casts, which allow us to zero-extend, sign-extend, or truncate each lane. So what we can do is cast sextets to a vector of u16, do the shift there and then… somehow put the parts back together?
Let’s see how far shifting gets us. How much do we need to shift things by? First, notice that the order of the bits within each chunk that doesn’t cross a byte boundary doesn’t change. For example, the four low bits of input[1] are in the same order when they become the high bits of output[1], and the two high bits of input[1] are also in the same order when they become the low bits of output[0].
This means we can determine how far to shift by comparing the bit position of the lowest bit of a byte of input with the bit position of the corresponding bit in output.
input[0]’s low bit is the third bit of output[0], so we need to shift input[0] by 2. input[1]’s lowest bit is the fifth bit of output[1], so we need to shift by 4. Analogously, the shifts for input[2] and input[3] turn out to be 6 and 0. In code:
So now we have a Simd<u16, 4> that contains the individual chunks that we need to move around, in the high and low bytes of each u16, which we can think of as being analogous to a [[u8; 2]; 4]. For example, shifted[0][0] contains sextet[0], but shifted. This corresponds to the red segment in the first schematic. The smaller blue segment is given by shifted[1][1], i.e., the high byte of the second u16. It’s already in the right place within that byte, so we want output[0] = shifted[0][0] | shifted[1][1].
This suggests a more general strategy: we want to take two vectors, the low bytes and the high bytes of each u16 in shifted, respectively, and somehow shuffle them so that when or’ed together, they give the desired output.
Look at the schematic again: if we had a vector consisting of [..aaaaaa, ....bbbb, ......cc], we could or it with a vector like [bb......, cccc...., dddddd..] to get the desired result.
One problem: dddddd.. is shifted[3][0], i.e., it’s a low byte. If we change the vector we shift by to [2, 4, 6, 8], though, it winds up in shifted[3][1], since it’s been shifted up by 8 bits: a full byte.
// Split shifted into low byte and high byte vectors.// Same way you'd split a single u16 into bytes, but lane-wise.letlo=shifted.cast::<u8>();lethi=(shifted>>Simd::from([8;4])).cast::<u8>();// Align the lanes: we want to get shifted[0][0] | shifted[1][1],// shifted[1][0] | shifted[2][1], etc.letoutput=lo|hi.rotate_lanes_left::<1>();
Et voila, here is our new, totally branchless implementation of decode_hot().
fndecode_hot(ascii:Simd<u8,4>)->(Simd<u8,4>,bool){lethashes=(ascii>>Simd::splat(4))+Simd::simd_eq(ascii,Simd::splat(b'/')).to_int().cast::<u8>();letsextets=ascii-Simd::<i8,8>::from([0,16,19,4,-65,-65,-71,-71]).cast::<u8>().swizzle_dyn(hashes);// Note quite right yet, see next section.letok=/* bloom filter shenanigans */;letshifted=sextets.cast::<u16>()<<Simd::from([2,4,6,8]);letlo=shifted.cast::<u8>();lethi=(shifted>>Simd::splat(8)).cast::<u8>();letoutput=lo|hi.rotate_lanes_left::<1>();(output,ok)}
The compactness of this solution should not be understated. The simplicity of this solution is a large part of what makes it so efficient, because it aggressively leverages the primitives the hardware offers us.
Ok, so now we have to contend with a new aspect of our implementation that’s crap: a Simd<u8, 4> is tiny. That’s not even 128 bits, which are the smallest vector registers on x86. What we need to do is make decode_hot() generic on the lane count. This will allow us to tune the number of lanes to batch together depending on benchmarks later on.
fndecode_hot<constN:usize>(ascii:Simd<u8,N>)->(Simd<u8,N>,bool)where// This makes sure N is a small power of 2.LaneCount<N>:SupportedLaneCount,{lethashes=(ascii>>Simd::splat(4))+Simd::simd_eq(ascii,Simd::splat(b'/')).to_int().cast::<u8>();letsextets=ascii-tiled(&[0,16,19,4,-65,-65,-71,-71]).cast::<u8>().swizzle_dyn(hashes);// Works fine now, as long as N >= 8.letok=/* bloom filter shenanigans */;letshifted=sextets.cast::<u16>()<<tiled(&[2,4,6,8]);letlo=shifted.cast::<u8>();lethi=(shifted>>Simd::splat(8)).cast::<u8>();letoutput=lo|hi.rotate_lanes_left::<1>();(output,ok)}/// Generates a new vector made up of repeated "tiles" of identical/// data.constfntiled<T,constN:usize>(tile:&[T])->Simd<T,N>whereT:SimdElement,LaneCount<N>:SupportedLaneCount,{letmutout=[tile[0];N];letmuti=0;whilei<N{out[i]=tile[i%tile.len()];i+=1;}Simd::from_array(out)}
We have to change virtually nothing, which is pretty awesome! But unfortunately, this code is subtly incorrect. Remember how in the N = 4 case, the result of output had a garbage value that we ignore in its highest lane? Well, now that garbage data is interleaved into output: every fourth lane contains garbage.
We can use a shuffle to delete these lanes, thankfully. Specifically, we want shuffled[i] = output[i + i / 3], which skips every forth index. So, shuffled[3] = output[4], skipping over the garbage value in output[3]. If i + i / 3 overflows N, that’s ok, because that’s the high quarter of the final output vector, which is ignored anyways. In code:
fndecode_hot<constN:usize>(ascii:Simd<u8,N>)->(Simd<u8,N>,bool)where// This makes sure N is a small power of 2.LaneCount<N>:SupportedLaneCount,{/* snip */letdecoded_chunks=lo|hi.rotate_lanes_left::<1>();letoutput=swizzle!(N;decoded_chunks,array!(N;|i|i+i/3));(output,ok)}
swizzle!() is a helper macro6 for generating generic implementations of std::simd::Swizzle, and array!() is something I wrote for generating generic-length array constants; the closure is called once for each i in 0..N.
So now we can decode 32 base64 bytes in parallel by calling decode_hot::<32>(). We’ll try to keep things generic from here, so we can tune the lane parameter based on benchmarks.
What branches are left? There’s still the branch from for chunks in .... It’s not ideal because it can’t do an exact pointer comparison, and needs to do a >= comparison on a length instead.
We call [T]::copy_from_slice, which is super slow because it needs to make a variable-length memcpy call, which can’t be inlined. Function calls are branches! The bounds checks are also a problem.
We branch on ok every loop iteration, still. Not returning early in decode_hot doesn’t win us anything (yet).
We potentially call the allocator in extend_from_slice, and perform another non-inline-able memcpy call.
The last of these is the easiest to address: we can reserve space in out, since we know exactly how much data we need to write thanks to decoded_len. Better yet, we can reserve some “slop”: i.e., scratch space past where the end of the message would be, so we can perform full SIMD stores, instead of the variable-length memcpy.
This way, in each iteration, we write the full SIMD vector, including any garbage bytes in the upper quarter. Then, the next write is offset 3/4 * N bytes over, so it overwrites the garbage bytes with decoded message bytes. The garbage bytes from the final right get “deleted” by not being included in the final Vec::set_len() that “commits” the memory we wrote to.
fndecode<constN:usize>(data:&[u8],out:&mutVec<u8>)->Result<(),Error>whereLaneCount<N>:SupportedLaneCount,{letdata=matchdata{[p@..,b'=',b'=']|[p@..,b'=']|p=>p,};letfinal_len=decoded_len(data);out.reserve(final_len+N/4);// Reserve with slop.// Get a raw pointer to where we should start writing.letmutptr=out.as_mut_ptr_range().end();letstart=ptr;forchunkindata.chunks(N){// N-sized chunks now./* snip */letdecoded=decoded_len(chunk.len());unsafe{// Do a raw write and advance the pointer.ptr.cast::<Simd<u8,N>>().write_unaligned(dec);ptr=ptr.add(decoded);}}unsafe{// Update the vector's final length.// This is the final "commit".letlen=ptr.offset_from(start);out.set_len(lenasusize);}Ok(())}
This is safe, because we’ve pre-allocated exactly the amount of memory we need, and where ptr lands is equal to the amount of memory actually decoded. We could also compute the final length of out ahead of time.
Note that if we early return due to if !ok, out remains unmodified, because even though we did write to its buffer, we never execute the “commit” part, so the code remains correct.
Next up, we can eliminate the if !ok branches by waiting to return an error until as late as possible: just before the set_len call.
Remember our observation from before: most base64 encoded blobs are valid, so this unhappy path should be very rare. Also, syntax errors cannot cause code that follows to misbehave arbitrarily, so letting it go wild doesn’t hurt anything.
The branch is still “there”, sure, but it’s out of the hot loop.
Because we never hit the set_len call and commit whatever garbage we wrote, said garbage essentially disappears when we return early, to be overwritten by future calls to Vec::push().
Ok, let’s look at the memcpy from copy_from_slice at the start of the hot loop. The loop has already been partly unrolled: it does N iterations with SIMD each step, doing something funny on the last step to make up for the missing data (padding with A).
We can take this a step further by doing an “unroll and jam” optimization. This type of unrolling splits the loop into two parts: a hot vectorized loop and a cold remainder part. The hot loop always handles length N input, and the remainder runs at most once and handles i < N input.
Rust provides an iterator adapter for hand-rolled (lol) unroll-and-jam: Iterator::chunks_exact().
fndecode<constN:usize>(data:&[u8],out:&mutVec<u8>)->Result<(),Error>whereLaneCount<N>:SupportedLaneCount,{/* snip */letmuterror=false;letmutchunks=data.chunks_exact(N);forchunkin&mutchunks{// Simd::from_slice() can do a load in one instruction.// The bounds check is easy for the compiler to elide.let(dec,ok)=decode_hot::<N>(Simd::from_slice(chunk));error|=!ok;/* snip */}letrest=chunks.remainder();if!rest.empty(){letmutascii=[b'A';N];ascii[..chunk.len()].copy_from_slice(chunk);let(dec,ok)=decode_hot::<N>(ascii.into());/* snip */}/* snip */}
At this point, it looks like we’ve addressed every branch that we can, so some benchmarks are in order. I wrote a benchmark that decodes messages of every length from 0 to something like 200 or 500 bytes, and compared it against the baseline base64 implementation on crates.io.
I compiled with -Zbuild-std and -Ctarget-cpu=native to try to get the best results. Based on some tuning, N = 32 was the best length, since it used one YMM register for each iteration of the hot loop.
So, we have the baseline beat. But what’s up with that crazy heartbeat waveform? You can tell it has something to do with the “remainder” part of the loop, since it correlates strongly with data.len() % 32.
I stared at the assembly for a while. I don’t remember what was there, but I think that copy_from_slice had been inlined and unrolled into a loop that loaded each byte at a time. The moral equivalent of this:
I decided to try Simd::gather_or(), which is kind of like a “vectorized load”. It wound up producing worse assembly, so I gave up on using a gather and instead wrote a carefully optimized loading function by hand.
The idea here is to perform the largest scalar loads Rust offers where possible. The strategy is again unroll and jam: perform u128 loads in a loop and deal with the remainder separately.
The hot part looks like this:
letmutbuf=[b'A';N];// Load a bunch of big 16-byte chunks. LLVM will lower these to XMM loads.letascii_ptr=buf.as_mut_ptr();letmutwrite_at=ascii_ptr;ifslice.len()>=16{foriin0..slice.len()/16{unsafe{write_at=write_at.add(i*16);letword=slice.as_ptr().cast::<u128>().add(i).read_unaligned();write_at.cast::<u128>().write_unaligned(word);}}}
The cold part seems hard to optimize at first. What’s the least number of unaligned loads you need to do to load 15 bytes from memory? It’s two! You can load a u64 from p, and then another one from p + 7; these loads (call them a and b) overlap by one byte, but we can or them together to merge that byte, so our loaded value is a as u128 | (b as u128 << 56).
A similar trick works if the data to load is between a u32 and a u64. Finally, to load 1, 2, or 3 bytes, we can load p, p + len/2 and p + len-1; depending on whether len is 1, 2, or 3, this will potentially load the same byte multiple times; however, this reduces the number of branches necessary, since we don’t need to distinguish the 1, 2, or 3 lines.
This is the kind of code that’s probably easier to read than to explain.
unsafe{letptr=slice.as_ptr().offset(write_at.offset_from(ascii_ptr));letlen=slice.len()%16;iflen>=8{// Load two overlapping u64s.letlo=ptr.cast::<u64>().read_unaligned()asu128;lethi=ptr.add(len-8).cast::<u64>().read_unaligned()asu128;letdata=lo|(hi<<((len-8)*8));letz=u128::from_ne_bytes([b'A';16])<<(len*8);write_at.cast::<u128>().write_unaligned(data|z);}elseiflen>=4{// Load two overlapping u32s.letlo=ptr.cast::<u32>().read_unaligned()asu64;lethi=ptr.add(len-4).cast::<u32>().read_unaligned()asu64;letdata=lo|(hi<<((len-4)*8));letz=u64::from_ne_bytes([b'A';8])<<(len*8);write_at.cast::<u64>().write_unaligned(data|z);}else{// Load 3 overlapping u8s.// For len 1 2 3 ...// ... this is ptr[0] ptr[0] ptr[0]letlo=ptr.read()asu32;// ... this is ptr[0] ptr[1] ptr[1]letmid=ptr.add(len/2).read()asu32;// ... this is ptr[0] ptr[1] ptr[2]lethi=ptr.add(len-1).read()asu32;letdata=lo|(mid<<((len/2)*8))|hi<<((len-1)*8);letz=u32::from_ne_bytes([b'A';4])<<(len*8);write_at.cast::<u32>().write_unaligned(data|z);}}
I learned this type of loading code while contributing to Abseil: it’s very useful for loading variable-length data for data-hungry algorithms, like a codec or a hash function.
Here’s the same benchmark again, but with our new loading code.
The results are really, really good. The variance is super tight, and our performance is 2x that of the baseline pretty much everywhere. Success.
Writing an encoding function is simple enough: first, implement an encode_hot() function that reverses the operations from decode_hot(). The perfect hash from before won’t work, so you’ll need to invent a new one.
Also, the loading/storing code around the encoder is slightly different, too. vb64 implements a very efficient encoding routine too, so I suggest taking a look at the source code if you’re interested.
There is a base64 variant called web-safe base64, that replaces the + and / characters with - and _. Building a perfect hash for these is trickier: you would probably have to do something like (byte >> 4) - (byte == '_' ? '_' : 0). I don’t support web-safe base64 yet, but only because I haven’t gotten around to it.
My library doesn’t really solve an important problem; base64 decoding isn’t a bottleneck… anywhere that I know of, really. But writing SIMD code is really fun! Writing branchless code is often overkill but can give you a good appreciation for what your compilers can and can’t do for you.
This project was also an excuse to try std::simd. I think it’s great overall, and generates excellent code. There’s some rough edges I’d like to see fixed to make SIMD code even simpler, but overall I’m very happy with the work that’s been done there.
This is probably one of the most complicated posts I’ve written in a long time. SIMD (and performance in general) is a complex topic that requires a breadth of knowledge of tricks and hardware, a lot of which isn’t written down. More of it is written down now, though.
Shifts are better understood as arithmetic. They have a lane width, and closely approximate multiplication and division. AVX2 doesn’t even have vector shift or vector division: you emulate it with multiplication. ↩
The two common representations of true and false, i.e. 1 and 0 or 0xff... and 0, are related by the two’s complement operation.
For example, if I write uint32_t m = -(a == b);, m will be zero if a == b is false, and all-ones otherwise. This because applying any arithmetic operation to a bool promotes it to int, so false maps to 0 and true maps to 1. Applying the - sends 0 to 0 and 1 to -1, and it’s useful to know that in two’s complement, -1 is represented as all-ones.
The all-ones representation for true is useful, because it can be used to implement branchless select very easily. For example,
This function returns x if a == b, and y otherwise. Can you tell why? ↩
Target features also affect ABI in subtle ways that I could write many, many more words on. Compiling libraries you plan to distribute with weird target feature flags is a recipe for disaster. ↩
Why can’t we leave this kind of thing to LLVM? Finding this particular branchless implementation is tricky. LLVM is smart enough to fold the match into a switch table, but that’s unnecessary memory traffic to look at the table. (In this domain, unnecessary memory traffic makes our code slower.)
Incidentally, with the code I wrote for the original decoded_len(), LLVM produces a jump and a lookup table, which is definitely an odd choice? I went down something of a rabbit-hole. https://github.com/rust-lang/rust/issues/118306
As for getting LLVM to find the “branchless” version of the lookup table? The search space is quite large, and this kind of “general strength reduction” problem is fairly open (keywords: “superoptimizers”). ↩
To be clear on why this works: suppose that in our reference implementation, we only handle inputs that are a multiple-of-4 length, and are padded with = as necessary, and we treat = as zero in the match. Then, for the purposes of computing the bytes value (before appending it to out), we can assume the chunk length is always 4. ↩
Linear algebra is undoubtedly the most useful field in all of algebra. It finds applications in all kinds of science and engineering, like quantum mechanics, graphics programming, and machine learning. It is the “most well-behaved” algebraic theory, in that other abstract algebra topics often try to approximate linear algebra, when possible.
For many students, linear algebra means vectors and matrices and determinants, and complex formulas for computing them. Matrices, in particular, come equipped with a fairly complicated, and a fortiori convoluted, multiplication operation.
This is not the only way to teach linear algebra, of course. Matrices and their multiplication appear complicated, but actually are a natural and compact way to represent a particular type of function, i.e., a linear map (or linear transformation).
This article is a short introduction to viewing linear algebra from the perspective of abstract algebra, from which matrices arise as a computational tool, rather than an object of study in and of themselves. I do assume some degree of familiarity with the idea of a matrix.
Most linear algebra courses open with a description of vectors in Euclidean space: Rn. Vectors there are defined as tuples of real numbers that can be added, multiplied, and scaled. Two vectors can be combined into a number through the dot product. Vectors come equipped with a notion of magnitude and direction.
However, this highly geometric picture can be counterproductive, since it is hard to apply geometric intuition directly to higher dimensions. It also obscures how this connects to working over a different number system, like the complex numbers.
Instead, I’d like to open with the concept of a linear space, which is somewhat more abstract than a vector space1.
First, we will need a notion of a “coefficient”, which is essentially something that you can do arithmetic with. We will draw coefficients from a designated ground fieldK. A field is a setting for doing arithmetic: a set of objects that can be added, subtracted, and multiplied, and divided in the “usual fashion” along with special 0 and 1 values. E.g. a+0=a, 1a=a, a(b+c)=ab+ac, and so on.
Not only are the real numbers R a field, but so are the complex numbers C, and the rational numbers Q. If we drop the “division” requirement, we can also include the integers Z, or polynomials with rational coefficients Q[x], for example.
Having chosen our coefficients K, a linear space VoverK is another set of objects that can be added and subtracted (and including a special value 0)2, along with a scaling operation, which takes a coefficient c∈K and one of our objects v∈V and produces a new cv∈V.
The important part of the scaling operation is that it’s compatible with addition: if we have a,b∈K and v,w∈V, we require that
This is what makes a linear space “linear”: you can write equations that look like first-degree polynomials (e.g. ax+b), and which can be manipulated like first-degree polynomials.
These polynomials are called linear because their graph looks like a line. There’s no multiplication, so we can’t have x2, but we do have multiplication by a coefficient. This is what makes linear algebra is “linear”.
Some examples: n-tuples of elements drawn from any field are a linear space over that field, by componentwise addition and scalar multiplication; e.g., R3. Setting n=1 shows that every field is a linear space over itself.
Polynomials in one variable over some field, K[x], are also a linear space, since polynomials can be added together and scaled by a any value in K (since lone coefficients are degree zero polynomials). Real-valued functions also form a linear space over R in a similar way.
A linear map is a function f:V→W between two linear spaces V and W over K which “respects” the linear structure in a particular way. That is, for any c∈K and v,w∈V,
We call this type of relationship (respecting addition and scaling) “linearity”. One way to think of this relationship is that f is kind of like a different kind of coefficient, in that it distributes over addition, which commutes with the “ordinary” coefficients from K. However, applying f produces a value from W rather than V.
Another way to think of it is that if we have a linear polynomial like p(x)=ax+b in x, then f(p(x))=p(f(x)). We say that fcommutes with all linear polynomials.
The most obvious sort of linear map is scaling. Given any coefficient c∈K, it defines a “scaling map”:
It’s trivial to check this is a linear map, by plugging it into the above equations: it’s linear because scaling is distributive and commutative.
Linear maps are the essential thing we study in linear algebra, since they describe all the different kinds of relationships between linear spaces.
Some linear maps are complicated. For example, a function from R2→R2 that rotates the plane by some angle θ is linear, as are operations that stretch or shear the plane. However, they can’t “bend” or “fold” the plane: they are all fairly rigid motions. In the linear space Q[x] of rational polynomials, multiplication by any polynomial, such as x or x2−1, is a linear map. The notion of “linear map” depends heavily on the space we’re in.
Unfortunately, linear maps as they are quite opaque, and do not lend themselves well to calculation. However, we can build an explicit representation using a linear basis.
For any linear space, we can construct a relatively small of elements such that any element of the space can be expressed as some linear function of these elements.
Explicitly, for any V, we can construct a sequence3ei such that for any v∈V, we can find ci∈K such that
Such a set ei is called a basis if it is linearly independent: no one ei can be expressed as a linear function of the rest. The dimension of V, denoted dimV, is the number of elements in any choice of basis. This value does not depend on the choice of basis4.
Constructing a basis for any V is easy: we can do this recursively. First, pick a random element e1 of V, and define a new linear space V/e1 where we have identified all elements that differ by a factor of e1 as equal (i.e., if v−w=ce1, we treat v and w as equal in V/e1).
Then, a basis for V is a basis of V/e1 with e1 added. The construction of V/e1 is essentially “collapsing” the dimension e1 “points” in, giving us a new space where we’ve “deleted” all of the elements that have a nonzero e1 component.
However, this only works when the dimension is finite; more complex methods must be used for infinite-dimensional spaces. For example, the polynomials Q[x] are an infinite-dimensional space, with basis elements 1,x,x2,x3,…. In general, for any linear space V, it is always possible to arbitrarily choose a basis, although it may be infinite5.
Bases are useful because they give us a concrete representation of any element of V. Given a fixed basis ei, we can represent any w=∑iciei by the coefficients ci themselves. For a finite-dimensional V, this brings us back column vectors: (dimV)-tuples of coefficients from K that are added and scaled componentwise.
It is important to recall that the choice of basis is arbitrary. From the mathematical perspective, any basis is just as good as any other, although some may be more computationally convenient.
Over R2, (1,0) and (0,1) are sometimes called the “standard basis”, but (1,2) and (3,−4) are also a basis for this space. One easy mistake to make, particularly when working over the tuple space Kn, is to confuse the actual elements of the linear space with the coefficient vectors that represent them. Working with abstract linear spaces eliminates this source of confusion.
Working with finite-dimensional linear spaces V and W, let’s choose bases ei and dj for them, and let’s consider a linear map f:V→W.
The powerful thing about bases is that we can more compactly express the information content of f. Given any v∈V, we can decompose it into a linear function of the basis (for some coefficients), so we can write
In other words, to specify f, we only need to specify what it does to each of the dimV basis elements. But what’s more, because W also has a basis, we can write
Alternatively, we can express v and f(v) as column vectors, and f as the A matrix with entires Aij. The entries of the resulting column vector are given by the above explicit formula for f(v), fixing the value of j in each entry.
(Remember, this is all dependent on the choices of bases ei and dj!)
Behold, we have derived the matrix-vector multiplication formula: the jth entry of the result is the dot product of the vector and the jth row of the matrix.
But it is crucial to keep in mind that we had to choose bases ei and dj to be entitled to write down a matrix for f. The values of the coefficients depend on the choice of basis.
If your linear space happens to be Rn, there is an “obvious” choice of basis, but not every linear space over R is Rn! Importantly, the actual linear algebra does not change depending on the basis6.
So, where does matrix multiplication come from? An n×m7 matrix Arepresents some linear map f:V→W, where dimV=n, dimW=m, and appropriate choices of basis (ei, dj) have been made.
Keeping in mind that linear maps are supreme over matrices, suppose we have a third linear space U, and a map g:U→V, and let ℓ=dimU. Choosing a basis hk for U, we can represent g as a matrix B of dimension ℓ×n.
Then, we’d like for the matrix product AB to be the same matrix we’d get from representing the composite map fg:U→W as a matrix, using the aforementioned choices of bases for U and W (the basis choice for V should “cancel out”).
Recall our formula for f(v) in terms of its matrix coefficients Aij and the coefficients of the input v, which we call ci. We can produce a similar formula for g(u), giving it matrix coefficients Bki, and coefficients bk for u. (I appologize for the number of indices and coefficients here.)
In (⋆), we’ve rearranged things so that the sum in parenthesis is the (k,j)th matrix coefficient of the composite fg. Because we wanted AB to represent fg, it must be an ℓ×m matrix whose entries are
This is matrix multiplication. It arises naturally out of composition of linear maps. In this way, the matrix multiplication formula is not a definition, but a theorem of linear algebra!
If the matrix dimension is read as n→m instead of n×m, the shape requirements are more obvious: two matrices A and B can be multiplied together only when they represent a pair of maps V→W and U→V.
We want it to be such that for any appropriately-sized matrices A and B, it has AIn=A and InB=B. Lifted up to linear maps, this means that In should represent the identity map V→V, when dimV=n. This map sends each basis element ei to itself, so the columns of In should be the basis vectors, in order:
This is similar to the identity, but we’ve swapped the first two columns. Thus, it will swap the first two coefficients of any column vector.
Matrices may seem unintuitive when they’re introduced as a subject of study. Every student encountering matrices for the same time may ask “If they add componentwise, why don’t they multiply componentwise too?”
However, approaching matrices as a computational and representational tool shows that the convoluted-looking matrix multiplication formula is a direct consequence of linearity.
In actual modern mathematics, the objects I describe are still called vector spaces, which I think generates unnecessary confusion in this case. “Linear space” is a bit more on the nose for what I’m going for. ↩
This type of structure (just the addition part) is also called an “abelian group”. ↩
Throughout i, j, and k are indices in some unspecified but ordered indexing set, usually {1,2,…,n}. I will not bother giving this index set a name. ↩
This is sometimes called the dimension theorem, which is somewhat tedious to prove. ↩
An example of a messy infinite-dimensional basis is R considered as linear space over Q (in general, every field is a linear space over its subfields). The basis for this space essentially has to be “1, and all irrational numbers” except if we include e.g. e and π we can’t include e+21π, which is a Q-linear combination of e and π.
On the other hand, C is two-dimensional over R, with basis 1,i.
Incidentally, this idea of “view a field K as a linear space over its subfield F” is such a useful concept that it is called the “degree of the field extension K/F”, and given the symbol [K:F].
You may recall from linear algebra class that two matrices A and B of the same shape are similar if there are two appropriately-sized square matrices S and R such that SAR=B. These matrices S and R represent a change of basis, and indicate that the linear maps A,B:V→W these matrices come from do “the same thing” to elements of V.
Over an algebraically closed field like C (i.e. all polynomials have solutions), there is an even stronger way to capture the information content of a linear map via Jordan canonicalization, which takes any square matrix A and produces an almost-diagonal square matrix that only depends on the eigenvalues of A, which is the same for similar matrices, and thus basis-independent. ↩
Here, as always, matrix dimensions are given in RC (row-column) order. You can think of this as being “input dimension” to “output dimension”. ↩
I write compilers for fun. I can’t help it. Consequently, I also write a lot of parsers. In systems programming, it’s usually a good idea to try to share memory rather than reuse it, so as such my AST types tend to look like this.
Whenever we parse an identifier, rather than copy its name into a fresh String, we borrow from the input source string. This avoids an extra allocation, an extra copy, and saves a word in the representation. Compilers can be memory-hungry, so it helps to pick a lean representation.
Unfortunately, it’s not so easy for quoted strings. Most strings, like "all my jelly babies", are “literally” in the original source, like an identifier. But strings with escapes aren’t: \n is encoded in the source code with the bytes [0x5c, 0x6e], but the actual “decoded” value of a string literal replaces each escape with a single 0x0a.
The usual solution is a Cow<str>. In the more common, escape-less verison, we can use Cow::Borrowed, which avoids the extra allocation and copy, and in the escaped version, we decode the escapes into a String and wrap it in a Cow::Owned.
For example, suppose that we’re writing a parser for a language that has quoted strings with escapes. The string "all my jelly babies" can be represented as a byte string that borrows the input source code, so we’d use the Cow::Borrowed variant. This is most strings in any language: escapes tend to be rare.
For example, if we have the string "not UTF-8 \xff", the actual byte string value is different from that in the source code.
// Bytes in the source.
hex: 6e 6f 74 20 55 54 46 2d 38 20 5c 78 66 66
ascii: n o t U T F - 8 \ x f f
// Bytes represented by the string.
hex: 6e 6f 74 20 55 54 46 2d 38 20 ff
ascii: n o t U T F - 8
Escapes are relatively rare, so most strings processed by the parser do not need to pay for an allocation.
However, we still pay for that extra word, since Cow<str> is 24 bytes (unless otherwise specified, all byte counts assume a 64-bit system), which is eight more than our &str. Even worse, this is bigger than the string data itself, which is 11 bytes.
If most of your strings are small (which is not uncommon in an AST parser), you will wind up paying for significant overhead.
Over the years I’ve implemented various optimized string types to deal with this use-case, in various contexts. I finally got around to putting all of the tricks I know into a library, which I call byteyarn. It advertises the following nice properties.
String is modeled after C++’s std::string, which is a growable buffer that implements amortized linear-time append. This means that if we are appending n bytes to the buffer, we only pay for n bytes of memcpy.
This is a useful but often unnecessary property. For example, Go strings are immutable, and when building up a large string, you are expected to use strings.Builder, which is implemented as essentially a Rust String. Java also as a similar story for strings, which allows for highly compact representations of java.lang.Strings.
In Rust, this kind of immutable string is represented by a Box<str>, which is eight bytes smaller than String. Converting from String to Box<str> is just a call to realloc() to resize the underlying allocation (which is often cheap1) from being capacity bytes long to len bytes long.
Thus, this assumption means we only need to store a pointer and a length, which puts our memory footprint floor at 16 bytes.
Suppose again that we’re parsing some textual format. Many structural elements will be verbatim references into the textual input. Not only string literals without escapes, but also identifiers.
Box<str> cannot hold borrowed data, because it will always instruct the allocator to free its pointer when it goes out of scope. Cow<str>, as we saw above, allows us to handle maybe-owned data uniformly, but has a minimum 24 byte overhead. This can’t be made any smaller, because a Cow<str> can contain a 24-byte String value.
But, we don’t want to store a capacity. Can we avoid the extra word of overhead in Cow<str>?
Consider a string that is not a substring but which is small. For example, when parsing a string literal like "Hello, world!\n", the trailing \n (bytes 0x5c 0x6e) must be replaced with a newline byte (0x0a). This means we must handle a tiny heap allocation, 14 bytes long, that is smaller than a &str referring to it.
This is worse for single character2 strings. The overhead for a Box<str> is large.
The Box<str> struct itself has a pointer field (eight bytes), and a length field (also eight bytes). Spelled out to show all the stored bits, the length is 0x0000_0000_0000_0001. That’s a lot of zeroes!
The pointer itself points to a heap allocation, which will not be a single byte! Allocators are not in the business of handing out such small pieces of memory. Instead, the allocation is likely costing us another eight bytes!
So, the string "a", whose data is just a single byte, instead takes up 24 bytes of memory.
It turns out that for really small strings we can avoid the allocation altogether, and make effective use of all those zeroes in the len field.
Let’s say we want to stick to a budget of 16 bytes for our Yarn type. Is there any extra space left for data in a (*mut u8, usize) pair?
*cracks Fermi estimation knuckles*
A usize is 64 bits, which means that the length of an &str can be anywhere from zero to 18446744073709551615, or around 18 exabytes. For reference, “hundreds of exabytes” is a reasonable ballpark guess for how much RAM exists in 2023 (consider: 4 billion smartphones with 4GB each). More practically, the largest quantity of RAM you can fit in a server blade is measured in terabytes (much more than your measly eight DIMs on your gaming rig).
If we instead use one less bit, 63 bits, this halves the maximum representable memory to nine exabytes. If we take another, it’s now four exabytes. Much more memory than you will ever ever want to stick in a string. Wikpedia asserts that Wikimedia Commons contains around 428 terabytes of media (the articles’ text with history is a measly 10 TB).
Ah, but you say you’re programming for a 32-bit machine (today, this likely means either a low-end mobile phone, an embedded micro controller, or WASM).
On a 32-bit machine it’s a little bit harrier: Now usize is 32 bits, for a maximum string size of 4 gigabytes (if you remember the 32-bit era, this limit may sound familiar). “Gigabytes” is an amount of memory that you can actually imagine having in a string.
Even then, 1 GB of memory (if we steal two bits) on a 32-bit machine is a lot of data. You can only have four strings that big in a single address space, and every 32-bit allocator in the universe will refuse to serve an allocation of that size. If your strings are comparable in size to the whole address space, you should build your own string type.
The upshot is that every &str contains two bits we can reasonably assume are not used. Free real-estate.3
Rust has the concept of niches, or invalid bit-patterns of a particular type, which it uses for automatic layout optimization of enums. For example, references cannot be null, so the pointer bit-pattern of 0x0000_0000_0000_0000 is never used; this bit-pattern is called a “niche”. Consider:
An enum of this form will not need any “extra” space to store the value that discriminates between the two variants: if a Foo’s bits are all zero, it’s Foo::Second; otherwise it’s a Foo::First and the payload is formed from Foo’s bit-pattern. This, incidentally, is what makes Option<&T> a valid representation for a “nullable pinter”.
There are more general forms of this: bool is represented as a single byte, of which two bit are valid; the other 254 potential bit-patterns are niches. In Recent versions of Rust, RawFd has a niche for the all-ones bit-pattern, since POSIX file descriptors are always non-negative ints.
By stealing two bits off of the length, we have given ourselves four niches, which essentially means we’ll have a hand-written version of something like this enum.
For reasons that will become clear later, we will specifically steal the high bits of the length, so that to recover the length, we do two shifts4 to shift in two high zero bits. Here’s some code that actually implements this for the low level type our string type will be built on.
#[repr(C)]#[derive(Copy,Clone)]structRawYarn{ptr:*mutu8,len:usize,}implRawYarn{/// Constructs a new RawYarn from raw components: a 2-bit kind,/// a length, and a pointer.fnfrom_raw_parts(kind:u8,len:usize,ptr:*mutu8)->Self{assert!(len<=usize::MAX/4,"no way you have a string that big");RawYarn{ptr,len:(kindasusize&0b11)<<(usize::BITS-2)|len,}}/// Extracts the kind back out.fnkind(self)->u8{(self.len>>(usize::BITS-2))asu8}/// Extracts the slice out (regardless of kind).unsafefnas_slice(&self)->&[u8]{slice::from_raw_parts(self.ptr,(self.len<<2)>>2)}}
Note that I’ve made this type Copy, and some functions take it by value. This is for two reasons.
There is a type of Yarn that is itself Copy, although I’m not covering it in this article.
It is a two-word struct, which means that on most architectures it is eligible to be passed in a pair of registers. Passing it by value in the low-level code helps promote keeping it in registers. This isn’t always possible, as we will see when we discuss “SSO”.
Let’s chose kind 0 to mean “this is borrowed data”, and kind 1 to be “this is heap-allocated data”. We can use this to remember whether we need to call a destructor.
pubstructYarn<'a>{raw:RawYarn,_ph:PhantomData<&'astr>,}constBORROWED:u8=0;constHEAP:u8=1;impl<'a>Yarn<'a>{/// Create a new yarn from borrowed data.pubfnborrowed(data:&'astr)->Self{letlen=data.len();letptr=data.as_ptr().cast_mut();Self{raw:RawYarn::from_raw_parts(BORROWED,len,ptr),_ph:PhantomData,}}/// Create a new yarn from owned data.pubfnowned(data:Box<str>)->Self{letlen=data.len();letptr=data.as_ptr().cast_mut();mem::forget(data);Self{raw:RawYarn::from_raw_parts(HEAP,len,ptr),_ph:PhantomData,}}/// Extracts the data.pubfnas_slice(&self)->&str{unsafe{// SAFETY: initialized either from uniquely-owned data,// or borrowed data of lifetime 'a that outlives self.str::from_utf8_unchecked(self.raw.as_slice())}}}implDropforYarn<'_>{fndrop(&mutself){ifself.raw.kind()==HEAP{letdropped=unsafe{// SAFETY: This is just reconstituting the box we dismantled// in Yarn::owned().Box::from_raw(self.raw.as_mut_slice())};}}}implRawYarn{unsafefnas_slice_mut(&mutself)->&mut[u8]{// Same thing as as_slice, basically. This is just to make// Box::from_raw() above typecheck.}}
This gives us a type that strongly resembles Cow<str> with only half of the bytes. We can even write code to extend the lifetime of a Yarn:
implYarn<'_>{/// Removes the bound lifetime from the yarn, allocating if/// necessary.pubfnimmortalize(mutself)->Yarn<'static>{ifself.raw.kind()==BORROWED{letcopy:Box<str>=self.as_slice().into();self=Yarn::owned(copy);}// We need to be careful that we discard the old yarn, since its// destructor may run and delete the heap allocation we created// above.letraw=self.raw;mem::forget(self);Yarn::<'static>{raw,_ph:PhantomData,}}}
C++’s std::string also makes the “most strings are small” assumption. In the libc++ implementation of the standard library, std::strings of up to 23 bytes never hit the heap!
C++ implementations do this by using most of the pointer, length, and capacity fields as a storage buffer for small strings, the so-called “small string optimization” (SSO). In libc++, in SSO mode, a std::string’s length fits in one byte, so the other 23 bytes can be used as storage. The capacity isn’t stored at all: an SSO string always has a capacity of 23.
RawYarn still has another two niches, so let’s dedicate one to a “small” representation. In small mode, the kind will be 2, and only the 16th byte will be the length.
This is why we used the two high bits of len for our scratch space: no matter what mode it’s in, we can easily extract these bits5. Some of the existing RawYarn methods need to be updated, though.
#[repr(C)]#[derive(Copy,Clone)]structRawYarn{ptr:MaybeUninit<*mutu8>,len:usize,}constSMALL:u8=2;implRawYarn{/// Constructs a new RawYarn from raw components: a 2-bit kind,/// a length, and a pointer.fnfrom_raw_parts(kind:u8,len:usize,ptr:*mutu8){debug_assert!(kind!=SMALL);assert!(len<=usize::MAX/4,"no way you have a string that big");RawYarn{ptr:MaybeUninit::new(ptr),len:(kindasusize&0b11)<<(usize::BITS-2)|len,}}/// Extracts the slice out (regardless of kind).unsafefnas_slice(&self)->&[u8]{let(ptr,adjust)=matchself.kind(){SMALL=>(selfas*constSelfas*constu8,usize::BITS-8),_=>(self.ptr.assume_init(),0),};slice::from_raw_parts(ptr,(self.len<<2)>>(2+adjust))}}
In the non-SMALL case, we shift twice as before, but in the SMALL case, we need to get the high byte of the len field, so we need to shift down by an additional usize::BITS - 8. No matter what we’ve scribbled on the low bytes of len, we will always get just the length this way.
We also need to use a different pointer value depending on whether we’re in SMALL mode. This is why as_slice needs to take a reference argument, since the slice data may be directly in self!
Also, ptr is a MaybeUninit now, which will become clear in the next code listing.
We should also provide a way to construct small strings.
constSSO_LEN:usize=size_of::<usize>()*2-1;implRawYarn{/// Create a new small yarn. `data` must be valid for `len` bytes/// and `len` must be smaller than `SSO_LEN`.unsafefnfrom_small(data:*constu8,len:usize)->RawYarn{debug_assert!(len<=SSO_LEN);// Create a yarn with an uninitialized pointer value (!!)// and a length whose high byte is packed with `small` and// `len`.letmutyarn=RawYarn{ptr:MaybeUninit::uninit(),len:(SMALLasusize<<6|len)<<(usize::BITS-8),};// Memcpy the data to the new yarn.// We write directly onto the `yarn` variable. We won't// overwrite the high-byte length because `len` will// never be >= 16.ptr::copy_nonoverlapping(data,&mutyarnas*mutRawYarnas*mutu8,data,);yarn}}
The precise maximum size of an SSO string is a bit more subtle than what’s given above, but it captures the spirit. The RawYarn::from_small illustrates why the pointer value is hidden in a MaybeUninit: we’re above to overwrite it with garbage, and in that case it won’t be a pointer at all.
We can update our public Yarn type to use the new small representation whenever possible.
impl<'a>Yarn<'a>{/// Create a new yarn from borrowed data.pubfnborrowed(data:&'astr)->Self{letlen=data.len();letptr=data.as_ptr().cast_mut();iflen<=SSO_LEN{returnSelf{raw:unsafe{RawYarn::from_small(len,ptr)},_ph:PhantomData,}}Self{raw:RawYarn::from_raw_parts(BORROWED,len,ptr),_ph:PhantomData,}}/// Create a new yarn from owned data.pubfnowned(data:Box<str>)->Self{ifdata.len()<=SSO_LEN{returnSelf{raw:unsafe{RawYarn::from_small(data.len(),data.as_ptr())},_ph:PhantomData,}}letlen=data.len();letptr=data.as_ptr().cast_mut();mem::forget(data);Self{raw:RawYarn::from_raw_parts(HEAP,len,ptr),_ph:PhantomData,}}}
It’s also possible to construct a Yarn directly from a character now, too!
impl<'a>Yarn<'a>{/// Create a new yarn from borrowed data.pubfnfrom_char(data:char)->Self{letmutbuf=[0u8;4];letdata=data.encode_utf8(&mutbuf);Self{raw:unsafe{RawYarn::from_small(len,ptr)},_ph:PhantomData,}}}
String constants in Rust are interesting, because we can actually detect them at compile-time6.
We can use the last remaining niche, 3, to represent data that came from a string constant, which means that it does not need to be boxed to be immortalized.
constSTATIC:u8=3;impl<'a>Yarn<'a>{/// Create a new yarn from borrowed data.pubfnfrom_static(data:&'staticstr)->Self{letlen=data.len();letptr=data.as_ptr().cast_mut();iflen<=SSO_LEN{returnSelf{raw:unsafe{RawYarn::from_small(len,ptr)},_ph:PhantomData,}}Self{raw:RawYarn::from_raw_parts(STATIC,len,ptr),_ph:PhantomData,}}}
This function is identical to Yarn::borrowed, except that data most now have a static lifetime, and we pass STATIC to RawYarn::from_raw_parts().
Because of how we’ve written all of the prior code, this does not require any special support in Yarn::immortalize() or in the low-level RawYarn code.
The actual byteyarn library provides a yarn!() macro that has the same syntax as format!(). This is the primary way in which yarns are created. It is has been carefully written so that yarn!("this is a literal") always produces a STATIC string, rather than a heap-allocated string.
Unfortunately, because of how we’ve written it, Option<Yarn> is 24 bytes, a whole word larger than a Yarn. However, there’s still a little gap where we can fit the None variant. It turns out that because of how we’ve chosen the discriminants, len is zero if and only if it is an empty BORROWED string. But this is not the only zero: if the high byte is 0x80, this is an empty SMALL string. If we simply require that no other empty string is ever constructed (by marking RawYarn::from_raw_parts() as unsafe and specifying it should not be passed a length of zero), we can guarantee that len is never zero.
Thus, we can update len to be a NonZeroUsize.
#[repr(C)]#[derive(Copy,Clone)]structRawYarn{ptr:MaybeUninit<*mutu8>,len:NonZeroUsize,// (!!)}implRawYarn{/// Constructs a new RawYarn from raw components: a 2-bit kind,/// a *nonzero* length, and a pointer.unsafefnfrom_raw_parts(kind:u8,len:usize,ptr:*mutu8){debug_assert!(kind!=SMALL);debug_assert!(len!=0);assert!(len<=usize::MAX/4,"no way you have a string that big");RawYarn{ptr:MaybeUninit::new(ptr),len:NonZeroUsize::new_unchecked((kindasusize&0b11)<<(usize::BITS-2)|len),}}}
This is a type especially known to the Rust compiler to have a niche bit-pattern of all zeros, which allows Option<Yarn> to be 16 bytes too. This also has the convenient property that the all zeros bit-pattern for Option<Yarn> is None.
A Yarn is a highly optimized string type that provides a number of useful properties over String:
Always two pointers wide, so it is always passed into and out of functions in registers.
Small string optimization (SSO) up to 15 bytes on 64-bit architectures.
Can be either an owned buffer or a borrowed buffer (like Cow<str>).
Can be upcast to 'static lifetime if it was constructed from a known-static string.
There are, of course, some trade-offs. Not only do we need the assumptions we made originally to hold, but we also need to relatively care more about memory than cycle-count performance, since basic operations like reading the length of the string require more math (but no extra branching).
The actual implementation of Yarn is a bit more complicated, partly to keep all of the low-level book-keeping in one place, and partly to offer an ergonomic API that makes Yarn into a mostly-drop-in replacement for Box<str>.
I hope this peek under the hood has given you a new appreciation for what can be achieved by clever layout-hacking.
Allocators rarely serve you memory with precisely the size you asked for. Instead, they will have some notion of a “size class” that allows them to use more efficient allocation techniques, which I have written about.
As a result, if the size change in a realloc() would not change the size class, it becomes a no-op, especially if the allocator can take advantage of the current-size information Rust provides it. ↩
Here and henceforth “character” means “32-bit Unicode scalar”. ↩
Now, you might also point out that Rust and C do not allow an allocation whose size is larger than the pointer offset type (isize and ptrdiff_t, respectively). In practice this means that the high bit is always zero according to the language’s own rules.
This is true, but we need to steal two bits, and I wanted to demonstrate that this is an extremely reasonable desire. 64-bit integers are so comically large. ↩
If we want to play the byte-for-byte game, this costs 14 bytes when encoded in the Intel variable-length encoding. You would think that two shifts would result in marginally smaller code, but no, since the input comes in in rdi and needs to wind up in rax.
On RISC-V, though, it seems to decide that two shifts is in fact cheaper, and will even optimize x & 0x3fff_ffff_ffff_ffff back into two shifts. ↩
This only works on little endian. Thankfully all computers are little endian. ↩
Technically, a &'static str may also point to leaked memory. For our purposes, there is no essential difference. ↩
The other day, I saw this tweet. In it, Andrew Gallant argues that reaching for LLVM IR, instead of assembly, is a useful tool for someone working on performance. Unfortunately, learning material on LLVM is usually aimed at compiler engineers, not generalist working programmers.
Now, I’m a compiler engineer, so my answer is of course you should know your optimizer’s IR. But I do think there’s a legitimate reason to be able to read it, in the same way that being able to read assembly to understand what your processor is doing is a powerful tool. I wrote an introduction to assembly over a year ago (still have to finish the followups… 💀), which I recommend reading first.
Learning LLVM IR is similar, but it helps you understand what your compiler is doing to create highly optimized code. LLVM IR is very popular, and as such well-documented and reasonably well-specified, to the point that we can just treat it as a slightly weird programming language.
In this article, I want to dig into what LLVM IR is and how to read it.
“LLVM” is an umbrella name for a number of software components that can be used to build compilers. If you write performance-critical code, you’ve probably heard of it.
Its flagship product is Clang, a high-end C/C++/Objective-C compiler. Clang follows the orthodox compiler architecture: a frontend that parses source code into an AST and lowers it into an intermediate representation, an “IR”; an optimizer (or “middle-end”) that transforms IR into better IR, and a backend that converts IR into machine code for a particular platform.
LLVM often also refers to just the optimizer and backend parts of Clang; this is can be thought of as a compiler for the “LLVM language” or “LLVM assembly”. Clang, and other language frontends like Rust, essentially compile to LLVM IR, which LLVM then compiles to machine code.
LLVM IR is well documented and… somewhat stable, which makes it a very good compilation target, since language implementers can re-use the thousands of engineer hours poured into LLVM already. The source of truth for “what is LLVM IR?” is the LangRef.
LLVM IR is also binary format (sometimes called “bitcode”), although we will be working exclusively with its text format (which uses the .ll extension).
LLVM-targeting compilers will have debugging flags to make them emit IR instead of their final output. For Clang, this is e.g. clang++ -S -emit-llvm foo.cc, while for Rust this is rustc --emit=llvm-ir foo.rs. Godbolt will also respect these options and correctly display LLVM IR output.
If you click on the “Godbolt” widget, it will take you to a Godbolt that lowers it to LLVM IR. Most of that code is just metadata, but it’s really intimidating!
Starting from compiler output will have a steep difficulty curve, because we have to face the full complexity of LLVM IR. For Rust, this will likely mean encountering exception-handling, which is how panics are implemented, and function attributes that forward Rust’s guarantees (e.g. non-null pointers) to LLVM.
Instead, we’ll start by introducing the basic syntax of LLVM IR, and then we’ll tackle reading compiler output.
The meat of LLVM IR is function definitions, introduced with a define. There is also declare, which has exactly the same purpose as a function without a body in C: it brings an external symbol into scope.
For example, the following function takes no arguments and returns immediately:
The return type of the function (void) immediately follows the define keyword; the name of the function starts with an @, which introduces us to the concept of sigils: every user-defined symbol starts with a sigil, indicating what kind of symbol it is. @ is used for global and functions: things you can take the address of (when used as a value, they are always ptr-typed).
The body of a function resembles assembly: a list of labels and instructions. Unlike ordinary assembly, however, there are significant restrictions on the structure of these instructions.
In this case, there is only one instruction: a void-typed return. Unlike most assembly languages, LLVM IR is strongly typed, and requires explicit type annotations almost everywhere.
This function will trigger undefined behavior upon being called: the unreachable instruction represents a codepath that the compiler can assume is never executed; this is unlike e.g. the unimplemented ud2 instruction in x86, which is guaranteed to issue a fault.
This is an important distinction between LLVM IR and an assembly language: some operations are explicitly left undefined to leave room for potential optimizations. For example, LLVM can reason that, because @do_not_call immediately triggers undefined behavior, all calls to @do_not_call are also unreachable (and propagate unreachability from there).
Now our function takes arguments and has multiple instructions.
The argument is specified as i32 %x. Names a % sigil are sort of like local variables, but with some restrictions that make them more optimization-friendly; as we’ll see later, they’re not really “variable” at all. LLVM sometimes calls them registers; in a sense, LLVM IR is assembly for an abstract machine with an infinite number of registers. I’ll be calling %-prefixed names “registers” throughout this article.
i32 is a primitive integer types. All integer types in LLVM are of the form iN, for any N (even non-multiples of eight). There are no signed or unsigned types; instead, instructions that care about signedness will specify which semantic they use.
The first instruction is a mul i32, which multiples the two i32 operands together, and returns a value; we assign this to the new register %11. The next instruction returns this value.
The other arithmetic operations have the names you expect: add, sub, and, or, xor, shl (shift left). There are two division and remainder instructions, signed (sdiv, srem) and unsigned (udiv, urem). There two shift right instructions, again signed (ashr) and unsigned (lshr).
Exercise for the reader: why are /, %, and >> the only operations with signed and unsigned versions?
We can also convert from one integer type to another using trunc, zext, and sext, which truncate, zero-extend, and sign-extend, respectively (sext and zext are another signed/unsigned pair). For example, if we wanted the square function to never overflow, we could write
Here, we cast %x to i64 by sign-extension (since we’ve decided we’re squaring signed integers) and then square the result. trunc and zext both have the same syntax as sext.
Of course, interesting functions have control flow. Suppose we want a safe division function: division by zero is UB, so we need to handle it explicitly. Perhaps something like this:
However, this has a problem: division by zero is UB2, and select is not short-circuiting: its semantics are closer to that of cmov in x86.
To compile this correctly, need to use the br instruction, which represents a general branch operation3. In C terms, a br i1 %cond, label %a, label %b is equivalent to if (cond) goto a; else goto b;.
Now our function has labels, which are used by the br instruction as jump targets.
In the first block, we do the d == 0 check, implemented by an icmp eq instruction. This returns an i1 (the type LLVM uses for booleans). We then pass the result into a br instruction, which jumps to the first label if it’s zero, otherwise to the second if it isn’t.
The second block is the early-return; it returns the “sentinel” value; the third block is self-explanatory.
Each of these blocks is a “basic block”: a sequence of non-control flow operations, plus an instruction that moves control flow away from the block. These blocks form the control flow graph (CFG) of the function.
There are a few other “block terminator” instructions. The one-argument form of br takes a single label, and is a simple unconditional goto. There’s also switch, which is similar to a C switch:
The type of the switch must be an integer type. Although you could represent this operation with a chain of brs, a separate switch instruction makes it easier for LLVM to generate jump tables.
unreachable, which we saw before, is a special terminator that does not trigger control flow per se, but which can terminate a block because reaching it is undefined behavior; it is equivalent to e.g. std::unreachable() in C++.
The unreachable instruction provides a good example of why LLVM uses a basic block CFG: a naive dead code elimination (DCE) optimization pass can be implemented as follows:
Fill a set with every block that ends in unreachable.
For every block, if its terminator references a block in the unreachable set, delete that label from the terminator. For example, if we have br i1 %c, label %a, label %b, and the unreachable set contains %a, we can replace this with a br label %b.
If every outgoing edge from a block is deleted in (2), replace the terminator with unreachable.
Delete all blocks in the unreachable set.
Repeat from (1) as many times as desired.
Intuitively, unreachables bubble upwards in the CFG, dissolving parts of the CFG among them. Other passes can generate unreachables to represent UB: interplay between this and DCE results in the “the compiler will delete your code” outcome from UB.
The actual DCE pass is much more complicated, since function calls make it harder to decide if a block is “pure” and thus transparently deletable.
But, what if we want to implement something more complicated, like a / b + 1? This expression needs the intermediate result, so we can’t use two return statements as before.
Working around this is not so straightforward: if we try to assign the same register in different blocks, the IR verifier will complain. This brings us to the concept of static single assignment.
LLVM IR is a static single assignment form (SSA) IR. LLVM was actually started at the turn of the century to create a modern SSA optimizer as an academic project. These days, SSA is extremely fashionable for optimizing imperative code.
SSA form means that every register is assigned by at most one instruction per function. Different executions of the same block in the same function may produce different values for particular registers, but we cannot mutate already-assigned registers.
In other words:
Every register is guaranteed to be initialized by a single expression.
Every register depends only on the values of registers assigned before its definition.
This has many useful properties for writing optimizations: for example, within a basic block, every use of a particular register %x always refers to the same value, which makes optimizations like global value numbering and constant-folding much simpler to write, since the state of a register throughout a block doesn’t need to be tracked separately.
In SSA, we reinterpret mutation as many versions of a single variable. Thus, we might lower x += y as
Here, we’ve used a var.n convention to indicate which version of a variable a specific register represents (LLVM does not enforce any naming conventions).
However, when loops enter the mix, it’s not clear how to manage versions. The number of registers in a function is static, but the number of loop iterations is dynamic.
But there’s a problem! What are the original definitions of %r and %i? The IR verifier will complain that these registers depend directly on themselves, which violates SSA form. What’s the “right” way to implement this function?
One option is to ask LLVM! We’ll implement the function poorly, and let the optimizer clean it up for us.
First, let’s write the function using memory operations, like loads and stores, to implement mutation. We can use the alloca instruction to create statically-sized stack slots; these instructions return a ptr[^clang-codegen].
Incidentally, this is how Clang and Rust both generate LLVM IR: stack variables are turned into allocas and manipulated through loads and stores; temporaries are mostly turned into %regss, but the compiler will sometimes emit extra allocas to avoid thinking too hard about needing to create phi instructions.
This is pretty convenient, because it avoids needing to think very hard about SSA form outside of LLVM, and LLVM can trivially eliminate unnecessary allocas. The code I wrote for the codegen of @pow is very similar to what Rust would send to LLVM (although because we used an iterator, there’s a lot of extra junk Rust emits that LLVM has to work to eliminate).
definei32@pow(i32%x,i32%y){; Create slots for r and the index, and initialize them.; This is equivalent to something like; int i = 0, r = 1;; in C.%r=allocai32%i=allocai32storei321,ptr%rstorei320,ptr%ibrlabel%loop_startloop_start:; Load the index and check if it equals y.%i.check=loadi32,ptr%i%done=icmpeqi32%i.check,%ybri1%done,label%exit,label%looploop:; r *= x%r.old=loadi32,ptr%r%r.new=muli32%r.old,%xstorei32%r.new,ptr%r; i += 1%i.old=loadi32,ptr%i%i.new=addi32%i.old,1storei32%i.new,ptr%ibrlabel%loop_startexit:%r.ret=loadi32,ptr%rreti32%r.ret}
Next, we can pass this into the LLVM optimizer. The command opt, which is part of the LLVM distribution, runs specific optimizer passes on the IR. In our case, we want opt -p mem2reg, which runs a single “memory to register” pass. We can also just run opt --O2 or similar to get similar4 optimizations to the ones clang -O2 runs.
This is the result.
; After running through `opt -p mem2reg`definei32@pow(i32%x,i32%y){start:brlabel%loop_startloop_start:%i.0=phii32[0,%start],[%i.new,%loop]%r.0=phii32[1,%start],[%r.new,%loop]%done=icmpeqi32%i.0,%ybri1%done,label%exit,label%looploop:%r.new=muli32%r.0,%x%i.new=addi32%i.0,1brlabel%loop_startexit:reti32%r.0}
The allocas are gone, but now we’re faced with a new instruction: phi. “φ node” is jargon from the original SSA paper; the greek letter φ means “phoney”. These instructions select a value from a list based on which basic block we jumped to the block from.
For example, phi i32 [0, %start], [%i.new, %loop] says “this value should be 0 if we came from the start block; otherwise %i.new if it came from %loop”.
Unlike all other instructions, phi can refer to values that are not defined in all blocks that dominate the current block. This lets us have a dynamic number of versions of a variable! Here’s what that looks like in a dynamic execution context.
A block %a is said to dominate a block %b if each of its predecessors is either %a or a block dominated by %a. In other words, every path from the first block to %b passes through %a. In general instructions can only refer to values defined in previous instructions in the current block or values from blocks that dominate it.
%start directly jumps into %loop_start. The first block cannot be a jump target, since it cannot have phi nodes because its predecessors include function’s callsite.
In %loop_start, since we’ve entered from %start, %i.0 and %r.0 are selected to be the first versions of the (platonic) i and r variables, i.e., their initial values; we jump to %loop.
Then, %loop is dominated by %loop_start so we can use %i.0 and %r.0 there directly; these are the *= and += operations. Then we jump back to %loop_start.
Back in %loop_start, the phis now select %i.new and %r.new, so now %i.0 and %r.0 are the second versions of i and r. By induction, the nth execution of %loop_start has the nth versions of i and r.
When we finally get sent to %exit, we can use %r.0 (since %loop_start dominates %r.0), which will be the %yth version of r; this is our return value.
This is a good place to stop and think about what we’ve done so far. SSA, domination, and phis can be hard to wrap your head around, and are not absolutely necessary for reading most IR. However, it is absolutely worth trying to understand, because it captures essential facts about how compilers like to reason about code5.
With phi and br, we can build arbitrarily complicated control flow within a function6.
Now that we have basic scalar functions, let’s review LLVM’s type system.
We’ve seen i32 and its friends; these are arbitrary-bit-with integers. i1 is special because it is used as the boolean type. LLVM optimizations have been known to generate integer types with non-power-of-two sizes.
LLVM also has float and double, and some exotic float types like bfloat; these use their own arithmetic instructions with different options. I’ll pass on them in this explainer; see fadd and friends in the LangRef for more.
We’ve also seen void, which is only used as a return value, and ptr, which is an untyped7 pointer.
We’ve also seen the label pseudo-type, which represents a block label. It does not appear directly at runtime and has limited uses; the token and metadata types are similar.
Arrays are spelled [n x T]; the number must be an integer and the type must have a definite size. E.g., [1024 x i8]. Zero-sized arrays are supported.
Structs are spelled {T1, T2, ...}. E.g., {i64, ptr} is a Rust slice. Struct fields do not have names and are indexed, instead. The form <{...}> is a packed struct, which removes inter-field padding. E.g. #[repr(packed)] compiles down to this.
Vectors are like arrays but spelled <n x T>. These are used to represent types used in SIMD operations. For example, adding two <4 x i32> would lower to an AVX2 vector add on x86. I will not touch on SIMD stuff beyond this, although at higher optimization levels LLVM will merge scalar operations into vector operations, so you may come across them.
Type aliases can be created at file scope with the syntax
There are similar operations called insertelement and extractelement work on vectors, but have slightly different syntax and semantics.
Finally, there’s getelementptr, the “pointer arithmetic instruction”, often abbreviated to GEP. A GEP can be used to calculate an offset pointer into a struct. For example,
This function takes in a pointer, ostensibly pointing to an array of %MyStructs, and an index. This returns a pointer to the i64 field of the %idxth element of %p.
A few important differences between GEP and extractvalue:
It takes an untyped pointer instead of a value of a particular struct/array type.
There is an extra parameter that specifies an index; from the perspective of GEP, every pointer is a pointer to an array of unspecified bound. When operating on a pointer that does not (at runtime) point to an array, an index operand of 0 is still required. (Alternatively, you can view a pointer to T as being a pointer to a one-element array.)
Some other operations are very relevant for reading IR, but don’t fit into any specific category. As always, the LangRef provides a full description of what all of these instructions do.
Note that this could have been a %reg instead of a @global, which indicates a function pointer call.
Sometimes you will see invoke, which is used to implement “call a function inside of a C++ try {} block”. This is rare in Rust, but can occur in some C++ code.
Function calls are often noisy areas of IR, because they will be very heavily annotated.
The load and store instructions we’ve already seen can be annotated as atomic, which is used to implement e.g. AtomicU32::load in Rust; this requires that an atomic ordering be specified, too. E.g.,
The fence operation is a general memory fence operation corresponding to e.g. Rust’s std::sync::atomic::fence function.
cmpxchg provides the CAS (compare-and-swap) primitive. It returns a {T, i1} containing the old value and whether the CAS succeeded. cmpxchg weak implements the spuriously-failing “weak CAS” primitive.
Finally, atomicrmw performs a read-modify-write (e.g., *p = op(*p, val)) atomically. This is used to implement things like AtomicU32::fetch_add and friends.
All of these operations, except for fence, can also be marked as volatile. In LLVM IR, much like in Rust but unlike in C/C++, individual loads and stores are volatile (i.e., have compiler-invisible side-effects). volatilecan be combined with atomic operations (e.g. load atomic volatile), although most languages don’t provide access to these (except older C++ versions).
bitcast is what mem::transmute and reinterpret_cast in Rust and C++, respectively, ultimately compile into. It can convert any non-aggregate type (integers, vectors) to any other type of the same bit width. For example, it can be used to get at the bits of a floating-point value:
It also used to be what was used to cast pointer types (e.g. i32* to i8*). Pointers are now all untyped (ptr) so this use is no longer present.
However, bitcast cannot cast between pointer and integer data. For this we must use the inttoptr and ptrtoint9 instructions. These have the same syntax, but interact with the sketchy semantics of pointer-to-integer conversion and pointer provenance. This part of LLVM’s semantics is a bit of an ongoing trashfire; see Ralf Jung’s post for an introduction to this problem.
There is also a vast collection of LLVM intrinsics, which are specified in the LangRef. For example, if we need a particular built-in memcpy, we can bring it into scope with a declare:
LLVM exists to generate optimized code, and optimizations require that we declare certain machine states “impossible”, so that we can detect when we can simplify what the programmer has said. This is “undefined behavior”.
For example, we’ve already encountered unreachable, which LLVM assumes cannot be executed. Division by zero and accessing memory out of bounds is also undefined.
Most LLVM UB factors through the concept of “poisoned values”. A poison value can be thought of as “taking on every value at once”, whichever is convenient for the current optimization pass with no respect to any other passes. This also means that if optimizations don’t detect a use of poison, it is ok from LLVM’s perspective to give you a garbage value. This is most visible at -O0, which performs minimal optimization.
Using a poison value as a pointer in a load, store, or call must be UB, because LLVM can choose it to be a null pointer. It also can’t be the denominator of a udiv or similar, because LLVM can choose it to be zero, which is UB. Passing poison into a br or a switch is also defined to be UB.
LLVM can perform dataflow analysis to try to determine what operations a poisonous value that was used in a UB way came from, and thus assume those operations cannot produce poison. Because all operations (other than select and phi) with a poison input produce poison, backwards reasoning allows LLVM to propagate UB forward. This is where so-called “time traveling UB” comes from.
Many operations generate poison. For example, in C, signed overflow is UB, so addition lowers to an add nsw (nsw stands for no signed wrap). Instead of wrapping on overflow, the instruction produces poison. There is also an unsigned version of the annotation, nuw.
Many other operations have “less defined” versions, which are either generated by optimizations, or inserted directly by the compiler that invokes LLVM when the language rules allow it (see C above). More examples include:
udiv and friends have an exact annotation, which requires that the division have a zero remainder, else poison.
getelementptr has an inbounds annotation, which produces poison if the access is actually out of bounds. This changes it from a pure arithmetic operation to one more closely matching C’s pointer arithmetic restrictions. GEP without inbounds corresponds to Rust’s <*mut T>::wrapping_offset() function.
Floating point operations marked with nnan and ninf will produce poison instead of a NaN or an infinite value, respectively (or when a NaN or infinity is an argument).
Creating poison is not UB; only using it is. This is weaker than the way UB works in most languages; in C, overflow is instantly UB, but in LLVM overflow that is never “witnessed” is simply ignored. This is a simpler operational semantics for reasoning about the validity of optimizations: UB must often be viewed as a side-effect, because the compiler will generate code that puts the program into a broken state. For example, division by zero will cause a fault in many architectures. This means UB-causing operations cannot always be reordered soundly. Replacing “causes UB” with “produces poison” ensures the vast majority of operations are pure and freely reorderable.
This is the output, with metadata redacted and some things moved around for readability.
source_filename="example.b6eb2c7a6b40b4d2-cgu.0"targetdatalayout="e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"targettriple="x86_64-unknown-linux-gnu"; example::squaredefinei32@_ZN7example6square17hb32bcde4463f37c3E(i32%x)unnamed_addr#0{start:%0=call{i32,i1}@llvm.smul.with.overflow.i32(i32%x,i32%x)%_2.0=extractvalue{i32,i1}%0,0%_2.1=extractvalue{i32,i1}%0,1%1=calli1@llvm.expect.i1(i1%_2.1,i1false)bri1%1,label%panic,label%bb1bb1:reti32%_2.0panic:; core::panicking::paniccallvoid@_ZN4core9panicking5panic17ha338a74a5d65bf6fE(ptralign1@str.0,i6433,ptralign8@alloc_1368addac7d22933d93af2809439e507)unreachable}declare{i32,i1}@llvm.smul.with.overflow.i32(i32,i32)#1declarei1@llvm.expect.i1(i1,i1)#2; core::panicking::panicdeclarevoid@_ZN4core9panicking5panic17ha338a74a5d65bf6fE(ptralign1,i64,ptralign8)unnamed_addr#3@alloc_9be5c135c0f7c91e35e471f025924b11=privateunnamed_addrconstant<{[15xi8]}><{[15xi8]c"/app/example.rs"}>,align1@alloc_1368addac7d22933d93af2809439e507=privateunnamed_addrconstant<{ptr,[16xi8]}><{ptr@alloc_9be5c135c0f7c91e35e471f025924b11,[16xi8]c"\0F\00\00\00\00\00\00\00\02\00\00\00\03\00\00\00"}>,align8@str.0=internalconstant[33xi8]c"attempt to multiply with overflow"attributes#0={nonlazybinduwtable}attributes#1={nocallbacknofreenosyncnounwindspeculatablewillreturnmemory(none)}attributes#2={nocallbacknofreenosyncnounwindwillreturnmemory(none)}attributes#3={coldnoinlinenoreturnnonlazybinduwtable}
The main function is @_ZN7example6square17hb32bcde4463f37c3E, which is the mangled name of example::square. Because this code was compiled in debug mode, overflow panics, so we need to generate code for that. The first operation is a call to the LLVM intrinsic for “multiply and tell us if it overflowed”. This returns the equivalent of a (i32, bool); we extract both value out of it with extractvalue. We then pass the bool through @llvm.expect, which is used to tell the optimizer to treat the panicking branch as “cold”. The success branch goes to a return, which returns the product; otherwise, we go to a function that calls core::panicking::panic() to panic the current thread. This function never returns, so we can terminate the block with an unreachable.
The rest of the file consists of:
declares for the llvm intrinsics we used.
A declare for core::panicking::panic. Any external function we call needs to be declared. This also gives us a place to hang attributes for the function off of.
Global constants for a core::panic::Location and a panic message.
Attributes for the functions above.
This is a good place to mention attributes: LLVM has all kinds of attributes that can be placed on functions (and function calls) to record optimization-relevant information. For example, @llvm.expect.i1 is annotated as willreturn, which means this function will eventually return; this means that, for example, any UB that comes after the function is guaranteed to occur after finite time, so LLVM can conclude that the code is unreachable despite the call to @llvm.expect.i1. The full set of attributes is vast, but the LangRef documents all of them!
LLVM IR is huge, bigger than any individual ISA, because it is intended to capture every interesting operation. It also has a rich annotation language, so passes can record information for future passes to make use of. Its operational semantics attempt to leave enough space for optimizations to occur, while ensuring that multiple sound optimizations in sequence are not unsound (this last part is a work in progress).
Being able to read assembly reveals what will happen, exactly, when code is executed, but reading IR, before and after optimization, shows how the compiler is thinking about your code. Using opt to run individual optimization passes can also help further this understanding (in fact, “bisecting on passes” is a powerful debugging technique in compiler development).
I got into compilers by reading LLVM IR. Hopefully this article inspires you to learn more, too!
Registers within a function may have a numeric name. They must be defined in order: you must define %0 (either as a register or a label), then %1, then %2, etc. These are often used to represent “temporary results”.
If a function does not specify names for its parameters, they will be given the names %0, %1, etc implicitly, which affect what the first explicit numeric register name you can use is. Similarly, if the function does not start with a label, it will be implicitly be given the next numeric name.
This can result in significant confusion, because if we have define void @foo(i32, i32) { ... }, the arguments will be %0 and %1, but if we tried to write %2 = add i32 %0, %1, we would get an extremely confusing parser error, because %2 is already taken as the name of the first block. ↩
For some reason, the optimizer can’t figure out that the select is redundant? Alive2 (an SMT-solver correctness checker for optimizations) seems to agree this is a valid optimization.
If you read my assembly article, you’ll recall that there are many branch instructions. On RV, we have beq, bne, bgt, and bge. Later on in the compilation process, after the optimizer runs, LLVM will perform instruction selection (isel) to choose the best machine instruction(s) to implement a particular LLVM instruction (or sequence), which is highly context-dependent: for example, we want to fuse an icmp eq followed by a br on the result into a beq.
Isel is far outside my wheelhouse, and doing it efficiently and profitably is an active area of academic research. ↩
Not exactly the same: language frontends like Clang and Rust will perform their own optimizations. For example, I have an open bug for LLVM being unable to convert && into & in some cases; this was never noticed, because Clang performs this optimization while lowering from C/C++ to LLVM, but Rust does not do the equivalent optimization. ↩
A more intuitive model is used in more modern IRs, like MLIR. In MLIR, you cannot use variables defined in other blocks; instead, each block takes a set of arguments, just like a function call. This is equivalent to phi instructions, except that now instead of selecting which value we want in the target, each predecessor specifies what it wants to send to the target.
If we instead treat each block as having “arguments”, we can rewrite it in the following fantasy syntax where register names are scoped to their block.
;; Not actual LLVM IR! ;;definei32@pow(i32%x,i32%y){br%loop_start(i320,i321)loop_start(i32%i,i32%r)%done=icmpeqi32%i.0,%ybri1%done,%exit(i32%r),%loop(i32%i,i32%r)loop(i32%i,i32%r)%r.new=muli32%r,%x%i.new=addi32%i,1br%loop_start(i32%i,i32%r)exit(i32%r)reti32%r}
What does the CFG look like? LLVM contains “optimization” passes that print the CFG as a file as a .dot file, which can be rendered with the dot command. For @safe_div, we get something like the following.
This is useful for understanding complex functions. Consider this Rust hex-parsing function.
Without optimizations, we get a bigger mess (most optimization passes are various CFG cleanups).
Exercise: try to trace through what each basic block is doing. You will want to open the SVGs in a separate tab to do that. I recommend following the optimized version, since it is much less noisy.
Comparing optimized vs. unoptimized is a good way to see how much the compiler does to simplify the stuff the language frontend gives it. At -O0? All allocas. At -O2? No allocas! ↩
Once upon a time we had typed pointers, like i32*. These turned out to generate more problems than they solved, requiring frequent casts in IR in exchange for mediocre type safety. See https://llvm.org/docs/OpaquePointers.html for a more complete history. ↩
Rust and C++ both have very similar operational semantics for their “anonymous function” expressions (they call them “closures” and “lambdas” respectively; I will use these interchangably). Here’s what those expressions look like.
The type of square in both versions is an anonymous type that holds the captures for that closure. In C++, this type provides an operator() member that can be used to call it, wheras in Rust, it implements FnOnce (and possibly FnMut and Fn, depending on the captures), which represent a “callable” object.
For the purposes of this article, I am going to regard “function item values” as being identical to closures that explicitly specify their inputs and outputs for all intents and purposes. This is not completely accurate, because when I write let x = drop;, the resulting object is generic, but whenever I say “a closure” in Rust, I am also including these closure-like types too.
There is one thing C++ closures can express which Rust closures can’t: you can’t create a “generic” closure in Rust. In particular, in C++ we can write this code.
The auto keyword in a closure in C++ does not work like in Rust. In Rust, if try to write “equivalent” code, let x = |val| val.len();, on its own, we get this error:
error[E0282]:typeannotationsneeded--><source>:4:12|4|letx=|val|val.len();|^^^---typemustbeknownatthispoint|help:considergivingthisclosureparameteranexplicittype|4|letx=|val:/* Type */|val.len();|++++++++++++
This is because in Rust, a closure argument without a type annotation means “please deduce what this should be”, so it participates in Rust’s type inference, wheras in C++ an auto argument means “make this a template parameter of operator()”.
How would we implement CallMany in Rust, anyways? We could try but we quickly hit a problem:
What should we put in the ???? It can’t be a type parameter of call_many, since that has a concrete value in the body of the function. We want to say that Fn can accept any argument that implements len. There isn’t even syntax to describe this, but you could imagine adding a version of for<...> that works on types, and write something like this.
The imaginary syntax for<T: Len> Fn(&T) -> usize means “implements Fn for all all types T that implement Len”. This is a pretty intense thing to ask rustc to prove. It is not unachievable, but it would be hard to implement.
For the purposes of this article, I am going to consider for<T> a plausible, if unlikely, language feature. I will neither assume it will ever happen, nor that we should give up on ever having it. This “middle of uncertainty” is important to ensure that we do not make adding this feature impossible in the discussion that follows.
Fn::call is analogous to operator() in C++. When we say that we want a “generic closure”, we mean that we want to instead have a trait that looks a bit more like this:
Notice how Args has moved from being a trait parameter to being a function parameter, and Output now depends on it. This is a slightly different formulation from what we described above, because we are no longer demanding an infinitude of trait implementations, but now the implementation of one trait with a generic method.
For our specific example, we want something like this.
This has the potential to get really, really ugly. I used this pattern for a non-allocating visitor I wrote recently, and it wasn’t pretty. I had to write a macro to cut down on the boilerplate.
This macro is, unsurprisingly, quite janky. It also can’t really do captures, because the $cb argument that contains the actual code is buried inside of a nested impl.
You might think “well Miguel, why don’t you hoist $cb into the Cb struct?” The problem is now that I need to write impl<'s, F: FnMut(&Parser<'s>, ???)> so that I can actually call the callback in the body of Resume::resume, but that brings us back to our trait bound problem from the start!
This is a general problem with this type of solution: there is no macro you can write that will capture an arbitrary closure to implement a trait by calling that closure, if the method being implemented is generic, because if you could, I wouldn’t have to bother with the macro.
The new Interface() {...} syntax mints a new class on the spot that implements Interface. You provide a standard class body between the braces, after the name of the type. You can also do this with a class type too.
Now, this is a bit tedious: I need to re-type the signature of the one method. This is fine if I need to implement a bunch of methods, but it’s a little annoying in the one-method case.
In Java 8 we got lambdas (syntax: x -> expr). Java made the interesting choice of not adding a Function type to be “the type of lambdas”. For a long time I thought this was a weird cop-out but I have since come to regard it as a masterclass in language design.
Instead, Java’s lambdas are a sort of syntax sugar over this anonymous class syntax.1 Instead, you need to assign a lambda to an interface type with a single abstract method, and it will use the body of the lambda to implement that one method.
Interfaces compatible with lambdas are called single abstract method (SAM) interfaces.
So, without needing to touch the existing library, I can turn the new syntax into this:
Mind, Java does provide a mess of “standard function interfaces” in the java.util.functional package, and quite a bit of the standard library uses them, but they don’t need to express the totality of functions you might want to capture as objects.
These “SAM closures” give closures a powerful “BYO interface” aspect. Lambdas in Java are not “function objects”, they are extremely lightweight anonymous classes the pertinent interface.
I think this can let us cut the gordian knot of generic closures in Rust.
In what remains I will propose how we can extend the traits that closures implement to be any SAM trait, in addition to the traits they implement ipso facto.
What’s a SAM trait in Rust? It’s any trait T with precisely ONE method that does not have a default implementation, which must satisfy the following constraints:
It must have a self parameter with type Self, &Self, or &mut Self.
It does not mention Self in any part of its argument types, its return type, or its where clauses, except for the aforementioned self parameter.
Has no associated consts and no GATs.
All of its supertraits are Copy, Send, or Sync.
These restrictions are chosen so that we have a shot at actually implementing the entire trait.
In addition to the Fn traits, ordinary closures automatically implement Clone, Copy, Send, and Sync as appropriate.
None of these traits are SAM, so we can safely allow them to be automatically derived for SAM closures to, under the same rules as for ordinary closures.
To request a SAM closure, I will use the tentative syntax of impl Trait |args| expr. This syntax is unambiguously an expression rather than an impl item, because a | cannot appear in a path-in-type, and impl $path must be followed by {, for or where. The precise syntax is unimportant.
Applied to the call_many example above, we get this.
This rewrite can happen relatively early, before we need to infer a type for x. We also need to verify that this trait’s captures are compatible with an &self receiver The same rules for when a trait implements Fn, FnMut, and FnOnce would decide which of the three receiver types the closure is compatible with.
Note that SAM closures WOULD NOT implement any Fn traits.
We are required to name the trait we want but its type parameters can be left up in the air. For example:
pubtraitTr<T>{typeOut;fnrun(x:T,y:implDisplay)->Option<Self::Out>;}// We can infer `T = i32` and `Tr::Out = String`.lettr=implTr<_>|x:i32,y|Some(format!("{}, {}"));
In general, unspecified parameters and associated types result in inference variables, which are resolved in the same way as the parameters of the Fn closures are.
In fact, we can emulate ordinary closures using SAM closures.
There are probably additional restrictions we will want to place on the SAM trait, but it’s not immediately clear what the breadth of those are. For example, we probably shouldn’t try to make this work:
traitUniversalFactory{fnmake<T>()->T;}letf=implUniversalFactory||{// How do I name T so that I can pass it to size_of?};
Backing up from the Java equivalent of lambdas, it seems not unreasonable to have a full-fledged expression version of impl that can make captures.
Syntactically, I will use impl Trait for { ... }. This is currently unambiguous, although I think that making it so that { cannot start a type is probably a non-starter.
Let’s pick something mildly complicated… like Iterator with an overriden method. Then we might write something like this.
The contents of the braces after for is an item list, except that variables from the outside are available, having the semantics of captures; they are, in effect, accesses of self without the self. prefix.
Hammering out precisely how this would interact with the self types of the functions in the body seems… complicated. Pretty doable, just fussy. There are also awkward questions about what Self is here and to what degree you’re allowed to interact with it.
Suppose that we could instead “just” write impl |x| x * x and have the compiler figure out what trait we want (to say nothing of making this the default behavior and dropping the leading impl keyword).
traitT1{fnfoo(&self);}traitT2{fnfoo(&self);}impl<T:T1>T2forT{fnfoo(&self){println!("not actually gonna call T1::foo() lmao");}}letx=||println!("hello");T2::foo(&x);// What should this print?
If the type of x implements T2 directly, we print "hello", but if we decide it implements T1 instead, it doesn’t, because we get the blanket impl. If it decides it should implement both… we get a coherence violation.
Currently, rustc does not have to produce impls “on demand”; the trait solver has a finite set of impls to look at. What we are asking the trait solver to do is to, for certain types, attempt to reify impls based on usage. I.e., I have my opaque closure type T and I the compiler decided it needed to prove a T: Foo bound so now it gets to perform type checking to validate whether it has an impl.
This seems unimplementable with how the solver currently works. It is not insurmountable! But it would be very hard.
It is possible that there are relaxations of this that are not insane to implement, e.g. the impl || expression is used to initialize an argument to a function that happens to be generic, so we can steal the bounds off of that type variable and hope it’s SAM. But realistically, this direction is more trouble than its worth.
Generic lambdas are extremely powerful in C++, and allow for very slick API designs; I often miss them in Rust. Although it feels like there is an insurmountable obstruction, I hope that the SAM interface approach offers a simpler, and possibly more pragmatic, approach to making them work in Rust.
Except for the part where they are extremely not. Where new T() {} mints a brand new class and accompanying .class file, Java lambdas use this complicated machinery from Java 7 to generate method handles on the fly, via the invokedynamic JVM instruction. This, I’m told, makes them much easier to optimize. ↩
Notice that we call the trait method Stringer::string directly on the value in question. This means that traits (at least, those currently in scope) inject their methods into the namespace of anything that implements them.
Now, this isn’t immediately a problem, because Rust’s namespace lookup rules are such that methods inherent to a type are searched for first:
traitStringer{fnstring(&self)->String;}structWoofer;implStringerforWoofer{fnstring(&self)->String{format!("woof")}}implWoofer{fnstring(&self)->String{format!("bark")}}// Prints `bark`.println!("{}",Woofer.string());
This means that traits cannot easily break downstream code by adding new methods, but there are a few possible hazards:
If the owner of a type adds a method with the same name as a trait method, it will override direct (i.e., foo.string()) calls to that trait method, even if the type owner is unaware of the trait method.
If traits A and B are in scope, and String implements both, and we call str.foo() (which resolves to A::foo()), and later B adds a new method B::foo(), the callsite for String will break. A and B’s owners do not need to be aware of each other for this to happen.
Of course, Rust has a disambiguation mechanism. Given any trait implementation Foo: Bar, we can reference its items by writing <Foo as Bar>::baz. However, this syntax is very unweildy (it doesn’t work with method chaining), so it doesn’t get used. As a result, small evolution hazards can build up in a large codebase.
Those who know me know that I often talk about a syntax that I call foo.Trait::method(), or “qualified method call syntax”. In this post, I want to discuss this syntax in more detail, and some related ideas, and how they factor into type and trait design.
This idea isn’t new; others have proposed it, and it forms the core of Carbon’s version of trait method calls (you can read more about Carbon’s name lookup story here).
Let’s recreate the original example in Carbon (bear in mind that I am not an expert on this language, and the semantics are still up in the air).
Notice 42.(Stringer.String)(): Carbon requires that we qualify the method call, because 42 has the concrete type i32. If this were in a generic context and we had a type variable bounded by Stringer, we could just write x.String(); no ambiguity.
In Carbon, all qualification uses ., so they have to add parens. Because Rust uses :: for qualifying paths, we don’t have this syntactic abiguity, so we can augment the syntax to allow more path expressions after the ..
That is, exactly one identifier and an optional turbofish. I would like to see this extended to allow any QualifiedPathInExpression after the . and before the parens. This would allow, for example:
Of course, this isn’t the only idea from Carbon’s interfaces worth stealing; Carbon also has a notion of “external” and “internal” impls; I will call these “impl modes”.
An external impl is like the one we showed above, whose methods can only be found by qualified lookup: foo.(Bar.Baz)(). An internal impl is one which is “part” of a type.
This also implies that we don’t need to import Stringer to call w.String().
There are definitely traits in Rust which fit into these modes.
Clone and Iterator almost always want to be internal. An iterator exists to implement Iterator, and cloning is a fundamental operation. Because both of these traits are in the prelude, it’s not a problem, but it is a problem for traits provided by a non-std crate, like rand::Rng. The lack of a way to do this leads to the proliferation of prelude modules and namespace pollution. (I think that preludes are bad library design.)
On the other hand, something like Debug wants to be external very badly. It almost never makes sense to call foo.fmt(), since that gets called for you by println! and friends; not to mention that all of the std::fmt traits have a method fmt(), making such a call likely to need disambiguation with UFCS. Borrow is similar; it exists to be a bound for things like Cow more than to provide the .borrow() method.
There’s also a third mode, which I will call “extension impls”. These want to inject methods into a type, either to extend it, like itertools, or as part of some framework, like tap. This use of traits is somewhat controversial, but I can sympathize with wanting to have this.
If we have paths-as-methods, we can use this classification to move towards something more like the Carbon model of method lookup, without impacting existing uses.
My strawman is to add a #[mode] attribute to place on trait impls, which allows a caller to select the behavior:
#[mode(extension)] is today’s behavior. The impl’s trait must be in scope so that unqualified calls like foo.method() resolve to it.
#[mode(internal)] makes it so that foo.method() can resolve to a method from this impl without its trait being in scope1. It can only be applied to impls that are such that you could write a corresponding inherent impl, so things like #[mode(internal)] impl<T> Trait for T { .. } are forbidden.
#[mode(external)] makes it so that foo.method() never resolves to a method from this impl. It must be called as Trait::method(foo) or foo.Trait::method().
Every trait would be #[mode(extension)] if not annotated, and it would be easy to migrate to external-by-default across an edition. Similarly, we could change whether a std impl is external vs extension based on the edition of the caller, and provide a cargo fix rewrite to convert from foo.method() to foo.Trait::method().
It may also make sense for traits to be able to specify the default modality of their impls, but I haven’t thought very carefully about this.
Note that moving in the external -> extension -> internal direction is not a breaking change, but moving the other way is.
The use in the impl indicates that we want to re-use Foo::boing to implement <Foo as Bar>::boing. This saves us having to write out a function signature, and results in less work for the compiler because that’s one less function we risk asking LLVM to codegen for us (at scale, this is a Big Deal).
You could imagine using delegation instead of #[mode]:
The reason I haven’t gone down this road is because delegation is a very large feature, and doesn’t give us a clean way to express #[mode(external)], which is a big part of what I want. A delegation-compatible way to express this proposal is to not add #[mode(internal)], and add use Trait::method; and use Trait::*; (and no other variations) inside of inherent impl blocks.
I don’t have the personal bandwidth to write RFCs for any of this stuff, but it’s something I talk about a lot as a potential evolution hazard for Rust. I hope that putting these ideas to paper can help make name resolution in Rust more robust.
This needs to carry a bunch of other restrictions, because it’s equivalent to adding inherent methods to the implee. For example, none of the methods can have the same name as a method in any other inherent or internal impl block, and internal impl methods should take lookup priority over extension impl methods during name lookup. ↩
Let’s say we’re building an allocator. Good allocators need to serve many threads simultaneously, and as such any lock they take is going to be highly contended. One way to work around this, pioneered by TCMalloc, is to have thread-local caches of blocks (hence, the “TC” - thread cached).
Unfortunately threads can be ephemeral, so book-keeping needs to grow dynamically, and large, complex programs (like the Google Search ranking server) can have tens of thousands of threads, so per-thread cost can add up. Also, any time a thread context-switches and resumes, its CPU cache will contain different cache lines – likely the wrong ones. This is because either another thread doing something compeltely different executed on that CPU, or the switched thread migrated to execute on a different core.
These days, instead of caching per-thread, TCMalloc uses per-CPU data. This means that book-keeping is fixed, and this is incredibly friendly to the CPU’s cache: in the steady-state, each piece of the data will only ever be read or written to by a single CPU. It also has the amazing property that there are no atomic operations involved in the fast path, because operations on per-CPU data, by definition, do not need to be synchronized with other cores.
This post gives an overview of how to build a CPU-local data structure on modern Linux. The exposition will be for x86, but other than the small bits of assembly you need to write, the technique is architecture-independent.
Concurrency primitives require cooperating with the kernel, which is responsible for global scheduling decisions on the system. However, making syscalls is quite expensive; to alieviate this, there has been a trend in Linux to use shared memory as a kernelspace/userspace communication channel.
Futexes are the classic “cas-with-the-kernel” syscall (I’m assuming basic knowledge of atomic operations like cas in this article). In the happy path, we just need to cas on some memory to lock a futex, and only make a syscall if we need to go to sleep because of contention. The kernel will perform its own cas on this variable if necessary.
Restartable sequences are another such proto-primitive, which are used for per-CPUuprogramming. The relevant syscall for us, rseq(2), was added in Linux 4.18. Its manpage reads
A restartable sequence is a sequence of instructions guaranteed to be executed atomically with respect to other threads and signal handlers on the current CPU. If its execution does not complete atomically, the kernel changes the execution flow by jumping to an abort handler defined by userspace for that restartable sequence.
A restartable sequence, or “rseq” is a special kind of critical section that the kernel guarantees executes from start to finish without any kind of preemption. If preemption does happen (because of a signal or whatever), userspace observes this as a jump to a special handler for that critical section. Conceptually it’s like handling an exception:
try{// Per-CPU code here.}catch(PremptionException){// Handle having been preempted, which usally just means// "try again".}
These critical sections are usually of the following form:
Read the current CPU index (the rseq mechanism provides a way to do this).
Index into some data structure and do something to it.
Complete the operation with a single memory write. This is the “commit”.
All the kernel tells us is that we couldn’t finish successfully. We can always try again, but the critical section needs to be such that executing any prefix of it, up to the commit, has no effect on the data structure. We get no opportunity to perform “partial rollbacks”.
In other words, the critical section must be a transaction.
Using rseqs requires turning on support for it for a particular thread; this is what calling rseq(2) (the syscall) accomplishes.
The signature for this syscall looks like this:
// This type is part of Linux's ABI.#[repr(C,align(32))]structRseq{cpu_id_start:u32,cpu_id:u32,crit_sec:u64,flags:u32,}// Note: this is a syscall, not an actual Rust function.fnrseq(rseq:*mutRseq,len:u32,flags:i32,signature:u32)->i32;
The syscall registers “the” Rseq struct for the current thread; there can be at most one, per thread.
rseq is a pointer to this struct. len should be size_of::<Rseq>(), and signature can be any 32-bit integer (more on this later). For our purposes, we can ignore flags on the struct.
flags on the syscall, on the other hand, is used to indicate whether we’re unregistering the struct; this is explained below.
In the interest of exposition, we’ll call the syscall directly. If you’ve never seen how a Linux syscall is done (on x86), you load the syscall number into rax, then up to six arguments in rdi, rsi, rdx, r10, r8, r91. We only need the first four.
The return value comes out in rax, which is 0 on success, and a negative of an errno code otherwise. In particular, we need to check for EINTR to deal with syscall interruption. (every Linux syscall can be interrupted).
Note the unregister parameter: this is used to tear down rseq support on the way out of a thread. Generally, rseq will be a thread-local, and registration happens at thread startup. Glibc will do this and has a mechanism for acquiring the rseq pointer. Unfortunately, the glibc I have isn’t new enough to know to do this, so I hacked up something to register my own thread local.
I had the bright idea of putting my Rseq struct in a box, which triggered an interesting bug: when a thread exits, it destroys all of the thread local variables, including the box to hold our Rseq. But if the thread then syscalls to deallocate its stack, when the kernel goes to resume, it will attempt to write the current CPU index to the rseq.cpu_id field.
This presents a problem, because the kernel is probably going to write to a garbage location. This is all but guaranteed to result in a segfault. Debuggers observe this as a segfault on the instruction right after the syscall instruction; I spent half an hour trying to figure out what was causing a call to madvise(2) to segfault.
Hence, we need to wrap our thread local in something that will call rseq(2) to unregister the struct. Putting everything together we get something like this.
fncurrent_thread_rseq()->*mutRseq{// This has to be its own struct so we can run a thread-exit destructor.pubstructRseqBox(Box<UnsafeCell<Rseq>>);implDropforRseqBox{fndrop(&mutself){unsafe{raw_rseq(self.0.get(),true,RSEQ_SIG);}}}thread_local!{staticRSEQ:RseqBox={// Has to be in a box, since we need pointer stability.letrseq=RseqBox(Box::new(UnsafeCell::new(Rseq{cpu_id_start:0,cpu_id:!0,crit_sec:0,flags:0,})));// Register it!!!unsafe{raw_rseq(rseq.0.get(),false,RSEQ_SIG);}rseq};}RSEQ.with(|ra|ra.0.get())}
Per Rust’s semantics, this will execute the first time we access this thread local, instead of at thread startup. Not ideal, since now we pay for an (uncontended) atomic read every time we touch RSEQ, but it will do.
To set up and execute a restartable sequence, we need to assemble a struct that describes it. The following struct is also defined by Linux’s syscall ABI:
start is the address of the first instruction in the sequence, and len is the length of the sequence in bytes. abort_handler is the address of the abort handler. version must be 0 and we can ignore flags.
Once we have a value of this struct (on the stack or as a constant), we grab RSEQ and atomically store the address of our CritSec to RSEQ.crit_sec. This needs to be atomic because the kernel may decide to look at this pointer from a different CPU core, but it likely will not be contended.
Note that RSEQ.crit_sec should be null before we do this; restartable sequences can’t nest.
Next time the kernel preempts our thread (and later gets ready to resume it), it will look at RSEQ.crit_sec to decide if it preempted a restartable sequence and, if so, jump to the abort handler.
Once we finish our critical section, we must reset RSEQ.crit_sec to 0.
There is a wrinkle: we would like for our CritSec value to be a constant, but Rust doesn’t provide us with a way to initialize the start and abort_handler fields directly, since it doesn’t have a way to refer2 to the labels (jump targets) inside the inline assembly. The simplest way to get around this is to assemble (lol) the CritSec on the stack, with inline assembly. The overhead is quite minimal.
On x86, this is what our boilerplate will look like:
letmutcs=MaybeUninit::<CritSec>::uninit();letmutok=1;asm!{r"
// We meed to do `rip`-relative loads so that this code is PIC;
// otherwise we'll get linker errors. Thus, we can't `mov`
// directly; we need to compute the address with a `lea`
// first.
// Initialize the first two fields to zero.
mov qword ptr [{_cs}], 0
// Load `90f` into `cs.start`. Note that this is 'forward
// reference' to the jump target `90:` below.
lea {_pc}, [90f + rip]
mov qword ptr [{_cs} + 8], {_pc}
// We need to get the difference `91f - 90f` into `cs.len`.
// To do that, we write `-90f` to it, and then add `91f`.
neg {_pc}
mov qword ptr [{_cs} + 16], {_pc}
lea {_pc}, [91f + rip]
add qword ptr [{_cs} + 16], {_pc}
// Same as the first line, but loading `cs.abort_handler`.
lea {_pc}, [92f + rip]
mov qword ptr [{_cs} + 24], {_pc}
// Write `&cs` to `RSEQ.crit_sec`. This turns on
// restartable sequence handling.
mov qword ptr [{rseq} + 8], {_cs}
90:
// Do something cool here (coming soon).
91:
// Jump over the abort handler.
jmp 93f
.int 0x53053053 // The signature!
92:
// Nothing special, just zero `ok` to indicate this was a failure.
// This is written this way simply because we can't early-return
// out of inline assembly.
xor {_ok:e}, {_ok:e}
93:
// Clear `RSEQ.crit_sec`, regardless of which exit path
// we took.
mov qword ptr [{rseq} + 8], 0
",_pc=out(reg)_,_ok=inout(reg)ok,_cs=in(reg)&mutcsas*mutCritSec,rseq=in(reg)current_thread_rseq(),}
Because this is inline assembly, we need to use numeric labels. I’ve chosen labels in the 90s for no particular reason. 90: declares a jump target, and 90f is a forward reference to that instruction address.
Most of this assembly is just initalizing a struct3. It’s not until the mov right before 90: (the critical section start) that anything interesting happens.
Immediately before 92: (the abort handler) is an .int directive that emits the same four-byte signature we passed to rseq(2) into the instruction stream. This must be here, otherwise the kernel will issue a segfault to the thread. This is a very basic control-flow integrity feature.
We clear RSEQ.crit_sec at the very end.
This is a lot of boilerplate. In an ideal world, we could have something like the following:
Unfortunately, this is very hard to do, because the constraints on restartable sequences are draconian:
Can’t jump out of the critical section until it completes or aborts. This means you can’t call functions or make syscalls!
Last instruction must be the commit, which is a memory store operation, not a return.
This means that you can’t have the compiler generating code for you; it might outline things or move things around in ways you don’t want. In something like ASAN mode, it might inject function calls that will completely break the primitive.
This means we muyst write our critical section in assembly. That assembly also almost unavoidably needs to be part of the boilerplate given above, and it means it can’t participate in ASAN or TSAN instrumentation.
In the interest of exposition, we can build a wrapper over this inline assembly boilerplate that looks something like this:
When I wrote the snippet above, I chose numeric labels in the 90s to avoid potential conflicts with whatever assembly gets pasted here. This is also why I used a leading _ on the names of some of the assembly constraints; thise are private to the macro. rseq isn’t, though, since callers will want to access the CPU id in it.
The intent is for the assembly string to be pasted over the // Do something cool here comment, and for the constraints to be tacked on after the boilerplate’s constraints.
But with that we now have access to the full rseq primitive, in slightly sketchy macro form. Let’s use it to build a CPU-local data structure.
get_cache() grabs a cache of pages off the global free list. This requires taking a lock or traversing a lockless linked list, so it’s pretty expensive. return_cache() returns a cache back to the global free list for re-use; it is a similarly expensive operation. Both of these operations are going to be contended like crazy, so we want to memoize them.
To achieve this, we want one slot for every CPU to hold the cache it (or rather, a thread running on it) most recently acquired, so that it can be reused. These slots will have “checkout desk” semantics: if you take a thing, you must put something in its place, even if it’s just a sign that says you took the thing.
Matthew Kulukundis came up with this idea, and he’d totally put this gif in a slide deck about this data structure.
As a function signature, this is what it looks like:
letfree_list:&FreeList=...;letper_cpu:&PerCpu<PageCache>=...;letiou=0as*mutPageCache;// Check out this CPU's cache pointer, and replace it with// an IOU note (a null pointer).letmutcache=per_cpu.checkout(iou);ifcache==iou{// If we got an IOU ourselves, this means another thread that// was executing on this CPU took the cache and left *us* with// a null, so we need to perform the super-expensive operation// to acquire a new one.cache=free_list.get_cache();}// Do stuff with `cache` here. We have unique access to it.cache.alloc_page(...);// Return the pointer to the checkout desk.cache=per_cpu.checkout(cache);ifcache!=iou{// Usually, we expect to get back the IOU we put into the cache.// If we don't, that probably means another thread (or// hundreds) are hammering this slot and fighting for page caches.// If this happens, we need to throw away the cache.free_list.return_cache(cache);}
The semantics of PerCpu<T> is that it is an array of nprocs (the number of logical cores on the system) pointers, all initialized to null. checkout() swaps the pointer stored in the current CPU’s slot in the PerCpu<T> with the replacement argument.
Unfortunately, this is cache-hostile. We expect that (depending on how ptrs is aligned in memory) for eight CPUs’ checkout pointers to be on the same cache line. This means eight separate cores are going to be writing to the same cache line, which is going to result in a lot of cache thrash. This memory wants to be in L1 cache, but will probably wind up mostly in shared L3 cache.
This effect is called “false sharing”, and is a fundamental part of the design of modern processors. We have to adjust for this.
Instead, we want to give each core a full cache line (64 bytes aligned to a 64-byte boundary) for it to store its pointer in. This sounds super wasteful (56 of those bytes will go unused), but this is the right call for a perf-sensitive primitive.
This amount of memory can add up pretty fast (two whole pages of memory for a 128-core server!), so we’ll want to lazilly initialize them. Our cache-friendly struct will look more like this:
pubstructPerCpu<T>{ptrs:Box<[AtomicPtr<CacheLine<*mutT>>]>,}// This struct wraps a T and forces it to take up an entire cache line.#[repr(C,align(64))]structCacheLine<T>(T);unsafeimpl<T>SendforPerCpu<T>{}unsafeimpl<T>SyncforPerCpu<T>{}
Initializing it requires finding out how many cores there are on the machine. This is a… fairly platform-specific affair. Rust does offer a “maximum paralellism” query in its standard library, but it is intended as a hint for how many worker threads to spawn, as opposed to a hard upper bound on the number of CPU indices.
Instead, we call get_nprocs_conf(), which is fine since we’re already extremely non-portable already. This is a GNU libc extension.
In code…
impl<T>PerCpu<T>{pubfnnew()->Self{extern"C"{// #include <sys/sysinfo.h>//// This function returns the maximum number of cores the// kernel knows of for the current machine. This function// is very expensive to call, so we need to cache it.fnget_nprocs_conf()->i32;}staticmutNPROCS:usize=0;staticINIT:Once=Once::new();INIT.call_once(||unsafe{NPROCS=get_nprocs_conf()asusize;});letlen=unsafe{NPROCS};letmutptrs=Vec::with_capacity(len);for_in0..len{ptrs.push(AtomicPtr::new(ptr::null_mut()));}Self{ptrs:ptrs.into_boxed_slice()}}}
Now’s the moment we’ve all be waiting for: writing our restartable sequence. As critical sections go, this one’s pretty simple:
Index into the ptrs array to get this CPU’s pointer-to-cache-line.
If that pointer is null, bail out of the rseq and initialize a fresh cache line (and then try again).
If it’s not null, swap replacement with the value in the cache line.
impl<T>PerCpu<T>{fncheckout(&self,mutreplacement:*mutT)->*mutT{// We need to try this operation in a loop, to deal with// rseq aborts.loop{letptrs=self.ptrs.as_ptr();letmutvcpu:i32=-1;letmutneed_alloc:i32=1;letresult:Result<(),RseqAbort>=rseq!{r"
// Load the current CPU number.
mov {vcpu:e}, dword ptr [{rseq} + 4]
// Load the `vcpu`th pointer from `ptrs`.
// On x86, `mov` is atomic. The only threads we might
// be condending with are those that are trying to
// initialize this pointer if it's null.
mov {scratch}, qword ptr [{ptrs} + 8 * {vcpu:r}]
// If null, exit early and trigger an allocation
// for this vcpu.
test {scratch}, {scratch}
jz 1f
// Make sure the outer code knows not to allocate
// a new cache line.
xor {need_alloc:e}, {need_alloc:e}
// Commit the checkout by exchanging `replacement`.
xchg {ptr}, qword ptr [{scratch}]
1:
",ptrs=in(reg)ptrs,scratch=out(reg)_,ptr=inout(reg)replacement,vcpu=out(reg)vcpu,need_alloc=inout(reg)need_alloc,};// We got preempted, so it's time to try again.ifresult.is_err(){continue}// If we don't need to allocate, we're done.ifneed_alloc==0{returnreplacement}// Otherwise, allocate a new cache line and cas it into// place. This is Atomics 101, nothing fancy.letmutcache_line=Box::new(CacheLine(ptr::null_mut()));loop{letcas=self.ptrs[vcpuasusize].compare_exchange_weak(ptr::null_mut(),cache_line.as_mut(),Ordering::AcqRel,Ordering::Relaxed,);matchcas{Ok(p)=>{// Successful allocation.debug_assert!(p.is_null());// Make sure to stop `cache_line`'s memory// from being freed by `Box`'s dtor.mem::forget(cache_line);break;}// Try again: this is a spurious failure.Err(p)ifp.is_null()=>continue,// Someone got here first; we can just discard// `Box`.Err(_)=>break,}}}}}
This code listing is a lot to take in. It can be broken into two parts: the restartable sequence itself, and the allocation fallback if the pointer-to-cache-line happens to be null.
The restartable sequence is super short. It looks at the pointer-to-cache-line, bails if its null (this triggers the later part of the function) and then does an xchg between the actual *mut T in the per-CPU cache line, and the replacement.
If the rseq aborts, we just try again. This is short enough that preemption in the middle of the rseq is quite rare. Then, if need_alloc was zeroed, that means we successfully committed, so we’re done.
Otherwise we need to allocate a cache line for this CPU. We’re now outside of the rseq, so we’re back to needing atomics. Many threads might be racing to be the thread that initializes the pointer-to-cache-line; we use a basic cas loop to make sure that we only initialize from null, and if someone beats us to it, we don’t leak the memory we had just allocated. This is an RMW operation, so we want both acquire and release ordering. Atomics 101!
Then, we try again. Odds are good we won’t have migrated CPUs when we execute again, so we won’t need to allocate again. Eventually all of the pointers in the ptrs array will be non-null, so in the steady state this needs_alloc case doesn’t need to happen.
This is just a glimpse of what per-CPU concurrent programming looks like. I’m pretty new to it myself, and this post was motivated by building an end-to-end example in Rust. You can read more about how TCMalloc makes use of restartable sequences here.
This is annoyingly different from the function calling convention, which passes arguments in rdi, rsi, rdx, rcx, r8, r9, with the mnemonic “Diana’s silk dress cost $89.” I don’t know a cute mnemonic for the syscall registers. ↩
It’s actually worse than that. You’d think you could do
but this makes the resulting code non-position-independent on x86. What this means is that the code must know at link time what address it will be loaded at, which breaks the position-independent requirement of many modern platforms.
Indeed, this code will produce a linker error like the following:
= note: /usr/bin/ld: /home/mcyoung/projects/cpulocal/target/debug/deps/cpulocal-a7eeabaf0b1f2c43.2l48u2rfiak1q1ik.rcgu.o:
relocation R_X86_64_32 against `.text._ZN8cpulocal15PerCpu$LT$T$GT$8checkout17h42fde3ce3bd0180aE'
can not be used when making a PIE object; recompile with -fPIE
collect2: error: ld returned 1 exit status
to be able to load the address of pointers at all. This can be worked around if you’re smart; after all, it is possible to put the addresses of functions into static variables and not have the linker freak out. It’s too hard to do in inline assembly tho. ↩
Basically this code, which can’t be properly-expressed in Rust.
I’m not really one to brag publicly about expensive toys, but a few weeks ago I managed to get one that’s really something special. It is a Curta Type II, a mechanical digital1 calculator manufactured in Liechtenstein between the 50s and 70s, before solid-state calculators killed them and the likes of slide-rules.
I have wanted one since I was a kid, and I managed to win an eBay auction for one.
The Curta Type II (and Solomon the cat)
It’s a funny looking device, somewhere between a peppermill and a scifi grenade. Mine has serial number 544065, for those keeping score, and comes in a cute little bakelite pod (which has left hand thread?!).
I wanna talk about this thing because unlike something like a slide rule, it shares many features with modern computers. It has operations, flags, and registers. Its core primitive is an adder, but many other operations can be built on top of it: it is very much a platform for complex calculations.
I’m the sort of person who read Hacker’s Delight for fun, so I really like simple numerical algorithms. This article is a survey of the operation of a Curta calculator and algorithms you can implement on it, from the perspective of a professional assembly programmer.
Many of the algorithms I’m going to describe here exist online, but I’ve found them to be a bit difficult to wrap my head around, so this article is also intended as a reference card for myself.
There are two Curta models, Type I and Type II, which primarily differ in the sizes of their registers. I have a Type II, so I will focus on the layout of that one.
The Curta is not a stored program computer like the one you’re reading this article on. An operator needs to manually execute operations. It is as if we had taken a CPU and pared it down to two of its most basic components: a register file and an arithmetic logic unit (ALU).
The Curta’s register file consists of three digital registers, each of which contains a decimal integer (i.e., each digit is from 0 to 9, rather than 0 to 1 like on a binary computer):
sr, the setting register, is located on the side of the device. The value in sr can be set manually by the operator using a set of knobs on the side of the device. The machine will never write to it, only read from it. It has 11 digits.
rr, the results register, is located at the top of the device along the black part of the dial. It is readable and writable by the machine, but not directly modifiable by the operator. It has 15 digits.
cr, the counting register, is located next to rr along the silver part of the dial. Like rr, it is only machine-modifiable. It has 8 digits.
sr, set to 1997.
rr is the black dial; cr is the silver one.
There are also two settings on the device that aren’t really registers, but, since they are changed as part of operation, they are a lot like the control registers of a modern computer.
The carriage (there isn’t an abbreviation for this one, so I’ll call it ca) is the upper knurled ring on the machine. It can be set to a value from 0 to 72. To set it, the operator lifts the ring up (against spring tension), twists it, and lets it spring back into the detent for the chosen value. This is a one-hand motion.
There is a small triangle in the middle of the top of the device that points at which of the digits in cr will get incremented.
ca raised and in motion.
Finally, rl, the reversing lever, is a small switch near the back of the device that can be in the up or down position. This is like a flag register: up is cleared, down is set.
We have all this memory, but the meat of a machine is what it can do. I will provide an instruction set for the Curta to aid in giving rigorous descriptions of operations you can perform with it.
The core operation of the Curta is “add-with-shift-and-increment”. This is a mouthful. At the very top of the machine is the handle, which is analogous to a clock signal pin. Every clockwise turn of this handle executes one of these operations. Internally, this is implemented using a variation on the Leibniz gear, a common feature of mechanical calculators.
The handle in "addition" mode.
This operation is not that complicated, it just does a lot of stuff. It takes the value of sr, left-shifts it (in decimal) by the value in ca, and adds it to rr. Also, it increments CR by 1 shifted by ca. In other words:
The Curta cannot handle negative numbers, so it will instead display the ten’s complement3 of a negative result. For example, subtracting 1 from 0 will produce all-nines.
You can detect when underflow or overflow occurs when the resulting value is unexpectedly larger or smaller than the prior value in rr, respectively. (This trick is necessary on architectures that lack a carry flags register, like RISC-V.)
Setting rl will reverse the sign of the operation done on cr during a turn of the handle. In addition mode, it will cause cr to be subtracted from, while in subtraction mode, it will cause it to be added to. Some complex algorithms make use of this.
Finally, the clearing lever can be used to clear (to zero) sr or rr, independently. It is a small ring-shaped lever that, while the carriage is raised, can be wiped past digits to clear them. Registers cannot be partially cleared.
Let’s give names to all the instructions the operator needs to follow, so we can write some assembly:
mr, or Machine Ready!, means to clear/zero every register. All Curta instructions use the term “Machine Ready” to indicate the beginning of a calculation session.
pturn is the core addition operation, a “plus turn”.
mturn is its subtraction twin, a “minus turn”.
set <flag> requests the operator set one of rl or sm.
clr <flag> is the opposite of set.
zero <reg> request a clear of one of rr or cr using the clearing lever.
add <reg>, <imm> requests manual addition of an immediate to sr or ca. This is limited by what mental math we can ask of the operator.
copy <reg>, sr requests a copy of the value in rr or cr to sr.
wrnp <reg>, <symbol> indicates we need to write down a value in any register to a handy notepad (hence write notepad), marked with <symbol>.
rdnp <reg>, <symbol> asks the operator to read a value recorded with wrnp.
if <cond>, <label> asks the operator to check a condition (in terms of cr, rr, and sr) and, if true, proceed to the instruction at the given label:. Here’s some examples of conditions we’ll use:
rr == 42, i.e., rr equals some constant value.
rr.ovflow, i.e., rr overflowed/underflowed due to the most recent pturn/mturn.
cr[1] == 9, i.e. cr’s second digit (zero-indexed, not like the physical device!) equals 9.
cr[0..ca] < sr[0..ca], i.e., cr, considering only the digits up to the setting of ca, is less than those same digits in sr.
goto <label> is like if without a condition.
done means we’re done and the result can be read off of rr (or cr).
Note that there is a lot of mental math in some of the conditions. Algorithms on the Curta are aimed to minimize what work the operator needs to do to compute a result, but remember that it is only an ALU: all of the control flow logic needs to be provided by the human operator.
None of this is real code, and it is specifically for the benefit of readers.
So, addition and subtraction are easy, because there are hardware instructions for those. There is, however, no direct way to do multiplication or division. Let’s take a look at some of our options.
Given that a Curta is kinda expensive, you can try out an online simulator if you want to follow along. This one is pretty simple and runs in your browser.
Here, we input the larger factor into sr, and then keep turning until cr contains the other factor. The result is 41820:
8364 * 5 == 41820
Of course, this does not work well for complex products, such as squaring 41820. You could sit there and turn the handle forty thousand times if you wanted to, or you might decided that you should get a better hobby, since modern silicon can do this in nanoseconds.
We can speed this up exponentially by making use of the distributive property and the fact that turn can incorporate multiplication by a power of 10.
Each nice round number here can be achieved in cr by use of ca. Our algorithm will look a bit like this:
square:mraddsr,41820loop:// Check if we're done.ifcr==41820,endinner:// Turn until the first `ca` digits of `cr` and the// other factor match.ifcr[1..ca]==41802[1..ca],inner_endpturngotoinnerinner_end:// Increment `ca` and repeat until done.addca,1gotoloopend:done
There are two loops. The inner loop runs as many turns as is necessary to get the next prefix of the factor into cr, then incrementing ca to do the next digit, and on and on until cr contains the entire other factor, at which point we can read off the result.
The actual trace of operations (omitting control flow), and the resulting contents of the registers sr/rr/mr/ca at each step, looks something like this:
The result can be read off from rr: 1748912400. In the trace, you can see cr get built up digit by digit, making this operation rather efficient.
41820 * 41820 == 1748912400
We can do even better, if we use subtraction. For example, note that 18 = 20 - 2; we can build up 18 in cr by doing only 4 turns rather than nine, according to this formula. Here’s the general algorithm for n * m:
mul:mraddsr,nloop:ifcr==m,end// Same as before, but if the next digit is large,// go into subtraction mode.ifm[ca]>5,by_subinner:ifcr[0..ca]==m[0..ca],inner_endpturngotoinnerby_sub:// Store the current `ca` position.wrnpca,sub_from// Find the next small digit (eg. imagine n * 199, we// want to find the 1).find_small:addca,1ifm[ca]>5,find_small// Set the digit to one plus the desired value for that// digit.outer_turns:pturnifcr[ca]!=m[ca]+1,outer_turns// Store how far we need to re-advance `ca`.wrnpca,continue_from// Go back to the original `ca` position and enter// subtraction mode.rdnpca,sub_fromsubs:subs_inner:// Perform subtractions until we get the value we want.ifcr[ca]==m[ca],subs_endmturngotosubs_innersubs_end:// Advance `ca` and keep going until we're done.addca,1ifca!=continue_from,subsgotoloopinner_end:addca,1gotoloopend:done
In exchange for a little overhead, the number of turns drops from 15 to 10. This is the fastest general algorithm, but some techniques from Hacker’s Delight can likely be applied here to make it faster for some products.
As a quick note, computing the cube of a number without taking extra notes is easy, so long as the number is already written down somewhere you can already see it. After computing n^2 by any of the methods above, we can do
cube:mraddsr,n// Perform a multiplication by `n`, then copy the result// into `sr`.copysr,rrzerorrzerocr// Perform another multiplication by `n`, but now with// its square in `sr`.done
Division is way more interesting, because it can be inexact, and thus produces a remainder in addition to the quotient. There are a few different algorithms, but the simplest one is division by repeated subtraction. Some literature calls this “division by breaking down”.
For small numbers, this is quite simple, such as 21 / 4:
This works by first getting the dividend into rr and resetting the rest of the machine. Then, with rl set, we subtract the divisor from rr until we get overflow, at which point we add to undo the overflow. The quotient will appear in cr: we set rl, so each subtraction incrementscr, giving us a count of mturns executed. The remainder appears in rr.
In this case, we get down to 1 before the next mturn underflows; the result of that underflow is to 99...97, the ten’s complement of -3. We then undo the last operation by pturning, getting 5 in cr: this is our quotient. 1 in rr is the remainder.
The same tricks from earlier work here, using ca to make less work, effectively implementing decimal long division of n/m:
div:// Set up the registers.mraddsr,npturnzerocrzerosraddsr,msetrl// Move `ca` to be such that the highest digit of// `sr` lines up with the highest digit of `rr`.addca,log(m)-log(n)+1loop:// Make subtractive turns until we underflow.inner:mturnif!rr.ovflow,inner// Undo the turn that underflowed by doing an addition.// Because `rl` is set, this will also conveniently subtract// from `cr`, to remove the extra count from the// underflowing turn.pturn// We're done if this is the last digit we can be subtracting.// Otherwise, decrement `ca` and start over.ifca==0,doneaddca,-1gotoloopend:done
For a quotient this big, you’ll need to work through all eight cr digits, which is a ton of work. At the end, we get a quotient of 22931333 and reminder 32.
3141592653 / 137 == 22931333, rem 32
Unfortunately, we can’t as easily “cheat” with subtraction as we did with multiplication, because we don’t know the value that needs to appear in cr.
Computing square roots by approximation is one of the premiere operations on the Curta. There’s a number of approaches. Newton’s method is the classic, but requires a prior approximation, access to lookup tables, or a lot of multiplication.
A slower, but much more mechanical approach is to use Töpler’s method. This consists of observing that the sum of the first n odd numbers is the square of n. Thus, we can use an approach similar to that for division, only that we now subtract off consecutive odd numbers. Let’s take the square root of 92:
We get 9 as our result, but that’s pretty awful precision. We can improve precision by multiplying 92 by a large, even power of ten, and then dividing the result by that power of ten’s square root (half the zeroes).
Unfortunately, this runs into the same problem as naive multiplication: we have to turn the handle a lot. Turning this algorithm into something that can be done exponentially faster is a bit fussier.
One approach (which I found on ) allows us to compute the root by shifting. Several programmers appear to have independently discovered this in the 70s or 80s.
It is based on the so-called “digit-by-digit” algorithm, dating back to at least the time of Napier. Wikipedia provides a good explanation of why this method works. However, I have not been able to write down a proof that this specific version works, since it incorporates borrowing to compute intermediate terms with successive odd numbers in a fairly subtle way. I would really appreciate a proof, if anyone knows of one!
The algorithm is thus, for a radicand n:
sqrt:mr// Put `ca` as far as it will go, and then enter// the radicand as far right as it will go, so you// get as many digits as possible to work with.addca,8addsr,n<<(8-log(n))pturnzerocrzerosr// Put a 1 under the leftmost pair of digits. This// assumes a number with an even number of digits.addsr,1<<(ca-1)setrlloop:sqrt_loop:// Add an odd number (with a bunch of zeros// after it.)mturnifrr.ovflow,sqrt_end// Increment sr by 2 (again, with a bunch of// zeros after it). This gives us our next odd// number.addsr,2<<(ca-1)gotosqrt_loopsqrt_end:// Note that we do NOT undo the increment of `sr`// that caused overflow, but we do undo the last// mturn.pturn// If `ca` is all the way to the right, we're out of// space, so these are all the digits we're getting.// Zeroing out `rr` also means we're done.ifca==1||rr==0,end// Subtract ONE from the digit in `sr` we were// incrementing in the loop. This results in an even// number.addsr,-(1<<(ca-1))// Decrement `ca` and keep cranking. addca,-1addsr,1<<(ca-1)gotoloopend:done
Over time, the digits 14121356 will appear in cr. This is the square root (although we do need to place the decimal point; the number of digits before it will be half of what we started with, rounded up).
There’s a quite a few other algorithms out there, but most of them boil down to clever use of lookup tables and combinations of the above techniques. For example, the so-called “rule of 3” is simply performing a multiplication to get a product into rr, and then using it as the dividend to produce a quotient of the form a * b / c in cr.
I hope that these simple numeric algorithms, presented in a style resembling assembly, helps illustrate that programming at such a low level is not hard, but merely requires learning a different bag of tricks.
Although this seems like an oxymoron, it is accurate! The Curta contains no electrical or electronic components, and its registers contain discrete symbols, not continuous values. It is not an analog computer! ↩
The Curta is a one-indexed machine, insofar as the values engraved on ca are not 0 to 7 but 1 to 8. However, as we all know, zero-indexing is far more convenient. Any place where I say “set ca to n”, I mean the n + 1th detent.
Doing this avoids a lot of otherwise unnecessary -1s in the prose. ↩
The ten’s complement of a number x is analogous to the two’s complement (i.e., the value of -x when viewed as an unsigned integer on a binary machine). It is equal to MAX_VALUE - x + 1, where MAX_VALUE is the largest value that x could be. For example, this is 999_999_999_999_999_999 (fifteen nines) for rr. ↩
C++ is famous for relegating important functionality often built into the language to its standard library1. C++11 added a number of very useful class templates intended to make generic programming easier. By far the most complicated is std::tuple<>, which is literally just a tuple.
If you click through to Godbolt, you’ll see it doesn’t: this feature doesn’t exist in C++2 (normally, you’d do std::tuple<Types...>, but we need to write down std::tuple somehow). The usual approach is to use some kind of recursive template, which can tend to generate a lot of code.
However, C++ does actually have tuples built into the language, as a C++11 feature… lambdas! As an extra challenge, we’re going to try to minimize the number of templates that the compiler needs to instantiate; std::tuple is famously bad about this and can lead to very poor build performance.
For our tuple library type, we need to solve the following problems:
How do we implement std::tuple() and std::tuple(args...)?
Alright, let’s back up. In C++11, we got lambdas, which are expressions that expand to anonymous functions. In C++, lambdas are closures, meaning that they capture (“close over”) their environment.
The [x] syntax is the captures. To represent a lambda, C++ creates an anonymous, one-time-use class. It has the captures as members (whether they be references or values) and provides the necessary operator(). In other words, this is approximately the desugaring:
Note the consts in _Lambda. By default, captured values are stored inline but marked const, and the operator() member is also const. We can remove that specifier in both location with the mutable keyword:
Lambdas can capture anything from their scope. In addition to values, they will capture any types visible from that location. This means that, if constructed in a function template, the generated class will effectively capture that template’s arguments. Thus:
This will create a new anonymous class capturing an arbitrary number of arguments, depending on the parameters passed to CaptureMany(). This will form the core of our tuple type.
We don’t want to leak the lambda into the template parameters of our tuple class, so we need it to be strictly in terms of the class’s template parameters. This is straightforward with decltype.
Regardless of what our C++ compiler calls the type, we are able to use it as a field. However, a problem arises when we try to write down the main “in-place” constructor, which consists of the usual forwarding-reference and std::forward boilerplate3:
The initialization for lambda_ doesn’t work, because the return type of TupleLambda is wrong! The compiler is required to synthesize a new type for every specialization of TupleLambda, and so TupleLambda<Types...>() and TupleLambda<Args...> return different types!
This requires a major workaround. We’d still like to use our lambda, but we need to give it a type that allows us to construct it before calling the constructors of Types.... We can’t use Types..., so we’ll do a switcheroo.
The following is boilerplate for a type that can hold a T in it but which can be constructed before we construct the T.
template<typenameT>classalignas(T)StorageFor{public:// Constructor does nothing.StorageFor()=default;// Constructs a T inside of data_.template<typename...Args>voidInit(Args&&...args){new(reinterpret_cast<T*>(&data_))T(std::forward<Args>(args)...);}// Allow dereferencing a StorageFor into a T, like// a smart pointer.constT*get()const{returnreinterpret_cast<constT*>(&data_);}T*get(){returnreinterpret_cast<T*>(&data_);}constT&operator*()const{return*get();}T&operator*(){return*get();}constT*operator->()const{returnget();}T*operator->(){returnget();}private:chardata_[sizeof(T)];};
The constructor does nothing; the T within is only constructed when Init() is called with T’s constructor arguments.
Init() forwards its arguments just like our non-functional constructor for Tuple. This time, the arguments get sent into T’s constructor via placement-new. Placement-new is special syntax that allows us to call a constructor directly on existing memory. It’s spelled like this: new (dest) T(args);.
operator*/operator-> turn StorageFor into a smart pointer over T, which will be useful later. The signatures of these functions aren’t important; it’s library boilerplate.
We can use this type like this:
// Create some storage.StorageFor<std::string>my_string;// Separately, initialize it using std::string's constructor// form char[N].my_string.Init("cool type!");// Print it out.absl::PrintF("%s\n",*my_string);// Destroy it. This must be done manually because StorageFor<T>// has a trivial destructor.using::std::string;my_string->~string();
StorageFor<T> will be the types that our lambda captures, making it possible to give it a consistent type without knowing which arguments we’ll use to initialize the contents.
But now we’re in another bind: how do we call the constructors? Even with placement-new, we can’t reach into the lambda’s data, and the layout of a lambda is compiler-specific. However, that’s from the outside. What if we accessed the lambda from the inside?
We modify the lambda to itself be generic and take a pack of forwarding references as arguments, which we can then pass into Init():
[args...] (auto&&... init_args) { declares a generic lambda. This means that there’s an imaginary template <typename... Args> on the operator() of the generated class. Because the argument type is Args&&, and Args is a template parameter of operator(), init_args is a pack of forwarding references. This is a C++14 feature.
Init(std::forward<decltype(init_args)>(init_args)) is a forwarded constructor argument. Nothing new here.
The outer (<expr>, ...) that the placement-new is wrapped in is a pack fold, which uses an operator to fold a pack of values into one. For example, (foo + ...) computes the sum of all elements in a pack. In our case, we’re folding with the comma operator ,. All this does is discard the elements of the pack (which are all void, regardless). This is a C++17 feature4
Taken together, this causes the constructor of each type in Types... to be run on the respective StorageFor<T> captures by the lambda when TupleLambda() was originally called. The double-nesting of a function-within-a-function can be a bit confusing: TupleLambda() is not what calls T’s constructor!
Actually, this won’t compile because Init() is not const, but the lambda’s operator() is. This is easily fixed by adding the mutable keyword:
We also need to mark the lambda_ parameter as mutable so that const functions can all it. We’ll just need to be careful we don’t actually mutate through it. This is necessary because we cannot (at least until C++23) write to the captures of a lambda and still be able to call it in const contexts:
We have std::tuple(args) but we still need std::tuple. But, we’ve already used up our one chance to touch the captures of the lambda… we can’t write down a lambda that has both a variadic operator() (many generic arguments) and a niladic operator() (no arguments).
But we can make it take a lambda itself! In this case, all that our “storage lambda” does now is call a callback with a pack of references. Calling lambda_() effectively “unpacks” it:
The decltype(auto) bit simply ensures that if callback returns a reference, then so does lambda_. By default, lambdas return auto, which will never deduce a reference (you’d need to write auto&, which conversely cannot deduce a value). Instead of using “auto deduction”, we can use the special decltype(auto) type to request “decltype deduction”, which can deduce both references and non-references. This comes in handy later.
Now we can refactor the two constructors to call lambda_ with different lambda arguments. Our original constructor will pass in the original body of lambda_, which calls Init() with args. The new constructor will simply call Init() with no args.
Copy and move are similar, but require interleaving two calls of lambda_:
template<typename...Types>classTuple{public:Tuple(constTuple&that){lambda_([&](StorageFor<Types>&...these){// Carefully take a const&, to make sure we don't call a// mutable-ref constructor.that.lambda_([&](constStorageFor<Types>&...those){(new(these.get())Types(*those),...);});});}Tuple(Tuple&&that){lambda_([&](StorageFor<Types>&...these){that.lambda_([&](StorageFor<Types>&...those){// Avoid std::move to cut down on instantiation.(new(these)Types(static_cast<Types&&>(*those)),...);});});}// ...};
This works up until we try to write Tuple tup2 = tup; Overload resolution will incorrectly route to the variadic constructor rather than the copy constructor, so a little bit of SFINAE is needed to grease the compiler’s wheels.
Keeping in the spirit of avoiding extra instantiation logic, we’ll use placement-new inside of a decltype as an ersatz std::enable_if:
This verifies that we can actually construct a Types from a Args (for each member of the pack). Because this is occurring in an unevaluated context, we can safely placement-new on nullptr. All new expressions produce a pointer value, and a comma-fold produces the last value in the fold, so the overall decltype() is T*, where T is the last element of the pack.
This decltype() is the type of a non-type template parameter, which we can default to nullptr, so the user never notices it.
Ok. We have all of our constructors. The code so far is at this footnote: 6.
std::apply(f, tup) is a relatively straight-forward function: call f by splatting tup’s elements int f as a pack. Because of how we’ve implemented lambda_, this is actually super simple:
(We’re possibly returning a reference, so note the decltype(auto)s.)
lambda_ is basically a funny std::apply already, just with the wrong arguments. The *places fixes this up. With some repetition, we can write down const- and &&-qualified overloads. We can even introduce a free function just like the one in the standard library:
The other unpacking operation, std::get, is trickier. This is usually where things get really hairy, because we need to get the ith type out of the lambda. There are many approaches for doing this, most of which involve recursive templates. I’ll present two approaches that don’t use recursive templates directly, but which can still be a bit slow, built-time-wise.
std::make_index_sequence is a funny type-level function that produces a pack of integers from 0 to i, given just i. This is usually fast, since most compilers will have intrinsics for doing it without needing to instantiate i templates. For example, in Clang, this is __make_integer_seq, which is used by libc++.
Thus, we can turn the problem of implementing get with a single i to implementing get with a pack:
We can then use this pack to cook up just the right lambda to grab just the capture we want out of lambda_. Specifically, we want a lambda that picks out its ith argument. Basically we want to write something with arguments like (auto..., auto, auto...), but somehow use the less_than_i pack to control the size of the first argument pack.
Sink<n> is a type that is implicitly convertible from anything, and has a dummy parameter we can key an expansion off-of. Hence GetImpl() looks like this:
If we’re ok being Clang-specific, Clang just gives us a magic type function that selects out of a pack. This means we can implement TupleType in terms of it:
(We’re returning a reference, so again note the decltype(auto).)
With that we have all of the functions we set out to implement. For kicks, we can add the relevant std specializations to enable structured bindings on our type (along with our get member function):
So, the end result is most of an implementation of std::tuple<>. Let’s see how well it builds. We’re going to compile the following code for n from 0 to 150 and measure how long it takes.
tuplet{/* 0 repeated n times */};t.get<0>();// ...t.get<n>();
And here’s the results on Clang 11 (what I had on-hand) on my Zen 2 machine:
We seem to beat libstdc++ by a factor of around 2, but libc++ appears to have us beat. This is because libc++ makes even more aggressive use of Clang’s intrinsics than we did, allowing them to do significantly better. Interestingly, using the builtin makes us perform worse. I’m actually not sure why this is.
But ultimately, this wasn’t really about beating libc++: it’s about having fun with C++ templates.
Arguably, because WG21, the body that standardizes C++, is bad at language evolution, but that’s not why we’re here. ↩
Basically every in-place constructor in C++ looks like this. It takes a variadic pack as a template parameter, and then takes && if that as its arguments. Args&& here is a forwarding reference, which means it is T& or T&& depending on the callsite. This overrides the usual template deduction rules, and is important for making sure that e.g. std::move propagates correctly.
We cannot write Types&& instead, because that would not be a forwarding reference. T&& refers to a forwarding reference argument only on a function template where T is a parameter of that function and not an enclosing entity. ↩
If C++17 is too much to ask, polyfilling isn’t too hard. Instead of (<expr>, ...);, we can write (void)(int[]){(<expr>, 0)...};, even if <expr> is a void expression. (<expr>, 0) is still a comma operator call, which discards the result of <expr> as before. The pack expands into an array of integers (a int[]), which we then discard with (void). This still has the behavior of evaluating <expr> once for each element of the pack. ↩
A deduction guide is a special piece of syntax introduced in C++17 intended to aid deducing the types of constructor calls. When we write std::tuple(a, b, c), the template arguments of std::tuple are deduced. However, the constructor call may not give sufficient information to properly deduce them, because we may be calling a constructor template.
This tells the compiler that when it encounters a call to a constructor of MyTypes that deduces the given types as its arguments, it should deduce the type after the -> for the template arguments of MyType, which can be arbitrary template argument expressions. ↩
Alkyne is a scripting language I built a couple of years ago for generating configuration blobs. Its interpreter is a naive AST walker1 that uses ARC2 for memory management, so it’s pretty slow, and I’ve been gradually writing a new evaluation engine for it.
This post isn’t about Alkyne itself, that’s for another day. For now, I’d like to write down some notes for the GC I wrote3 for it, and more generally provide an introduction to memory allocators (especially those that would want to collude with a GC).
This post is intended for people familiar with the basics of low-level programming, such as pointers and syscalls. Alkyne’s GC is intended to be simple while still having reasonable performance. This means that the design contains all the allocator “tropes,” but none of the hairy stuff.
My hope is readers new to allocators or GCs will come away with an understanding of these tropes and the roles they play in a modern allocator.
Thank you to James Farrell, Manish Goregaokar, Matt Kulukundis, JeanHeyd Meneide, Skye Thompson, and Paul Wankadia for providing feedback on various drafts of this article. This was a tough one to get right. :)
The Alkyne GC is solving a very specific problem, which allows us to limit what it actually needs to do. Alkyne is an “embeddable” language like JavaScript, so its heap is not intended to be big; in fact, for the benefit of memory usage optimizations, it’s ideal to use 32-bit pointers (a 4 gigabyte address space).
The heap needs to be able to manage arbitrarily-large allocations (for lists), and allocations as small as eight bytes (for floats4). Allocation should be reasonably quick, but due to the size of the heap, walking the entire heap is totally acceptable.
Because we’re managing a fixed-size heap, we can simply ask the operating system for a contiguous block of that size up-front using the mmap() syscall. An Alkyne pointer is simply a 32-bit offset into this giant allocation, which can be converted to and from a genuine CPU pointer by adding or subtracting the base address of the heap.
4GB Heap
+-------------------------------------------------+
| x |
+-------------------------------------------------+
^ ^
base base + ptr_to_x
The OS won’t actually reserve 4GB of memory for us; it will only allocate one system page (4KB) at a time. If we read or write to a particular page in the heap for the first time, the OS will only then find physical RAM to back it5.
Throughout, we’ll be working with this fixed-size heap, and won’t think too hard about where it came from. For our purposes, it is essentially a Box<[u8]>, but we’ll call it a Heap<[u8]> to make it clear this memory we got from the operating system (but, to be clear, the entire discussion applies just as well to an ordinary gigantic Box<[u8]>)
The Alkyne language does not have threads, so we can eschew concurrency. This significantly reduces the problems we will need to solve. Most modern allocators and garbage collectors are violently concurrent by nature, and unfortunately, much too advanced for one article. There are links below to fancier GCs you can poke around in.
To build a garbage collector, we first need an allocator. We could “just”6 use the system heap as a source of pages, but most garbage collectors collude with the allocator, since they will want to use similar data structures. Thus, if we are building a garbage collector, we might as well build the allocator too.
An allocator, or “memory heap” (not to be confused with a min-heap, an unrelated but wicked data structure), services requests for allocations: unique leases of space in the managed heap of various sizes, which last for lifetimes not known until runtime. These allocations may also be called objects, and a heap may be viewed as a general-purpose object pool.
The most common API for a heap is:
traitAllocator{// Returns a *unique pointer* managed by this allocator// to memory as large as requested, and as aligned// as we'd like.// // Returns null on failure.unsafefnalloc(&mutself,size:usize,align:usize)->*mutu8;// Frees a pointer returned by `Alloc` may be called at// most once.unsafefnfree(&mutself,ptr:*mutu8);}
Originally the examples were in C++, which I feel is more accessible (lol) but given that Alkyne itself is written in Rust I felt that would make the story flow better.
This is the “malloc” API, which is actually very deficient; ideally, we would do something like Rust’s Allocator, which requires providing size and alignment to both the allocation and deallocation functions.
Unfortunately7, this means I need to explain alignment.
“Alignment” is a somewhat annoying property of a pointer. A pointer is aligned to N bytes (always a power of 2) if its address is divisible by N. A pointer is “well-aligned” (or just “aligned”) if its address is aligned to the natural alignment of the thing it points to. For ints, this is usually their size; for structs, it is the maximum alignment among the alignments of the fields of that struct.
Performing operations on a pointer requires that it be aligned8. This is annoying because it requires some math. Specifically we need three functions:
/// Checks that `ptr` is aligned to an alignment.fnis_aligned(ptr:Int,align:usize)->bool{ptr&(align-1)==0}/// Rounds `ptr` down to a multiple of `align`.fnalign_down(ptr:Int,align:usize)->Int{ptr&!(align-1)}/// Rounds `ptr` up to a multiple of `align`.fnalign_up(ptr:Int,align:usize)->Int{// (I always look this one up. >_>)align_down(ptr+align-1,align)}/// Computes how much needs to be added to `ptr` to align it.fnmisalign(ptr:Int,align:usize)->usize{align_up(ptr,align)-ptr}
For the rest of the article I will assume I have these three functions available at any time for whatever type of integer I’d like (including raw pointers which are just boutique9 integers).
Also we will treat the Heap<[u8]> holding our entire heap as being infinitely aligned; i.e. as a pointer it is aligned to all possible alignments that could matter (i.e. page-aligned, 4KB as always). (For an ordinary Box<[u8]>, this is not true.)
structArena{heap:Heap<[u8]>,cursor:usize,}implAllocatorforArena{unsafefnalloc(&mutself,size:usize,align:usize)->*mutu8{// To get an aligned pointer, we need to burn some "alignment// padding". This is one of the places where alignment is// annoying.letneeded=size+misalign(self.heap.as_ptr(),align);// Check that we're not out of memory.ifself.heap.len()-self.cursor<needed{returnptr::null_mut();}// Advance the cursor and cut off the end of the allocated// section.self.cursor+=needed;&mutself.heap[self.cursor-size]as*mutu8;}unsafefnfree(&mutself,ptr:*mutu8){// ayy lmao}}
Arenas are very simple, but far from useless! They’re great for holding onto data that exists for the context of a “session”, such as for software that does lots of computations and then exits (a compiler) or software that handles requests from clients, where lots of data lives for the duration of the request and no longer (a webserver).
They are not, however, good for long-running systems. Eventually the heap will be exhausted if objects are not recycled.
Making this work turns out to be hard[citation-needed]. This is the “fundamental theorem” of allocators:
From here, we will gradually augment our allocator with more features to allow it to service all kinds of requests. For this, we will implement four common allocator features:
Blocks and a block cache.
Free lists.
Block merging and splitting.
Slab allocation.
All four of these are present in some form in most modern allocators.
The first thing we should do is to deal in fixed-size blocks of memory of some minimum size. If you ask malloc() for a single byte, it will probably give you like 8 bytes on most systems. No one is asking malloc() for single bytes, so we can quietly round up and not have people care. (Also, Alkyne’s smallest heap objects are eight bytes, anyways.)
Blocks are also convenient, because we can keep per-block metadata on each one, as a header before the user’s data:
To allow blocks to be re-used, we can keep a cache of recently freed blocks. The easiest way to do this is with a stack. Note that the heap is now made of Blocks, not plain bytes.
To allocate storage, first we check the stack. If the stack is empty, we revert to being an arena and increment the cursor. To free, we push the block onto the stack, so alloc() can return it on the next call.
structBlockCache{heap:Heap<[Block]>,cursor:usize,free_stack:Vec<*mutBlock>,}implAllocatorforBlockCache{unsafefnalloc(&mutself,size:usize,align:usize)->*mutu8{// Check that the size isn't too big. We don't need to// bother with alignment, because every block is// infinitely-aligned, just like the heap itself.ifsize>BLOCK_SIZE{returnptr::null_mut();}// Try to serve a block from the stack.ifletSome(block)=self.free_stack.pop(){return&mut*block.dataas*mutu8;}// Fall back to arena mode.ifself.cursor==self.heap.len(){returnptr::null_mut();}self.cursor+=1;&mutself.heap[self.cursor].dataas*mutu8}unsafefnfree(&mutself,ptr:*mutu8){// Use pointer subtraction to find the start of the block.letblock=ptr.sub(size_of::<Header>())as*mutBlock;self.free_stack.push(block);}}
This allocator has a problem: it relies on the system allocator! Heap came directly from the OS, but Vec talks to malloc() (or something like it). It also adds some pretty big overhead: the Vec needs to be able to resize, since it grows as more and more things are freed. This can lead to long pauses during free() as the vector resizes.
Cutting out the middleman gives us more control over this overhead.
Of course, no one has ever heard of a “free stack”; everyone uses free lists! A free list is the cache idea but implemented as an intrusive linked list.
A linked list is this data structure:
enumNode<T>{Nil,Cons(Box<(T,Node<T>)>),// ^~~ oops I allocated again}
This has the same problem of needing to find an allocator to store the nodes. An intrusive list avoids that by making the nodes part of the elements. The Header we reserved for ourselves earlier is the perfect place to put it:
structHeader{/// Pointer to the next and previous blocks in whatever/// list the block is in.next:*mutBlock,prev:*mutBlock,}
In particular we want to make sure block are in doubly-linked lists, which have the property that any element can be removed from them without walking the list.
list.root
|
v
+-> Block--------------------------+
| | next | null | data data data |
| +------------------------------+
+-----/------+
/ |
v |
+-> Block--------------------------+
| | next | prev | data data data |
| +------------------------------+
+-----/------+
/ |
v |
+-> Block--------------------------+
| | next | prev | data data data |
| +------------------------------+
+-----/------+
/ |
v |
Block--------------------------+
| null | prev | data data data |
+------------------------------+
We also introduce a List container type that holds the root node of a list of blocks, to give us a convenient container-like API. This type looks like this:
structList{/// The root is actually a sacrificial block that exists only to/// make it possible to unlink blocks in the middle of a list. This/// needs to exist so that calling unlink() on the "first" element/// of the list has a predecessor to replace itself with.root:*mutBlock,}implList{/// Pushes a block onto the list.unsafefnpush(&mutself,block:*mutBlock){letblock=&mut*block;letroot=&mut*self.root;if!root.header.next.is_null(){letfirst=&mut*root.header.next;block.header.next=first;first.header.prev=block;}root.header.next=block;block.header.prev=root;}/// Gets the first element of the list, if any.unsafefnfirst(&mutself)->Option<&mutBlock>{letroot=&mut*self.root;root.header.next.as_mut()}}
We should also make it possible to ask a block whether it is in any list, and if so, remove it.
implBlock{/// Checks if this block is part of a list.fnis_linked(&self)->bool{// Only the prev link is guaranteed to exist; next is// null for the last element in a list. Sacrificial// nodes will never have prev non-null, and can't be// unlinked.!self.header.prev.is_null()}/// Unlinks this linked block from whatever list it's in.fnunlink(&mutself){assert!(self.is_linked());if!self.header.next.is_null(){letnext=&mut*self.header.next;next.header.prev=self.header.prev;}// This is why we need the sacrificial node.letprev=&mut*self.header.prev;prev.header.next=self.header.next;self.header.prev=ptr::null_mut();self.header.next=ptr::null_mut();}}
This is a very early malloc() design, similar to the one described in the K&R C book. It does have big blind spot: it can only serve up blocks up to a fixed size! It’s also quite wasteful, because all allocations are served the same size blocks: the bigger we make the maximum request, the more wasteful alloc(8) gets.
The next step is to use a block splitting/merging scheme, such as the buddy system. Alkyne does not precisely use a buddy system, but it does something similar.
Alkyne does not have fixed-size blocks. Like many allocators, it defines a “page” of memory as the atom that it keeps its data structures. Alkyne defines a page to be 4KB, but other choices are possible: TCMalloc uses 8KB pages.
In Alkyne, pages come together to form contiguous, variable-size reams (get it?). These take the place of blocks.
Merging and splitting makes it hard to keep headers at the start of reams, so Alkyne puts them all in a giant array somewhere else. Each page gets its own “header” called a page descriptor, or Pd.
The array of page descriptors lives at the beginning of the heap, and the actual pages follow after that. It turns out that this array has a maximum size, which we can use to pre-compute where the array ends.
Currently, each Pd is 32 bytes, in addition to the 4KB it describes. If we divide 4GB by 32 + 4K, it comes out to around four million pages (4067203 to be precise). Rounded up to the next page boundary, this means that pages begin at the 127102nd 4K boundary after the Heap<[u8]> base address, or an offset of 0x7c1f400 bytes.
Having them all in a giant array is also very useful, because it means the GC can trivially find every allocation in the whole heap: just iterate the Pd array!
So! This is our heap:
+---------------------------------------+ <-- mmap(2)'d region base
| Pd | Pd | Pd | Pd | Pd | Pd | Pd | Pd | \
+---------------------------------------+ |--- Page Descriptors
| Pd | Pd | Pd | Pd | Pd | Pd | Pd | Pd | | for every page we can
+---------------------------------------+ | ever allocate.
: ... : |
+---------------------------------------+ |
| Pd | Pd | Pd | Pd | Pd | Pd | Pd | Pd | /
+---------------------------------------+ <-- Heap base address
| Page 0 | \ = region + 0x7c1f400
| | |
| | |--- 4K pages corresponding
+---------------------------------------+ | to the Pds above.
| Page 1 | | (not to scale)
| | |
| | |
+---------------------------------------+ |
: ... | |
+---------------------------------------+ |
| Page N | |
| | |
| | /
+---------------------------------------+
(not to scale by a factor of about 4)
prev and next are the intrusive linked list pointers used for the free lists, but now they are indices into the Pd array. The other fields will be used for this and the trope that follows.
Given a pointer into a page, we can get the corresponding Pd by align_down()‘ing to a page boundary, computing the index of the page (relative to the heap base), and then index into the Pd array. This process can be reversed to convert a pointer to a Pd into a pointer to a page, so going between the two is very easy.
I won’t cover this here, but Alkyne actually wraps Pd pointers in a special PdRef type that also carries a reference to the Heap; this allows implementing functions like is_linked(), unlink(), and data() directly.
I won’t show how this is implemented, since it’s mostly boilerplate.
There is one giant free list that contains all of the reams. Reams use their first page’s descriptor to track all of their metadata, including the list pointers for the free list. The len field additionally tracks how many additional pages are in the ream. gc_bits is set to 1 if the page is in use and 0 otherwise.
To allocate N continuous pages from the free ream list:
We walk through the free ream list, and pick the first one with at least N pages.
We “split” it: the first N pages are returned to fulfill the request.
The rest of the ream is put back into the free list.
If no such ream exists, we allocate a max-sized ream10 (65536 pages), and split that as above.
In a sense, each ream is an arena that we allocate smaller reams out of; those reams cannot be “freed” back to the ream they came from. Instead, to free a ream, we just stick it back on the main free list.
If we ever run out, we turn back into an arena and initialize the next uninitialized Pd in the big ol’ Pd array.
structReamAlloc{heap:Heap<[Page]>,cursor:usize,free_list:List,}/// The offset to the end of the maximally-large Pd array./// This can be computed ahead of time.constPAGES_START:usize=...;implAllocatorforReamAlloc{unsafefnalloc(&mutself,size:usize,align:usize)->*mutu8{// We don't need to bother with alignment, because every page is// already infinitely aligned; we only allocate at the page// boundary.letpage_count=align_up(size,4096)/4096;// Find the first page in the list that's big enough.// (Making `List` iterable is an easy exercise.)forpdin&mutself.list{ifpd.len<page_count-1{continue}ifpd.len==page_count-1{// No need to split here.pd.unlink();returnpd.data();}// We can chop off the *end* of the ream to avoid needing// to update any pointers.letnew_ream=pd.add(page_count);new_ream.len=page_count-1;pd.len-=page_count;returnnew_ream.data();}// Allocate a new ream. This is more of the same arena stuff.}unsafefnfree(&mutself,ptr:*mutu8){// Find the Pd corresponding to this page's pointer. This// will always be a ream's first Pd assuming the user// didn't give us a bad pointer.letpd=Pd::from_ptr(ptr);self.free_list.push(pd);}}
This presents a problem: over time, reams will shrink and never grow, and eventually there will be nothing left but single pages.
Top fix this, we can merge reams (not yet implemented in Alkyne). Thus:
Find two adjacent, unallocated reams.
Unlink the second ream from the free list.
Increase the length of the first ream by the number of pages in the second.
// `reams()` returns an iterator that walks the `Pd` array using// the `len` fields to find the next ream each time.forpdinself.reams(){ifpd.gc_bits!=0{continue}loop{letnext=pd.add(pd.len+1);ifnext.gc_bits!=0{break}next.unlink();pd.len+=next.len+1;}}
We don’t need to do anything to the second ream’s Pd; by becoming part of the first ream, it is subsumed. Walking the heap requires using reams’ lengths to skip over currently-invalid Pds, anyways.
We have two options for finding mergeable reams. Either we can walk the entire heap, as above, or, when a ream is freed, we can check that the previous and following reams are mergeable (finding the previous ream would require storing the length of a ream at its first and last Pd).
Which merging strategy we use depends on whether we’re implementing an ordinary malloc-like heap or a garbage collector; in the malloc case, merging on free makes more sense, but merging in one shot makes more sense for Alkyne’s GC (we’ll see why in a bit).
A slab allocator is a specialized allocator that allocates a single type of object; they are quite popular in kernels as pools of commonly-used object. The crux of a slab allocator is that, because everything is the same size, we don’t need to implement splitting and merging. The BlockCache above is actually a very primitive slab allocator.
Our Pd array is also kind of like a slab allocator; instead of mixing them in with the variably-sized blocks, they all live together with no gaps in between; entire pages are dedicated just to Pds.
The Alkyne page allocator cannot allocate pages smaller than 4K, and making them any smaller increases the relative overhead of a Pd. To cut down on book-keeping, we slab-allocate small objects by defining size classes.
A size class is size of smaller-than-a-page object that Alkyne will allocate; other sizes are rounded up to the next size class. Entire pages are dedicated to holding just objects of the same size; these are called small object pages, or simply slabs. The size class is tracked with the class field of the Pd.
Each size class has its own free list of partially-filled slabs of that size. For slabs, gc_bits field becomes a bitset that tracks which slots in the page are currently in-use, reducing the overhead for small objects to only a little over a single bit each!
In the diagram below, bits set in the 32-bit, little-endian bitset indicate which slots in the slab (no to scale!) are filled with three-letter words. (The user likes cats.)
Pd--------------------------------------------+
| gc_bits: 0b01010011111010100110000010101011 |
+---------------------------------------------+
Page--------------------------------------------+
| cat | ink | | hat | | jug | | fig |
+-----------------------------------------------+
| | | | | | zip | net | |
+-----------------------------------------------+
| | aid | | yes | | war | cat | van |
+-----------------------------------------------+
| can | cat | | | rat | | urn | |
+-----------------------------------------------+
Allocating an object is a bit more complicated now, but now we have a really, really short fast path for small objects:
Round up to the next highest size class, or else to the next page boundary.
If a slab size class… a. Check the pertinent slab list for a partially-filled slab. i. If there isn’t one, allocate a page per the instructions below and initialize it as a slab page. b. Find the next available slot with (!gc_bits).count_trailing_zeros(), and set that bit. c. Return page_addr + slab_slot_size * slot.
Else, if a single page, allocate from the single-page list. a. If there isn’t one, allocate from the ream list as usual.
Else, multiple pages, allocate a ream as usual.
Allocating small objects is very fast, since the slab free lists, if not empty, will always have a spot to fill in gc_bits. Finding the empty spot in the bitset is a few instructions (a not plust a ctz or equivalent on most hardware).
Alkyne maintains a separate free list for single free pages to speed up finding such pages to turn into fresh slabs. This also minimizes the need to allocate single pages off of large reams, which limits fragmentation.
Alkyne’s size classes are the powers of two from 8 (the smallest possible object) to 2048. For the classes 8, 16, and 32, which would have more than 64 slots in the page, we use up to 56 bytes on the page itself to extend gc_bits; 8-byte pages can only hold 505 objects, instead of the full 512, a 1% overhead.
Directly freeing an object via is now tricky, since we do not a priori know the size.
Round the pointer up to the next page boundary, and obtain that page’s Pd.
If this is a start-of-ream page, stick it into the appropriate free list (single page or ream, depending on the size of the ream).
Else, we can look at class to find the size class, and from that, and the offset of the original pointer into the page, the index of the slot.
Clear the slot’s index in gc_bits.
If the page was full before, place it onto the correct slab free list; if it becomes empty, place it into the page free list.
At this point, we know whether the page just became partially full or empty, and can move it to the correct free list.
Size classes are an important allocator optimization. TCMalloc takes this to an . These constants are generated by some crazy script based on profiling data.
Before continuing to the GC part of the article, it’s useful to go over what we learned.
A neat thing about this is that most of these tricks are somewhat independent. While giving feedback for an early draft, Matt Kulukundis shared this awesome talk that describes how to build complex allocators out of simple ones, and covers many of the same tropes as we did here. This perspective on allocators actually blew my mind.
Good allocators don’t just use one strategy; the use many and pick and chose the best one for the job based on expected workloads. For example, Alkyne expects to allocate many small objects; the slab pages were originally only for float objects, but it turned out to simplify a lot of the code to make all small objects be slab-allocated.
Even size classes are a deep topic: TCMalloc uses GWP telemetry from Google’s fleet to inform its many tuning parameters, including its comically large tables of size classes.
At this point, we have a pretty solid allocator. Now, let’s get rid of the free function.
Garbage collection is very different from manual memory management in that frees are performed in batches without cue from the user. There are no calls to free(); instead, we need to figure out which calls to free() we can make on the user’s behalf that they won’t notice (i.e., without quietly freeing pointers the user can still reach, resulting in a use-after-free bug). We need to do this as fast as we can.
Alkyne is a “tracing GC”. Tracing GCs walk the “object graph” from a root set of known-reachable objects. Given an object a, it will trace through any data in the object that it knows is actually a GC pointer. In the object graph, b is reachable from a if one can repeatedly trace through GC pointers to get from a to b.
Alkyne uses tracing to implement garbage collection in a two-step process, commonly called “mark-and-sweep”.
Marking consists of traversing the entire graph from a collection of reachable-by-definition values, such as things on the stack, and recording each object that is visited. Every object not so marked must therefore be definitely unreachable and can be reclaimed; this reclamation is called sweeping.
Alkyne reverses the order of operations somewhat: it “sweeps” first and then marks, i.e., it marks every value as dead and then, as it walks the graph, marks every block as alive. It then rebuilds the free lists to reflect the new marks, allowing the blocks to be reallocated. This is sometimes called “mark and don’t sweep”, but fixing up the free lists is effectively a sweeping step.
Marking and sweeping! (via Wikipedia, CC0)
Alkyne is a “stop-the-world” (STW) GC. It needs to pause all program execution while cleaning out the heap. It is possible to build GCs that do not do this (I believe modern HotSpot GCs very rarely stop the world), but also very difficult. Most GCs are world-stopping to some degree.
One thing we do not touch on is when to sweep. This is a more complicated and somewhat hand-wavy tuning topic that I’m going to quietly sweep under the rug by pointing you to how Go does it.
Delicate freeing of individual objects is quite difficult, but scorching the earth is very easy. To do this, we walk the whole Pd array (see, I said this would be useful!) and blow away every gc_bits. This leaves the heap in a broken state where every pointer appears to be dangling. This is “armageddon”.
To fix this up, we need to “resurrect” any objects we shouldn’t have killed (oops). The roots are objects in the Alkyne interpreter stack11. To mark an object, we convert a pointer to it into a Pd via the page-Pd correspondence, and mark it as alive by “allocating” it.
We then use our knowledge12 of Alkyne objects’ heap layout to find pointers to other objects in the heap (for example, the intepreter knows it’s looking at a list and can just find the list elements within, which are likely pointers themselves). If we trace into an object and find it has been marked as allocated, we don’t recurse; this avoids infinite recursion when encountering cycles.
It’s a big hard to give a code example for this, because the “mark” part that’s part of the GC is mixed up with interpreter code, so there isn’t much to show in this case. :(
At the end of this process, every reachable object will once again be alive, but anything we couldn’t reach stays dead.
(Alkyne currently does not make this optimization, but really should.)
Rather than flipping every bit, we flip the global convention for whether 0 or 1 means “alive”, implemented by having a global bool specifying which is which at any given time; this would alternate from sweep to sweep. Thus, killing every living object is now a single operation.
This works if the allocated bit of objects in the free lists is never read, and only ever overwritten with the “alive” value when allocated, so that all of the dead objects suddenly becoming alive isn’t noticed. This does not work with slab-allocated small objects: pages may be in a mixed state where they are partially allocated and partially freed.
We can still make this optimization by adding a second bit that tracks whether the page contains any living objects, using the same convention. This allows delaying the clear of the allocated bits for small objects to when the page is visited, which also marks the whole page as alive.
Pages that were never visited (i.e., still marked as dead) can be reclaimed as usual, ignoring the allocated bits.
At this point, no pointers are dangling, but newly emptied out pages are not in the free lists they should be in. To fix this, we can walk over all Pds and put them where they need to go if they’re not full. This is the kinda-but-not-really sweep phase.
The code for this is simpler to show than explaining it:
forpdinself.reams(){ifpd.gc_bits==0{pd.unlink();ifpd.len==0{unsafe{self.page_free_list.push(pd)}}else{unsafe{self.ream_free_list.push(pd)}}}elseifpd.is_full(){// GC can't make a not-full-list become full, so we don't// need to move it.}else{// Non-empty, non-full lists cannot be reams.debug_assert!(pd.class!=SizeClass::Ream);pd.unlink();unsafe{self.slab_free_lists[pd.class].push(pd)}}}
Of course, this will also shuffle around all pages that did not become partially empty or empty while marking. If the “instant apocalypse” optimization is used, this step must still inspect every Pd and modify the free lists.
However, it is a completely separate phase: all it does is find pages that did not survive the previous mark phase. This means that user code can run between the phases, reducing latency. If it turns out to be very expensive to sweep the whole heap, it can even be run less often than mark phases13.
This is also a great chance to merge reams, because we’re inspecting every page anyways; this is why the merging strategy depends on wanting to be a GC’s allocator rather than a normal malloc()/free() allocator.
…and that’s it! That’s garbage collection. The setup of completely owning the layout of blocks in the allocator allows us to cut down significantly on memory needed to track objects in the heap, while keeping the mark and sweep steps short and sweet. A garbage collector is like any other data structure: you pack in a lot of complexity into the invariants to make the actual operations very quick.
Alkyne’s GC is intended to be super simple because I didn’t want to think too hard about it (even though I clearly did lmao). The GC layouts are a whole ‘nother story I have been swirling around in my head for months, which is described here. The choices made there influenced the design of the GC itself.
There are still many optimizations to make, but it’s a really simple but realistic GC design, and I’m pretty happy with it!
Alkyne also does not provide finalizers. A finalizer is the GC equivalent of a destructor: it gets run after the GC declares an object dead. Finalizers complicate a GC significantly by their very nature; they are called in unspecified orders and can witness broken GC state; they can stall the entire program (if they are implemented to run during the GC pause in a multi-threaded GC) or else need to be called with a zombie argument that either can’t escape the finalizer or, worse, must be resurrected if it does!
If finalizers depend on each other, they can’t be run at all, for the same reason an ARC cycle cannot be broken; this weakness of ARC is one of the major benefits of an omniscient GC.
I learned earlier (the week before I started writing this article) that Go ALSO has finalizers and that they are similarly cursed. Go does behave somewhat more nicely than Java (finalizers are per-value and avoid zombie problems by unconditionally resurrecting objects with a finalizer).
Here are some other allocators that I find interesting and worth reading about, some of which have inspired elements of Alkyne’s design.
TCMalloc is Google’s crazy thread-caching allocator. It’s really fast and really cool, but I work for Google, so I’m biased. But it uses radix trees! Radix trees are cool!!!
Go has a garbage collector that has well-known performance properties but does not perform any wild optimizations like moving, and is a world-stopping, incremental GC.
Oilpan is the Chronimum renderer’s GC (you know, for DOM elements). It’s actually grafted onto C++ and has a very complex API reflective of the subtleties of GCs as a result.
libboehm is another C/C++ GC written by Hans Boehm, one of the world’s top experts on concurrency.
Orinoco is V8’s GC for the JavaScript heap (i.e., Chronimum’s other GC). It is a generational or moving GC that can defragment the heap over time by moving things around (and updating pointers). It also has a separate sub-GC just for short-lived objects.
Mesh is a non-GC allocator that can do compacting via clever use of mmap(2).
upb_Arena is an arena allocator that uses free-lists to allows fusing arenas together. This part of the μpb Protobuf runtime.
In other words, it uses recursion along a syntax tree, instead of a more efficient approach that compiles the program down to bytecode. ↩
Automatic Reference Counting is an automatic memory management technique where every heap allocation contains a counter of how many pointers currently point to it; once pointers go out of scope, they decrement the counter; when the counter hits zero the memory is freed.
This is used by Python and Swift as the core memory management strategy, and provided by C++ and Rust via the std::shared_ptr<T> and Arc<T> types, respectively. ↩
This is the file. It’s got fairly complete comments, but they’re written for an audience familiar with allocators and garbage collectors. ↩
This is a tangent, but I should point out that Alkyne does not do “NaN boxing”. This is a technique used by some JavaScript runtimes, like Spidermonkey, which represent dynamically typed values as either ordinary floats, or pointers hidden in the mantissas of 64-bit IEEE 754 signaling NaNs.
Alkyne instead uses something like V8’s Smi pointer compression, so our heap values are four bytes, not eight. Non-Smi values that aren’t on the stack (which uses a completely different representation) can only exist as elements of lists or objects. Alkyne’s slab allocator design (described below) is focused on trying to minimize the overhead of all floats being in their own little allocations. ↩
The operating system’s own physical page allocator is actually solving the same problem: given a vast range of memory (in this case, physical RAM), allocate it. The algorithms in this article apply to those, too.
Operating system allocators can be slightly fussier because they need to deal with virtual memory mappings, but that is a topic for another time. ↩
As you might expect, these scare-quotes are load-bearing. ↩
I tried leaving this out of the first draft, and failed. So many things would be simpler without fussing around with alignment. ↩
Yes yes most architectures can cope with unaligned loads and stores but compilers rather like to pretend that’s not true. ↩
Currently Alkyne has a rather small max ream size. A better way to approach this would be to treat the entire heap as one gigantic ream at the start, which is always at the bottom of the free list. ↩
In GC terms, these are often called “stack roots”. ↩
The interpreter simply knows this and can instruct the GC appropriately.
In any tracing GC, the compiler or interpreter must be keenly aware of the layouts of types so that it can generate the appropriate tracing code for each.
This is why grafting GCs to non-GC’d languages is non-trivial, even though people have totally done it: libboehm and Oilpan are good (albeit sometimes controversial) examples of how this can be done. ↩
With “instant apocalypse”, this isn’t quite true; after two mark phases, pages from the first mark phase will appear to be alive, since the global “alive” convention has changed twice. Thus, only pages condemned in every other mark phase will be swept; sweeping is most optimal after an odd number of marks. ↩
Almost a year ago I developed the moveit Rust library, which provides primitives for expressing something like C++’s T&& and move constructors while retaining Rust’s so-called “destructive move property”: moving a value transfers ownership, rather than doing a funny copy.
In an earlier blogpost I described the theory behind this library and some of the motivation, which I feel fairly confident about, especially in how constructors (and their use of pinning) are defined.
The old post is somewhat outdated, since moveit uses different names for a lot of things that are geared to fit in with the rest of Rust.
The core abstraction of moveit is the constructor, which are types that implement the New trait:
#[must_use]pubunsafetraitNew:Sized{/// The type to construct.typeOutput;/// Construct a new value in-place using the arguments stored/// in `self`.unsafefnnew(self,this:Pin<&mutMaybeUninit<Self::Output>>);}
A New type is not what is being constructed; rather, it represents a method of construction, resembling a specialized Fn trait. The constructed type is given by the associated type Output.
Types that can be constructed are constructed in place, unlike most Rust types. This is a property shared by constructors in C++, allowing values to record their own address at the moment of creation. Explaining why this is useful is a bit long-winded, but let’s assume this is a thing we want to be able to do. Crucially, we need the output of a constructor to be pinned, which is why the this output parameter is pinned.
Calling a constructor requires creating the output location in advance so that we can make it available to it in time:
// Create storage for the new value.letmutstorage=MaybeUninit::uninit();// Pin that storage on the stack; by calling this, we may never move// `storage` again, even after this goes out of scope.letuninit=Pin::new_unchecked(&mutstorage);// Now we can call the constructor. It's only unsafe because it assumes// the provided memory is uninitialized.my_new.new(uninit.as_mut());// This is now safe, since `my_new` initialized the value, so we can// do with it what we please.letresult=uninit.map_unchecked_mut(|mp|mp.assume_init_mut());
However, this is not quite right. Pin<P>’s docs are quite clear that we must ensure that, once we create an Pin<&mut T>, we must call T’s destructor before its memory is re-used; since reuse is unavoidable for stack data, and storage will not do it for us (it’s a MaybeUninit<T>, after all), we must somehow run the destructor separately.
This works, but isn’t ideal, because now we can’t write down something like a C++ move constructor without running into the classic C++ problem: all objects must be destroyed unconditionally, so now you can have moved-from state. Giving up Rust’s moves-transfer-ownership (i.e. affine) property is bad, but it turns out to be avoidable!
There are also some scary details around panics here that I won’t get into.
moveit instead provides a MoveRef<'frame, T> type that tries to capture the notion of what an “owning reference” could mean in Rust. An &move or &own type has been discussed many times, but implementing it in the full generality it would deserve as a language feature runs into some interesting problems due to how Box<T>, the heap allocated equivalent, currently behaves.
We can think of MoveRef<'frame, T> as wrapping the longest-lived&mut T reference pointing to a particular location in memory. The longest-lived part is crucial, since it means that MoveRef is entitled to run its pointee’s destructor:
// Notice parallels with EventuallyInit<T> above.impl<T:?Sized>DropforMoveRef<'_,T>{fndrop(&mutself){unsafe{ptr::drop_in_place(self.ptr)}}}
No reference to the pointee can ever outlive the MoveRef itself, by definition, so this is safe. The owner of a value is that which is entitled to destroy it, and therefore a MoveRefliterally owns its pointee. Of course, this means we can move out of it (which was the whole point of the original blogpost).
Because of this, we are further entitled to arbitrarily pin a MoveRef with no consequences: pinning it would consume the unpinned MoveRef (for obvious reasons, MoveRefs cannot be reborrowed) so no unpinned reference may outlive the pinning operation.
This gives us a very natural solution to the problem above: result should not be a Pin<&mut T>, but rather a Pin<MoveRef<'_, T>>:
letmutstorage=MaybeUninit::uninit();letuninit=Pin::new_unchecked(&mutstorage);my_new.new(uninit.as_mut());// This is now safe, since `my_new` initialized the value, so we can// do with it what we please.letresult=MoveRef::into_pinned(MoveRef::new_unchecked(uninit.map_unchecked_mut(|mp|mp.assume_init_mut())));
Quashing destruction isn’t new to Rust: we can mem::forget just about anything, leaking all kinds of resources. And that’s ok! Destructors alone cannot be used in type design to advert unsafe catastrophe, a well-understood limitation of the language that we have experience designing libraries around, such as Vec::drain().
MoveRef’s design creates a contradiction:
MoveRef is an owning smart pointer, and therefore can be safely pinned, much like Box::into_pinned() enables. Constructors, in particular, are designed to generate pinned MoveRefs!
Forgetting a MoveRef will cause the pointee destructor to be suppressed, but its storage will still be freed and eventually re-used, a violation of the Pin drop guarantee.
This would appear to mean that a design like MoveRef is not viable at all, and that this sort of “stack box” strategy is always unsound.
What about it? Even though we can trivially create a Pin<Box<i32>> via Box::pin(), this is a red herring. When we mem::forget a Box, we also forget about its storage too. Because its storage has been leaked unrecoverably, we are still, technically, within the bounds of the Pin contract. Only barely, but we’re inside the circle.
Interestingly, the Rust language has to deal with a similar problem; perhaps it suggests a way out?
Carefully crafted Rust code emits some very interesting assembly. I’ve annotated the key portion of the output with a play-by-play below.
#[inline(never)]pubfnsomeone_elses_problem(_:Box<i32>){// What goes in here isn't important,it just needs to// be an optimizer black-box.}pubfnmaybe_drop(flag:bool){letx=Box::new(42);ifflag{someone_elses_problem(x)}}
// See Godbolt widget above for full disassembly.example::maybe_drop:// ...// Allocate memory.call__rust_alloc// Check if allocation failed; panic if so.testrax,raxje.L.scream// Write a 42 to the memory.movdwordptr[rax],42// Check the flag argument (LLVM decided to put it in rbx). If// true, we go free the memory ourselves.testbl,blje.L.actually_our_problem// Otherwise, make it someone else's problem; they get to// free the memory for themselves. movrdi,raxpoprbxjmpexample::someone_elses_problem// ...
The upshot is that maybe_drop conditions the destructor of x on a flag, which is allocated next to it on the stack. Rust flips this flag when the value is moved into another function, and only runs the destructor when the flag is left alone. In this case, LLVM folded the flag into the bool argument, so this isn’t actually a meaningful perf hit.
These “drop flags” are key to Rust’s ownership model. Since ownership may be transferred dynamically due to reasonably complex control flow, it needs to leave breadcrumbs for itself to figure out whether the value wound up getting moved away or not. This is unique to Rust: in C++, every object is always destroyed, so no such faffing about is necessary.
Similarly, moveit can close this soundness hole by leaving itself breadcrumbs to determine if safe code is trying to undermine its guarantees.
In other words: in Rust, it is not sufficient to manage a pointer to manage a memory location; it is necessary to manage an explicit or implicit drop flag as well.
Wrapping it in a Cell is convenient and doesn’t cost us anything, since a MoveRef can never be made Send or Sync anyways. Inside of its destructor, we can flip the flag, much like Rust flips a drop flag when transferring ownership to another function:
But, how should we use it? The easiest way is to change the definition of moveit!() to construct a flag trap:
letmutstorage=MaybeUninit::uninit();letuninit=Pin::new_unchecked(&mutstorage);// Create a *trapped flag*, which I'll describe below.lettrap=TrappedFlag::new();// Run the constructor as before and construct a MoveRef.my_new.new(uninit.as_mut());letresult=MoveRef::into_pin(MoveRef::new_unchecked(Pin::into_inner_unchecked(uninit).assume_init_mut(),trap.flag(),// Creating a MoveRef now requires// passing in a flag in addition to // a reference to the owned value itself.));
The trap is a deterrent against forgetting a MoveRef: because the MoveRef’s destructor flips the flag, the trap’s destructor will notice if this doesn’t happen, and take action accordingly.
In moveit, this is actually implemented by having the Slot<T> type carry a reference to the trap, created in the slot!() macro. However, this is not a crucial detail for the design.
The trap is simple: if the contained drop flag is not flipped, it crashes the program. Because moveit!() allocates it on the stack where uses cannot mem::forget it, its destructor is guaranteed to run before storage’s destructor runs (although Rust does not guarantee destructors run, it does guarantee their order).
If a MoveRef is forgotten, it won’t have a chance to flip the flag, which the trap will detect. Once the trap’s destructor notices this, it cannot return, either normally or by panic, since this would cause storage to be freed. Crashing the program is the only1 acceptable response.
Some of MoveRef’s functions need to be adapted to this new behavior: for example, MoveRef::into_inner() still needs to flip the flag, since moving out of the MoveRef is equivalent to running the destructor for the purposes of drop flags.
In order for MoveRef to be a proper “new” reference type, and not just a funny smart pointer, we also need a Deref equivalent:
pubunsafetraitDerefMove:DerefMut+Sized{/// An "uninitialized" version of `Self`.typeUninit:Sized;/// "Deinitializes" `self`, producing an opaque type that will/// destroy the storage of `*self` without calling the pointee/// destructor.fndeinit(self)->Self::Uninit;/// Moves out of `this`, producing a `MoveRef` that owns its/// contents.unsafefnderef_move(this:&mutSelf::Uninit)->MoveRef<'_,Self::Target>;}
This is the original design for DerefMove, which had a two-phase operation: first deinit() was used to create a destructor-suppressed version of the smart pointer that would only run the destructor for the storage (e.g., for Box, only the call to free()). Then, deref_move() would extract the “inner pointee” out of it as a MoveRef. This had the effect of splitting the smart pointer’s destructor, much like we did above on the stack.
This has a number of usability problems. Not only does it need to be called through a macro, but deinit() isn’t actually safe: failing to call deref_move() is just as bad as calling mem::forget on the result. Further, it’s not clear where to plumb the drop flags through.
After many attempts to graft drop flags onto this design, I replaced it with a completely new interface:
pubunsafetraitDerefMove:DerefMut+Sized{/// The "pure storage" form of `Self`, which owns the storage/// but not the pointee.typeStorage:Sized;/// Moves out of `this`, producing a [`MoveRef`] that owns/// its contents.fnderef_move<'frame>(self,storage:DroppingSlot<'frame,Self::Storage>,)->MoveRef<'frame,Self::Target>whereSelf:'frame;}
Uninit has been given the clearer name of Storage: a type that owns just the storage of the moved-from pointer. The two functions were merged into a single, safe function that performs everything in one step, emitting the storage as an out-parameter.
The new DroppingSlot<T> is like a Slot<T>, but closer to a safe version of the EventuallyInit<T> type from earlier: its contents are not necessarily initialized, but if they are, it destroys them, and it only does so when its drop flag is set.
Box is the most illuminating example of this trait:
unsafeimpl<T>DerefMoveforBox<T>{typeStorage=Box<MaybeUninit<T>>;fnderef_move<'frame>(self,storage:DroppingSlot<'frame,Box<MaybeUninit<T>>>,)->MoveRef<'frame,T>whereSelf:'frame{// Dismantle the incoming Box into the "storage-only part".letthis=unsafe{Box::from_raw(Box::into_raw(self).cast::<MaybeUninit<T>>())};// Put the Box into the provided storage area. Note that we// don't need to set the drop flag; `DroppingSlot` does// that automatically for us.let(storage,drop_flag)=storage.put(this);// Construct a new MoveRef, converting `storage` from // `&mut Box<MaybeUninit<T>>` into `&mut T`.unsafe{MoveRef::new_unchecked(storage.assume_init_mut(),drop_flag)}}}
MoveRef’s own implementation illustrates the need for the explicit lifetime bound:
unsafeimpl<'a,T:?Sized>DerefMoveforMoveRef<'a,T>{typeStorage=();fnderef_move<'frame>(self,_:DroppingSlot<'frame,()>,)->MoveRef<'frame,T>whereSelf:'frame{// We can just return directly; this is a mere lifetime narrowing.self}}
Since this is fundamentally a lifetime narrowing, this can only compile if we insist that 'a: 'frame, which is implied by Self: 'frame. Earlier iterations of this design enforced it via a MoveRef<'frame, Self> receiver, which turned out to be unnecessary.
As of writing, I’m still in the process of self-reviewing this change, but at this point I feel reasonably confident that it’s correct; this article is, in part, written to convince myself that I’ve done this correctly.
The new design will also enable me to finally complete my implementation of a constructor and pinning-friendly vector type; this issue came up in part because the vector type needs to manipulate drop flags in a complex way. For this reason, the actual implementation of drop flags actually uses a counter, not a single boolean.
I doubt this is the last issue I’ll need to chase down in moveit, but for now, we’re ever-closer to true owning references in Rust.
Arguably, running the skipped destructor is also a valid remediation strategy. However, this is incompatible with what the user requested: they asked for the destructor to be supressed, not for it to be run at a later date. This would be somewhat surprising behavior, which we could warn about for the benefit of unsafe code, but ultimately the incorrect choice for non-stack storage, such as a MoveRef referring to the heap. ↩
A Turing tarpit is a programming language that is Turing-complete but very painful to accomplish anything in. One particularly notable tarpit is Brainfuck, which has a reputation among beginner and intermediate programmers as being unapproachable and only accessible to the most elite programmers hence the name, as Wikipedia puts it:
The language’s name is a reference to the slang term brainfuck, which refers to things so complicated or unusual that they exceed the limits of one’s understanding.
Assembly language, the “lowest-level” programming language on any computer, has a similar reputation: difficult, mysterious, and beyond understanding. A Turing tarpit that no programmer would want to have anything to do with.
Although advanced programmers usually stop seeing assembly as mysterious and inaccessible, I feel like it is a valuable topic even for intermediate programmers, and one that can be made approachable and interesting.
This series seeks to be that: assuming you have already been using a compiled language like Rust, C++, or Go, how is assembly relevant to you?
If you’re here to just learn assembly and don’t really care for motivation, you can just skip ahead.
This series is about learning to understand assembly, not write it. I do occasionally write assembly for a living, but I’m not an expert, and I don’t particularly relish it. I do read a ton of assembly, though.
As every programmer knows, computers are very stupid. They are very good at following instructions and little else. In fact, the computer is so stupid, it can only process basic instructions serially1, one by one. The instructions are very simple: “add these two values”, “copy this value from here to there”, “go run these instructions over here”.
A computer processor implements these instructions as electronic circuits. At its most basic level, every computer looks like the following program:
size_tprogram_counter=...;Instruction*program=...;while(true){Instructionnext=program[program_counter];switch(next.opcode){// Figure out what you're supposed to be doing and do it.}program_counter++;}
The array program is a your program encoded as a sequence of these “machine instructions” in some kind of binary format. For example, in RISC-V programs, each instruction is a 32-bit integer. This binary format is called machine code.
For example, when a RISC-V processor encounters the value 5407443 decoding circuitry decides that it means that it should take the value in the “register” a0, add 10 to it, and place the result in the register a1.
opcode describes what sort of instruction this is, and what format it’s in; 0b0010011 means it’s an “immediate arithmetic” instruction, which uses the “I-type” format, given above. fn further specifies what the operation does; 0b000, combined with the value of opcode, means this is an addition instruction.
rs1 is the source: it gives the name of the source register, a0, given by it index, 0b00101, i.e., 10. Similarly, rd specifies the destination a1 by its index 11. Finally, imm is the value to add, 0b000000000101, or 10. The constant value appears immediately in the instruction itself, so it’s called an immediate.
However, if you’re a human programming a computer, writing all of this by hand is… very 60s, and you might prefer to have a textual representation, so you can write this more simply as addi a1, a0, 10.
addi a1, a0, 10 is a single line of assembly: it describes a single instruction in text form. Assembly language is “just” a textual representation of the program’s machine code. Your assembler can convert from text into machine instructions, and a disassembler reverses the process.
The simple nature of these instructions is what makes assembly a sort of Turing tarpit: you only get the most basic operations possible: you’re responsible for building everything else.
There isn’t “an” assembly language. Every computer has a different instruction set architecture, or “ISA”; I use the terms “instruction set”, “architecture”, and “ISA” interchangeably. Each ISA has a corresponding assembly language that describes that ISA’s specific instructions, but they all generally have similar overall structure.
I’m going to focus on three ISAs for ease of exposition, introduced in this order:
RISC-V, a modern and fairly simple instruction set (specifically, the rv32gc variant). That’s Part I.
x86_64, the instruction set of the device you’re reading this on (unless it’s a phone, an Apple M1 laptop, or something like a Nintendo Switch). That’s Part II.
MOS 6502, a fairly ancient ISA still popular in very small microcontrollers. That’s Part III.
We’re starting with RISC-V because it’s a particularly elegant ISA (having been developed for academic work originally), while still being representative of the operations most ISAs offer.
In the future, I may dig into some other, more specialized ISAs.
It’s actually very rare to write actual assembly. Thanks to modern (relatively) languages like Rust, C++, and Go, and even things like Haskell and JavaScript, virtually no programmers need to write assembly anymore.
But that’s only because it’s the leading language written by computers themselves. A compiler’s job is, fundamentally, to write the the assembly you would have had to write for you. To better understand what a compiler is doing for you, you need to be able to read its output.
At this point, it may be worth looking at my article on linkers as a refresher on the C compilation model.
For example, let’s suppose we have the very simple C program below.
Clang, my C compiler of choice, can turn it directly into a library via clang -c square.c. -c asks the compiler to stop before the link step, outputting the object filesquare.o. We can ask the compiler to stop even sooner than that by writing clang -S square.c, which will output square.s, the assembly file the compiler produced! For this example, and virtually all others in this post, I’m using a RISC-V target: -target riscv32-unknown-elf -march=rv32gc.
If you build with -Oz to make the code as small as possible (this makes it easiest to see what’s going on, too), you get something like this:
There’s a lot going on! But pay attention to the two lines with a // !: the first is mul s0, a0, a0, which is the multiplication x *= x;. The second is call printf, which is our function call to printf()! I’ll explain what everything else means in short order.
Writing assembly isn’t a crucial skill, but being able to read it is. It’s actually so useful, that a website exists for quickly generating the assembly output of a vast library of compilers: the Compiler Explorer, frequently just called “godbolt” after its creator, Matt Godbolt. Being able to compare the output of different compilers can help understand what they do! Click on the godbolt button in the code fences to a godbolt for it.
“Low-level” languages like C aren’t the only ones where you can inspect assembly output. Godbolt supports Go: for example, click the godbolt button below.
So, let’s say you do want to read assembly. How do we do that?
Let’s revisit our square.c example above. This time, I’ve added comments explaining what all the salient parts of the code do, including the assembler directives, which are all of the form .blah. Note that the actual compiler output includes way more directives that would get in the way of exposition.
There’s a lot of terms below that I haven’t defined yet. I’ll break down what this code does gradually, so feel free to refer back to it as necessary, using this handy-dandy link.
// This tells the assembler to place all code that// follows in the `.text` section, where executable// data goes..text// This is just metadata that tools can use to figure out// how the executable was built..file"square.c"// This asks the assembler to mark `square_and_print`// as an externally linkable symbol. Other files that// refer to `square_and_print` will be able to find it// at link time..globlsquare_and_printsquare_and_print:// This is a label, which gives this position// in the executable a name that can be// referenced. They're very similar to `goto`// labels from C.//// We'll see more labels later on.// This is the function prologue, which "sets up" the// function: it allocates stack space and saves the// return address, along with other calling-convention// fussiness.addisp,sp,-16swra,12(sp)sws0,8(sp)// This is our `x *= x;` from before! Notice that the// compiler rewrote this to `temp = x * x;` at some// point, since the destination register is `s0`.muls0,a0,a0// These two instructions load the address of a string// constant; this pattern is specific to RISC-V.luia0,%hi(.L.str)addia0,a0,%lo(.L.str)// This copies the multiplication result into `a1`.mva1,s0// Call to printf!callprintf// Move `s0` into `a0`, since it's the return value.mva0,s0// This is the function epilogue, which restores state// saved in the prologue and de-allocates the stack// frame.lws0,8(sp)lwra,12(sp)addisp,sp,16// We're done; return from the function!ret// This tells the assembler to place what follows in// the `.rodata` section, for read-only constants like// strings..section.rodata.L.str:// Give our string constant a private name. By convention,// .L labels are "private" names emitted by the compiler.// Emit an ASCII string into `.rodata` with an extra null// terminator at the end: that's what the `z` stands for..asciz"%d\n"
All assemblers are different, but the core syntax tends to be the same. There are three main kinds of syntax productions:
Instructions, which consist of a mnemonic followed by some number of operands, such as addi sp, sp -16 and call printf above. These are the text encoding of machine code.
Labels, which consist of a symbol followed by a colon, like square_and_print: or .L.str:. These are used to let instruction operands refer to locations in the program.
Directives, which vary wildly by assembler. GCC-style assembly like that above uses a .directive arg, arg syntax, as seen in .text, .globl, and .asciz. They control the behavior of the assembler in various ways.
An assembler’s purpose is to read the .s file and serialize it as a binary .o file. It’s kind of like a compiler, but it does virtually no interesting work at all, beyond knowing how to encode instructions.
Directives control how this serialization occurs (such as moving around the output cursor); instructions are emitted as-is, and labels refer to locations in the object file. Simple enough, right?
The first token is called the mnemonic, which is a painfully terse abbreviation of what the instruction does. In this case, addi means “add with immediate”.
sp is a register. Registers are special variables wired directly into the processor that can be used as operands in instructions. The degree to which only registers are permitted as operands varies by architecture; RISC-V only allows registers, but x86, as we’ll see, does not. Registers come in many flavors, but sp is a GPR, or “general purpose register”; it holds a machine word-sized integer, which in the case of 32-bit RISC-V is… 32-bit2.
One of my absolute favorite parts of RISC-V is how it names its registers. It has 32 GPRs named x0 through x31. However, these registers have so-called “ABI names” that specify the role of each register in the ABI.
The usefulness of these names will be much more apparent when we discuss the calling convention, so feel free to come back to this later.
x0 is called zero, because of its special property: writes to it are ignored, and reads always produce zero. This is handy for encoding certain common operations: for example, it can be used to quickly get a constant value= into a register: addi rd, zero, 42.
x1, x2, x3, and x4 have special roles and generally aren’t used for general computation. The first two are the link register ra, which holds the return address, and sp, the stack pointer.
The latter two are gp and tp; the global ppointer and the thread ppointer; their roles are somewhat complicated, so we won’t discuss them in this post.
The remaining registers belong to one of three categories: argument registers, saved registers, and temporary registers, named so for their role in calling a function (as described below).
The argument registers are x10 through x17, and use the names a0 through a7. The saved registers are x8, x9, and x18 through x27, called s0, through s11. The temporary registers are x5 through x7 and x28 through x31, called t0 through t6.
As a matter of personal preference, you may notice me reaching for argument registers for most examples.
-16 is an immediate, which is a literal value that is encoded directly into the instruction. The encoding of addi sp, sp, -16 will include the binary representation of -16 (in the case of RISC-V, as a 12-bit integer). [The decoding example above]{#decoding-instructions} shows how immediates are literally encoded immediately in the instruction.
Immediates allow for small but fixed integer arguments to be encoded with high locality to the instruction, which is good for code size and performance.
The first operand in RISC-V is (almost) always the output. addi, rd, rs, imm should be read as rd = rs + imm. Virtually all assembler syntax follows this convention, which is called the three-address code.
Other kinds of operands exist: for example, call printf refers to the symbolprintf. The assembler, which doesn’t actually know where printf is, will emit a small note in the object file that tells the linker to find printf and splat it into the assembly according to some instructions in the note. These notes are called relocations.
The instructions lui a0, %hi(.L.str) and addi a0, a0, %lo(.L.str) use the %lo and %hi operand types, which are specific to RISC-V; they load the low 12 bits and high 20 bits of a symbol’s address into the immediate operand. This is a RISC-V-specific pattern for loading an address into a register, which most assemblers provide with the pseudoinstructionla a0, .L.str (where la stands for “load address”).
Most architectures have their own funny architecture-specific operand types to deal with the architecture’s idiosyncrasy.
Available instructions tend to be motivated by providing one of three classes of functionality:
A Turing-complete register machine execution environment. This lends to the Turing tarpit nature of assembly: only the absolute minimum in terms of control flow and memory access is provided.
Efficient silicon implementation of common operations on bit strings and integers, ranging from arithmetic to cryptographic algorithms.
Building a secure operating system, hosting virtual machines, and actuating hardware external to the processor, like a monitor, a keyboard, or speakers.
Instructions can be broadly classified into four categories: arithmetic, memory, control flow, and “everything else”. In the last thirty years, the bar for general-purpose architectures is usually “this is enough to implement a C runtime.”
Arithmetic makes up the bulk of the instruction set. This always includes addition, subtraction, and bitwise and, or, and xor, as well as unary not and negation.
In RISC-V, these come in two variants: a three-register version and a two-register, one immediate version. For example, add a0, a1, a2 is the three-register version of addition, while addi a0, a1, 42 is the immediate version. There isn’t a subi though, since you can just use negative immediates with addi.
not and neg are not actual instructions in RISC-V, but pseudoinstructions: not a0, a1 encodes as xori a0, a1, -1, while neg a0, a1 becomes sub a0, zero, a1.
Most instruction sets also have bit shifts, usually in three flavors: left shifts, right shifts, and arithmetic right shifts; arithmetic right shift is defined such that it behaves like division by powers of two on signed integers. RISC-V’s names for these instructions are sll, srl, and sra.
Multiplication and division are somewhat rarer, because they are expensive to implement in silicon; smaller devices don’t have them3. Division in particular is very complex to implement in silicon. Instruction sets usually have different behavior around division by zero: some architectures will fault, similar to a memory error, while some, like RISC-V, produce a well-defined trap value.
There is usually also a “copy” instruction that moves the value of one register to another, which is kind of like a trivial arithmetic instruction. RISC-V calls this mv a0, a1, but it’s just a pseudoinstruction that expands to addi a0, a1, 0.
Some architectures also offer more exotic arithmetic. This is just a sampler of what’s sometimes available:
Bit rotation, which is like a shift but bits that get shifted off end up at the other end of the integer. This is useful for a vast array of numeric algorithms, including ARX ciphers like ChaCha20.
Byte reversal, which can be used for changing the endianness of an integer; bit reversal is analogous.
Bit extraction, which can be used to form new integers out of bitfields of another.
Carry-less multiplication, which is like long multiplication but you don’t bother to carry anything when you add intermediates. This is used to implement Galois/Counter mode encryption.
Fused instructions, like xnor and nand.
Floating point instructions, usually implementing the IEEE 754 standard.
There is also a special kind of arithmetic instruction called a vector instruction, but I’ll leave those for another time.
Load instructions fetch memory from RAM into registers, while store instructions write it back. These instructions are what we use to implement pointers.
They come in all sorts of different sizes: RISC-V has lw, lh, and lb for loading 32-, 16-, and 8-bit values from a location; sw, sh, and sb are their store counterparts. 64-bit RISC-V also provides ld and sd for 64-bit loads and stores.
Load/store instructions frequently take an offset for indexing into memory. lw a1, 4(a0)4 is effectively a1 = a0[4], treating a0 like a pointer.
These instructions frequently have an alignment constraint: the pointer value must (or, at least, should) be divisible by the number of bytes being loaded. RISC-V, for example, mandates that lw only be used on pointers divisible by 4. This constraint simplifies the microarchitecture; even on architectures that don’t mandate it, aligned loads and stores are typically far faster.
This category also includes instructions necessary for implementing atomics, such as lock cmpxchg on x86 and lr/sc on RISC-V. Atomics are fundamentally about changing the semantics of reading and writing from RAM, and thus require special processor support.
Some architectures, like x86, 65816, and very recently, ARM, provide instructions that implement memcpy and its ilk in hardware: in x86, for example, this is called rep movsb.
Control flow is the secret ingredient that turns our glorified calculator into a Turing tarpit: they allow changing the flow of program execution based on its current state.
Unconditional jumps implement goto: given some label, the j label instruction jumps directly to it. j can be thought of as writing to a special pc register that holds the program counter. RISC-V also provides a dynamic jump, jr, which will jump to the address in a register. Function calls and returns are a special kind of unconditional jump.
Conditional jumps, often called branches, implement if. beq a0, a1, label will jump to label if a0 and a1 contain the same value. RISC-V provides branch instructions for all kinds of comparisons, like bne, blt, and bge.
Conditional and unconditional jumps can be used together to build loops, much like we could in C using if and goto.
For example, to zero a region of memory:
// Assume a0 is the start of the region, and a1 the// number of bytes to zero.// Set a1 to the end of the region.addia1,a0,a1loop_start:// If a0 == a1, we're done!beqa0,a1,loop_done// Store a zero byte to `a0` and advance the pointer.sbzero,0(a0)addia0,a0,1// Take it from the top!jloop_startloop_done:
No-op instructions do nothing: nop’s only purpose is to take up space in the instruction stream. No-op instructions can be used to pad space in the instruction stream, provide space for the linker to fix things up later, or implement nop sleds.
Instructions for poking processor state, like csrrw in RISC-V and wrmsr in x86 also belong in this category, as do “hinting” instructions like memory prefetches.
There are also instructions for special control flow: ecall is RISC-V’s “syscall” instruction, which “traps” to the kernel for it to do something; other architectures have similar instructions.
Unfortunately, there isn’t anything like function call syntax in assembly. As with everything else, we need do it instruction by instruction. All we do get in most architectures is a call instruction, which sets up a return address somewhere, and a ret instruction, which uses the return address to jump to where the function was called.
We need some way to pass arguments, return a computed value, and maintain a call stack, so that each function’s return address is kept intact for its ret instruction to consume. We also need this to be universal: if I pull in a library, I should be able to call its functions.
This mechanism is called the calling convention of the platform’s ABI. It’s a convention, because all libraries must respect it in their exposed API for code to work correctly at runtime.
At the instruction level, function calls look something like this:
Pre-call setup. The caller sets up the function call arguments by placing them in the appointed locations for arguments. These are usually either registers or locations on the stack. a. The caller also saves the caller-saved registers to the stack.
Jump to the function. The caller executes a call instruction (or whatever the function call instruction might be called – virtually all architectures have one). This sets the program counter to the first instruction of the callee.
Function prologue. The callee does some setup before executing its code. a. The callee reserves space on the stack in an architecture-dependent manner. b. The callee saves the callee-saved registers to this stack space.
Function body. The actual code of the function runs now! This part of the function needs to make sure the return value winds up wherever the return slot for the function is.
Function epilogue. The callee undoes whatever work it did in the prologue, such as restoring saved registers, and executes a ret (or equivalent) instruction to return.
Post-call cleanup. The caller is now executing again; it can unspill any saved state that it needs immediately after the function call, and can retrieve the return value from the return slot.
In some ABIs, such as C++’s on Linux, this is where the destructors of the arguments get run. (Rust, and C++ on Windows, have callee-destroyed arguments instead.)
When people say that function calls have overhead, this is what they mean. Not only does the call instruction cause the processor to slam the breaks on its pipeline, causing all kinds of work to get thrown away, but state needs to be delicately saved and restored across the function boundary to maintain the illusion of a callstack.
Small functions which don’t need to use as many registers can avoid some of the setup and cleanup, and leaf functions which don’t call any other functions can avoid basically all of it!
Almost all registers in RISC-V are caller-saved, except for ra and the “saved” registers s0 and s11.
Callee-saved registers are convenient, because they won’t be wiped out by function calls. We can actually see the call to printf use this: even though the compiler could have emitted mul a1, a0, a0 and avoided the mv, this is actually less optimal. We need to keep the value around to return, and a1 is caller-saved, so we would have had to spill a1 before calling printf, regardless of whether printf overwrites a1 or not. We would then have to unspill it into a0 before ret. This costs us a hit to RAM. However, by emitting mul s0, a0, a0; mv a1, s0, we speculatively avoid the spill: if printf is compiled such that it never touches s0, the value never leaves registers at all!
Arguments in the usual5 RISC-V calling convention, word-sized arguments are passed in the a0 through a7 registers, falling back to passing on the stack if they run out of space. If the argument is too big to fit in a register, it gets passed by reference instead. Arguments that fit into two registers can be split across registers.
We can see this in action above. The first argument, a string, is passed by pointer in a0; lui and addi do the work of actually putting that pointer into a0. The second argument x is passed in a1, copied from s0 where it landed from the earlier mul instruction.
Complex function signatures require much more6 work to set up.
Once we’re done getting arguments into place, we call, which switches execution over to printf’s first instruction. In addition, it stores the return address, specifically, the address of the instruction immediately after the call, into an architecture-specific location. On RISC-V, this is the special register ra.
addi sp, sp, -16, which we stared at so hard above, grows the stack by 16 bytes. sp holds the stack pointer, which points to the top of the stack at all times. The stack grows downwards (as in most architectures!) and must be aligned to 16-byte boundaries across function calls: even though square_and_print only uses eight of those bytes, the full 16 bytes must be allocated.
The two sw instructions that follow store (or “spill”) the callee-saved registers ra and s0 to the stack. Note that s1 through s11 are not spilled, since square_and_print doesn’t use them!
Th this point, the function does its thing, whatever that means. This includes putting the return value in the return slot, which, for a function that returns an int, is in a0. In general, the return slot is passed back to the caller much like arguments are: if it fits in registers, a0 and a1 are used; otherwise, the caller allocates space for it and passes a pointer to the return slot as a hidden argument (in e.g. a0)7.
The epilogue inverts all operations of the prologue in reverse, unspilling registers and shrinking the stack, followed by ret. On RISC-V, all ret does is jump to the location referred to by the ra register.
Of course, all this work is only necessary to maintain the illusion of a callstack; if square_and_print were a leaf function, it would not need to spill anything at all! This results in an almost trivial function:
Because leaf functions won’t call other functions, they won’t need to save the caller-saved tX registers, so they can freely use them instead of the sX registers.
Phew! We’re around six thousand words in, so let’s checkpoint what we’ve learned:
Computers are stupid, but can at least follow extremely basic instructions, which are encoded as binary.
Assembly language is human-readable version of these basic instructions for a particular computer.
Assembly language programs consist of instructions, labels, and directives.
Each instruction is a mnemonic followed by zero or more operands.
Registers hold values the machine is currently operating on.
Instructions can be broadly categorized as arithmetic, memory, control flow, and “miscellaneous” (plus vector and float instructions, for another time).
The calling convention describes the low-level interface of a general function, consisting of some pre-call setup, and a prologue and epilogue in each function.
That’s all for now. RISC-V is a powerful but reasonably simple ISA. Next time, we’ll dive into the much older, much larger, and much more complex Intel x86.
What’s a machine word, exactly? It really depends on context. Most popular architectures has a straight-forward definition: the size of a GPR or the size of a pointer, which are the same.
This is not true of all architectures, so beware. ↩
Thankfully, these can be polyfilled using the previous ubiquitous instructions. Hacker’s Delight contains all of the relevant algorithms, so I won’t reproduce them here. The division polyfills are particularly interesting. ↩
It’s a bit interesting that we don’t write lw a1, a0[4] in imitation of array syntax. This specific corner of the notation is shockingly diverse across assemblers: in ARM, we write ldr r0, [r1, #offset]; in x86, mov rax, [rdx + offset], or movq offset(%rdx), %rax for AT&T-flavored assemblers (which is surprisingly similar to the RISC-V syntax!); in 6502, lda ($1234, X). ↩
The calling convention isn’t actually determined by the architecture in most cases; that’s why it’s called a convention. The convention on x86 actually differs on Windows and Linux, and is usually also language-dependent; C’s calling convention is usually documented, but C++, Rust, and Go invent their own to handle language-specific fussiness.
Of course, if you’re writing assembly, you can do whatever you want (though the silicon may be optimized for a particular recommended calling convention).
The following listing shows how all kinds of different arguments are passed. The output isn’t quite what Clang emits, since I’ve cleaned it up for clarity.
#include<stdio.h>
#include<stdint.h>
#include<stdnoreturn.h>structPair{uint32_tx,y;};structTriple{uint32_tx,y,z;};structPacked{uint8_tx,y,z;};// `noreturn` obviates the// {pro,epi}logue in `call_it`.noreturnvoidall_the_args(uint32_ta0,uint64_ta1a2,structPaira3a4,structTriplea5_by_ref,uint16_ta6,structPackeda7,uint32_ton_the_stack,structTriplestack_by_ref);voidcall_it(void){structPairu={7,9};structTriplev={11,13,15};structPackedw={14,16,18};all_the_args(42,-42,u,v,5,w,21,v);}
call_it:// Reserve stack space.addisp,sp,-48// Get `&call_it.v` into `a3`.luia3,%hi(call_it.v)addia3,a3,%lo(call_it.v)// Copy contents of `*a3`// into `a0...a2`.lwa0,0(a3)lwa1,4(a3)lwa2,8(a3)// Create two copies of `v`// on the stack to pass by// reference.// This is `a5_by_ref`.swa2,40(sp)swa1,36(sp)swa0,32(sp)// This is `stack_by_ref`.swa2,24(sp)swa2,20(sp)swa0,16(sp)// Load the argument regs.addia0,zero,42addia1,zero,-42addia2,zero,-1addia3,zero,7addia4,zero,9// A pointer to `a5_by_ref`!addia5,sp,32addia6,zero,5// Note that `a7` is three// packed bytes!luia0,289addia7,a0,14// Store `21` on the top of// the stack (our "a8")addit0,zero,21swt0,0(sp)// Store a pointer to// `stack_by_ref` on the // second spot from the// stack top (our "a9")addit0,sp,16swt0,4(sp)// Call it!callall_the_argscall_it.v:// The constant `{11, 13, 15}`..word11.word13.word15
Note that sb s0, 0(s1) stores the input value x into the first element of the big array after calling memset. If we move the store to before, we can avoid much silliness, including some unnecessary spills:
Low level software usually has lots of .cc or .rs files. Even lower-level software, like your cryptography library, probably has .S containing assembly, my least favorite language for code review.
The lowest level software out there, firmware, kernels, and drivers, have one third file type to feed into the toolchain: an .ld file, a “linker script”. The linker script, provided to Clang as -Wl,-T,foo.ld1, is like a template for the final executable. It tells the linker how to organize code from the input objects. This permits extremely precise control over the toolchain’s output.
Very few people know how to write linker script; it’s a bit of an obscure skill. Unfortunately, I’m one of them, so I get called to do it on occasion. Hopefully, this post is a good enough summary of the linker script language that you, too, can build your own binary!
Everything in this post can be found in excruciating detail in GNU ld’s documentation; lld accepts basically the same syntax. There’s no spec, just what your linker happens to accept. I will, however, do my best to provide a more friendly introduction.
No prior knowledge of how toolchains work is necessary! Where possible, I’ve tried to provide historical context on the names of everything. Toolchains are, unfortunately, bound by half a century of tradition. Better to at least know why they’re called that.
On Windows, assembly files use the sensible .asm extension. POSIX we use the .s extension, or .S when we’d like Clang to run the C preprocessor on them (virtually all hand-written assembly is of the second kind).
I don’t actually have a historical citation2 for .s, other than that it came from the Unix tradition of obnoxiously terse names. If we are to believe that .o stands for “object”, and .a stands for “archive”, then .s must stand for “source”, up until the B compiler replaced them with .b files! See http://man.cat-v.org/unix-1st/1/b.
A final bit of trivia: .C files are obviously different from .c files… they’re C++ files! (Seriously, try it.)
This post is specifically about POSIX. I know basically nothing about MSVC and link.exe other than that they exist. The most I’ve done is helped people debug trivial __declspec issues.
I will also only be covering things specific to linking an executable; linking other outputs, like shared libraries, is beyond this post.
A linker is but a small part of a toolchain, the low-level programmer’s toolbox: everything you need to go from source code to execution.
The crown jewel of any toolchain is the compiler. The LLVM toolchain, for example, includes Clang, a C/C++3 compiler. The compiler takes source code, such as .cc, and lowers it down to a .s file, an assembly file which textually describes machine code for a specific architecture (you can also write them yourself).
Another toolchain program, the assembler, assembles each .s into a .o file, an object file4. An assembly file is merely a textual representation of an object file; assemblers are not particularly interesting programs.
A third program, the linker, links all of your object files into a final executable or binary, traditionally given the name a.out5.
This three (or two, if you do compile/assemble in one step) phase process is sometimes called the C compilation model. All modern software build infrastructure is built around this model6.
Clang, being based on LLVM, actually exposes one stage in between the .cc file and the .s file. You can ask it to skip doing codegen and emit a .ll file filled with LLVM IR, an intermediate between human-writable source code and assembly. The magic words to get this file are clang -S -emit-llvm. (The Rust equivalent is rustc --emit=llvm-ir.)
The LLVM toolchain provides llc, the LLVM compiler, which performs the .ll -> .s step (optionally assembling it, too). lli is an interpreter for the IR. Studying IR is mostly useful for understanding optimization behavior; topic for another day.
The compiler, assembler, and linker are the central components of a toolchain. Other languages, like Rust, usually provide their own toolchain, or just a compiler, reusing the existing C/C++ toolchain. The assembler and linker are language agnostic.
The toolchain also provides various debugging tools, including an interactive debugger, and tools for manipulating object files, such as nm, objdump, objcopy, and ar.
These days, most of this stuff is bundled into a single program, the compiler frontend, which knows how to compiler, assemble, and link, in one invocation. You can ask Clang to spit out .o files with clang -c, and .s files with clang -S.
The UNIX crowd at Bell Labs was very excited about short, terse names. This tradition survives in Go’s somewhat questionable practice of single-letter variables.
Most toolchain program names are cute contractions. cc is “C compiler”; compilers for almost all other languages follow this convention, like rustc, javac, protoc, and scalac; Clang is just clang, but is perfectly ok being called as cc.
as is “assembler”; ld is “loader” (you’ll learn why sooner). ar is “archiver”, nm is “names”. Other names tend to be a bit more sensible.
Some fifty years ago at Bell Labs, someone really wanted to write a program with more than one .s file. To solve this, a program that could “link” symbol references across object files was written: the first linker.
You can take several .o files and use ar (an archaic tar, basically) to create a library, which always have names like libfoo.a (the lib is mandatory). A static library is just a collection of objects, which can be provided on an as-needed basis to the linker.
The “final link” incorporates several .o files and .a files to produce an executable. It does roughly the following:
Parse all the objects and static libraries and put their symbols into a database. Symbols are named addresses of functions and global variables.
Search for all unresolved symbol references in the .o files and match it up with a symbol from the database, recursively doing this for any code in a .a referenced during this process. This forms a sort of dependency graph between sections. This step is called symbol resolution.
Throw out any code that isn’t referenced by the input files by tracing the dependency graph from the entry-point symbol (e.g., _start on Linux). This step is called garbage collection.
Execute the linker script to figure out how to stitch the final binary together. This includes discovering the offsets at which everything will go.
Resolve relocations, “holes” in the binary that require knowing the final runtime address of the section. Relocations are instructions placed in the object file for the linker to execute.
Write out the completed binary.
This process is extremely memory-intensive; it is possible for colossal binaries, especially ones with tons of debug information, to “fail to link” because the linker exhausts the system’s memory.
We only care about step 4; whole books can be written about the previous steps. Thankfully, Ian Lance Taylor, mad linker scientist and author of gold, has written several excellent words on this topic: https://lwn.net/Articles/276782/.
Linkers, fundamentally, consume object files and produce object files; the output is executable, meaning that all relocations have been resolved and an entry-point address (where the OS/bootloader will jump to to start the binary).
It’s useful to be able to peek into object files. The objdump utility is best for this. objdump -x my_object.o will show all headers, telling you what exactly is in it.
At a high level, an object file describes how a program should be loaded into memory. The object is divided into sections, which are named blocks of data. Sections may have file-like permissions, such as allocatable, loadable, readonly, and executable. objdump -h can be used to show the list of sections. Some selected lines of output from objdump on my machine (I’m on a 64-bit machine, but I’ve trimmed leading zeros to make it all fit):
Allocateable (ALLOC) sections must be allocated space by the operating system; if the section is loadable (LOAD), then the operating system must further fill that space with the contents of the section. This process is called loading and is performed by a loader program7. The loader is sometimes called the “dynamic linker”, and is often the same program as the “program linker”; this is why the linker is called ld.
Loading can also be done beforehand using the binary output format. This is useful for tiny microcontrollers that are too primitive to perform any loading. objcopy is useful for this and many other tasks that involve transforming object files.
Some common (POSIX) sections include:
.text, where your code lives8. It’s usually a loadable, readonly, executable section.
.data contains the initial values of global variables. It’s loadable.
.rodata contains constants. It’s loadable and readonly.
.bss is an empty allocatable section9. C specifies that uninitialized globals default to zero; this is a convenient way for avoiding storing a huge block of zeros in the executable!
Debug sections that are not loaded or allocated; these are usually removed for release builds.
After the linker decides which sections from the .o and .a inputs to keep (based on which symbols it decided it needed), it looks to the linker script how to arrange them in the output.
Let’s write our first linker script!
SECTIONS{/* Define an output section ".text". */.text:{/* Pull in all symbols in input sections named .text */*(.text)/* Do the same for sections starting with .text.,
such as .text.foo */*(.text.*)}/* Do the same for ".bss", ".rodata", and ".data". */.bss:{*(.bss);*(.bss.*)}.data:{*(.data);*(.data.*)}.rodata:{*(.rodata);*(.rodata.*)}}
This tells the linker to create a .text section in the output, which contains all sections named .text from all inputs, plus all sections with names like .text.foo. The content of the section is laid out in order: the contents of all .text sections will come before any .text.* sections; I don’t think the linker makes any promises about the ordering between different objects10.
As I mentioned before, parsers for linker script are fussy11: the space in .text : is significant.
Note that the two .text sections are different, and can have different names! The linker generally doesn’t care what a section is named; just its attributes. We could name it code if we wanted to; even the leading period is mere convention. Some object file formats don’t support arbitrary sections; all the sane ones (ELF, COFF, Mach-O) don’t care, but they don’t all spell it the same way; in Mach-O, you call it __text.
Before continuing, I recommend looking at the appendix so that you have a clear path towards being able to run and test your linker scripts!
Naturally, all of this is optional, so you can write foo.o or libbar.a:(.text) or :baz.o(.text .data), where the last one means “not part of a library”. There’s even an EXCLUDE_FILE syntax for filtering by source object, and a INPUT_SECTION_FLAGS syntax for filtering by the presence of format-specific flags.
Do not use any of this. Just write *(.text) and don’t think about it too hard. The * is just a glob for all objects.
Each section has an alignment, which is just the maximum of the alignments of all input sections pulled into it. This is important for ensuring that code and globals are aligned the way the architecture expects them to be. The alignment of a section can be set explicitly with
You can also instruct the linker to toss out sections using the special /DISCARD/ output section, which overrides any decisions made at garbage-collection time. I’ve only ever used this to discard debug information that GCC was really excited about keeping around.
On the other hand, you can use KEEP(*(.text.*)) to ensure no .text sections are discarded by garbage-collection. Unfortunately, this doesn’t let you pull in sections from static libraries that weren’t referenced in the input objects.
Every section has three addresses associated with it. The simplest is the file offset: how far from the start of the file to find the section.
The virtual memory address, or VMA, is where the program expects to find the section at runtime. This is the address that is used by pointers and the program counter.
The load memory address, or LMA, is where the loader (be it a runtime loader or objcpy) must place the code. This is almost always the same as the VMA. Later on, in Using Symbols and LMAs, I’ll explain a place where this is actually useful.
When declaring a new section, the VMA and LMA are both set to the value12 of the location counter, which has the extremely descriptive name .13. This counter is automatically incremented as data is copied from the input
We can explicitly specify the VMA of a section by putting an expression before the colon, and the LMA by putting an expression in the AT(lma) specifier after the colon:
Within SECTIONS, the location counter can be set at any point, even while in the middle of declaring a section (though the linker will probably complain if you do something rude like move it backwards).
The location counter is incremented automatically as sections are added, so it’s rarely necessary to fuss with it directly.
By default, the linker will simply allocate sections starting at address 0. The MEMORY statement can be used to define memory regions for more finely controlling how VMAs and LMAs are allocated without writing them down explicitly.
A classic example of a MEMORY block separates the address space into ROM and RAM:
A region is a block of memory with a name and some attributes. The name is irrelevant beyond the scope of the linker script. The attributes in parens are used to specify what sections could conceivably go in that region. A section is compatible if it has any of the attributes before the !, and none which come after the !. (This filter mini-language isn’t very expressive.)
The attributes are the ones we mentioned earlier: rwxal are readonly, read/write, executable, allocated, and loadable14.
When allocating a section a VMA, the linker will try to pick the best memory region that matches the filter using a heuristic. I don’t really trust the heuristic, but you can instead write > region to put something into a specific region. Thus,
Output sections can hold more than just input sections. Arbitrary data can be placed into sections using the BYTE, SHORT, LONG and QUAD for placing literal 8, 16, 32, and 64-bit unsigned integers into the section:
Numeric literals in linker script may, conveniently, be given the suffixes K or M to specify a kilobyte or megabyte quantity. E.g., 4K is sugar for 4096.
You can fill the unused portions of a section by using the FILL command, which sets the “fill pattern” from that point onward. For example, we can create four kilobytes of 0xaa using FILL and the location counter:
The “fill pattern” is used to fill any unspecified space, such as alignment padding or jumping around with the location counter. We can use multiple FILLs to vary the fill pattern, such as if we wanted half the page to be 0x0a and half 0xa0:
Although the linker needs to resolve all symbols using the input .o and .a files, you can also declare symbols directly in linker script; this is the absolute latest that symbols can be provided. For example:
This will define a new symbol with value 5. If we then wrote extern char my_cool_symbol;, we can access the value placed by the linker. However, note that the value of a symbol is an address! If you did
the processor would be very confused about why you just dereferenced a pointer with address 5. The correct way to extract a linker symbol’s value is to write
It seems a bit silly to take the address of the global and use that as some kind of magic value, but that’s just how it works. The exact same mechanism works in Rust, too:
It’s common practice to lead linker symbols with two underscores, because C declares a surprisingly large class of symbols reserved for the implementation, so normal user code won’t call them. These include names like __text_start, which start with two underscores, and names starting with an underscore and an uppercase letter, like _Atomic.
However, libc and STL headers will totally use the double underscore symbols to make them resistant to tampering by users (which they are entitled to), so beware!
Symbol assignments can even go inside of a section, to capture the location counter’s value between input sections:
Symbol names are not limited to C identifiers, and may contain dashes, periods, dollar signs, and other symbols. They may even be quoted, like "this symbol has spaces", which C will never be able to access as an extern.
There is a mini-language of expressions that symbols can be assigned to. This includes:
Numeric literals like 42, 0xaa, and 4K.
The location counter, ..
Other symbols.
The usual set of C operators, such as arithmetic and bit operations. Xor is curiously missing.
Functions belong to one of two board categories: getters for properties of sections, memory regions, and other linker structures; and arithmetic. Useful functions include:
ADDR, LOADADDR, SIZEOF, and ALIGNOF, which produce the VMA, LMA, size, and alignment of a previously defined section.
ORIGIN and LENGTH, which produce the start address and length of a memory region.
MAX, MIN are obvious; LOG2CEIL computes the base-2 log, rounded up.
ALIGN(expr, align) rounds expr to the next multiple of align. ALIGN(align) is roughly equivalent to ALIGN(., align) with some subtleties around PIC. . = ALIGN(align); will align the location counter to align.
A symbol definition can be wrapped in the PROVIDEO() function to make it “weak”, analogous to the “weak symbol” feature found in Clang. This means that the linker will not use the definition if any input object defines it.
As mentioned before, it is extremely rare for the LMA and VMA to be different. The most common situation where this occurs is when you’re running on a system, like a microcontroller, where memory is partitioned into two pieces: ROM and RAM. The ROM has the executable burned into it, and RAM starts out full of random garbage.
Most of the contents of the linked executable are read-only, so their VMA can be in ROM. However, the .data and .bss sections need to lie in RAM, because they’re writable. For .bss this is easy, because it doesn’t have loadable content. For .data, though, we need to separate the VMA and LMA: the VMA must go in RAM, and the LMA in ROM.
This distinction is important for the code that initializes the RAM: while for .bss all it has to do is zero it, for .data, it has to copy from ROM to RAM! The LMA lets us distinguish the copy source and the copy destination.
This has the important property that it tells the loader (usually objcopy in this case) to use the ROM addresses for actually loading the section to, but to link the code as if it were at a RAM address (which is needed for things like PC-relative loads to work correctly).
Here’s how we’d do it in linker script:
MEMORY{rom:/* ... */ram:/* ... */}SECTIONS{/* .text and .rodata just go straight into the ROM. We don't need
to mutate them ever. */.text:{*(.text)}>rom.rodata:{*(.rodata)}>rom/* .bss doesn't have any "loadable" content, so it goes straight
into RAM. We could include `AT> rom`, but because the sections
have no content, it doesn't matter. */.bss:{*(.bss)}>ram/* As described above, we need to get a RAM VMA but a ROM LMA;
the > and AT> operators achieve this. */.data:{*(.data)}>ramAT>rom}/* The initialization code will need some symbols to know how to
zero the .bss and copy the initial .data values. We can use the
functions from the previous section for this! */bss_start=ADDR(.bss);bss_end=bss_start+SIZEOF(.bss);data_start=ADDR(.data);data_end=data_start+SIZEOF(.data);rom_data_start=LOADADDR(.data);
Although we would normally write the initialization code in assembly (since it’s undefined behavior to execute C before initializing the .bss and .data sections), I’ve written it in C for illustrative purposes:
#include<string.h>externcharbss_start[];externcharbss_end[];externchardata_start[];externchardata_end[];externcharrom_data_start[];voidinit_sections(void){// Zero the .bss.memset(bss_start,0,bss_end-bss_start);// Copy the .data values from ROM to RAM.memcpy(data_start,rom_data_start,data_end-data_start);}
Linker script includes a bunch of other commands that don’t fit into a specific category:
ENTRY() sets the program entry-point, either as a symbol or a raw address. The -e flag can be used to override it. The ld docs assert that there are fallbacks if an entry-point can’t be found, but in my experience you can sometimes get errors here. ENTRY(_start) would use the _start symbol, for example15.
INCLUDE "path/to/file.ld" is #include but for linker script.
INPUT(foo.o) will add foo.o as a linker input, as if it was passed at the commandline. GROUP is similar, but with the semantics of --start-group.
OUTPUT() overrides the usual a.out default output name.
ASSERT() provides static assertions.
EXTERN(sym) causes the linker to behave as if an undefined reference to sym existed in an input object.
(Other commands are documented, but I’ve never needed them in practice.)
It may be useful to look at some real-life linker scripts.
If you wanna see what Clang, Rust, and the like all ultimately use, run ld --verbose. This will print the default linker script for your machine; this is a really intense script that uses basically every feature available in linker script (and, since it’s GNU, is very poorly formatted).
Tock OS, a secure operating system written in Rust, has some pretty solid linker scripts, with lots of comments: https://github.com/tock/tock/blob/master/boards/kernel_layout.ld. I recommend taking a look to see what a “real” but not too wild linker script looks like. There’s a fair bit of toolchain-specific stuff in there, too, that should give you an idea of what to expect.
tl;dr: If you don’t wanna try out any examples, skip this section.
I want you to be able to try out the examples above, but there’s no Godbolt for linker scripts (yet!). Unlike normal code, you can’t just run linker script through a compiler, you’re gonna need some objects to link, too! Let’s set up a very small C project for testing your linker scripts.
I’m assuming you’re on Linux, with x86_64, and using Clang. If you’re on a Mac (even M1), you can probably make ld64 do the right thing, but this is outside of what I’m an expert on.
If you’re on Windows, use WSL. I have no idea how MSCV does linker scripts at all.
First, we want a very simple static library:
intlib_call(constchar*str){// Discard `str`, we just want to take any argument.(void)str;// This will go in `.bss`.staticintcount;returncount++;}
This shows us the address, section type, and name of each symbol; man nm tells us that T means .text and b means .bss. Capital letters mean that the symbol is exported, so the linker can use it to resolve a symbol reference or a relocation. In C/C++, symbols declared static or in an unnamed namespace are “hidden”, and can’t be referenced outside of the object. This is sometimes called internal vs external linkage.
Next, we need a C program that uses the library:
externintlib_call(constchar*str);// We're gonna use a custom entrypoint. This code will never run anyways, we// just care about the linker output.voidrun(void){// This will go in `.data`, because it's initialized to non-zero.staticintdata=5;// The string-constant will go into `.rodata`.data=lib_call("Hello from .rodata!");}
As you might guess, d is just .data. However, U is interesting: it’s an undefined symbol, meaning the linker will need to perform a symbol resolution! In fact, if we ask Clang to link this for us (it just shells out to a linker like ld):
$clang run.o
/usr/bin/ld: /somewhere/crt1.o: in function `_start':
(.text+0x20): undefined reference to `main'
/usr/bin/ld: run.o: in function `run':
run.c:(.text+0xf): undefined reference to `lib_call'
The linker also complains that there’s no main() function, and that some object we didn’t provide called crt1.o wants it. This is the startup code for the C runtime; we can skip linking it with -nostartfiles. This will result in the linker picking an entry point for us.
We can resolve the missing symbol by linking against our library. -lfoo says to search for the library libfoo.a; -L. says to include the current directory for searching for libraries.
At this point, you can use objdump to inspect a.out at your leisure! You’ll notice there are a few other sections, like .eh_frame. Clang adds these by default, but you can throw them out using /DISCARD/.
It’s worth it to run the examples in the post through the linker using this “playground”. You can actually control the sections Clang puts symbols into using the __attribute__((section("blah"))) compiler extension. The Rust equivalent is #[link_section = "blah"].
Blame GCC for this. -Wl feeds arguments through to the linker, and -T is ld’s linker script input flag. Thankfully, rustc is far more sensible here: -Clink-args=-Wl,-T,foo.ld (when GCC/Clang is your linker frontend). ↩
Correction, 2022-09-11. I have really been bothered by not knowing if this is actually true, and have periodically asked around about it. I asked Russ Cox, who was actually at Bell Labs back in the day, and he asked Ken Thompson, who confirms: it’s genuinely .s for source, because it was the only source they had back then.
Completely and utterly unrelated to the objects of object-oriented programming. Best I can tell, the etymology is lost to time. ↩
a.out is also an object file format, like ELF, but toolchains live and die by tradition, so that’s the name given to the linker’s output by default. ↩
Rust does not compile each .rs file into an object, and its “crates” are much larger than the average C++ translation unit. However, the Rust compiler will nonetheless produce many object files for a single crate, precisely for the benefit of this compilation model. ↩
Operating systems are loaded by a bootloader. Bootloaders are themselves loaded by other bootloaders, such as the BIOS. At the bottom of the turtles is the mask ROM, which is a tiny bootloader permanently burned into the device. ↩
No idea on the etymology. This isn’t ASCII text! ↩
Back in the 50s, this stood for “block started by symbol”. ↩
Yes, yes, you can write SORT_BY_NAME(*)(.text) but that’s not really something you ever wind up needing.
(That was sarcasm. It must be stressed that this is not a friendly language.) ↩
This symbol is also available in assembly files. jmp . is an overly-cute idiom for an infinity busy loop. It is even more terse in ARM and RISC-V, where it’s written b . and j ., respectively.
Personally, I prefer the obtuse clarity of loop_forever: j loop_forever. ↩
These are the same characters used to declare a section in assembly. If I wanted to place my code in a section named .crt0 but wanted it to be placed into a readonly, executable memory block, use the the assembler directive .section .crt0, rxal↩
Note that the entry point is almost never a function called main(). In the default configuration of most toolchains, an object called crt0.o is provided as part of the libc, which provides a _start() function that itself calls main(). CRT stands for “C runtime”; thus, crt0.o initializes the C runtime.
This file contains the moral equivalent of the following C code, which varies according to target:
externintmain(intargc,char**argv);noreturnvoid_start(){init_libc();// Initializes global libc state.run_ctors();// Runs all library constructors.intret=main(get_argc(),get_argv());run_dtors();// Runs all library destructors.cleanup_libc();// Deinitializes the libc.exit(ret);// Asks the OS to gracefully destroy the process.}
If you include libc, you will get bizarre errors involving something called “gcc_s”. libgcc (and libgcc_s) is GCC’s compiler runtime library. Where libc exposes high-level operations on the C runtime and utilities for manipulating common objects, libgcc provides even lower-level support, including:
Polyfills for arithmetic operations not available on the target. For example, dividing two 64-bit integers on most 32-bit targets will emit a reference to the a symbol like __udivmoddi4 (they all have utterly incomprehensible names like this one).
Soft-float implementations, i.e., IEEE floats implemented in software for targets without an FPU.
Bits of unwinding (e.g. exceptions and panics) support (the rest is in libunwind).
Miscellaneous runtime support code, such as the code that calls C++ static initializers.
Clang’s version, libcompiler-rt, is ABI-compatible with libgcc and provides various support for profiling, sanitizers, and many, many other things the compiler needs available for compiling code. ↩
Writing unsafe in Rust usually involves manual management of memory. Although, ideally, we’d like to exclusively use references for this, sometimes the constraints they apply are too strong. This post is a guide on those constraints and how to weaken them for correctness.
“Unmanaged” languages, like C++ and Rust, provide pointer types for manipulating memory. These types serve different purposes and provide different guarantees. These guarantees are useful for the optimizer but get in the way of correctness of low-level code. This is especially true in Rust, where these constraints are very tight.
First, let’s survey C++. We have three pointer types: the traditional C pointer T*, C++ references T&, and rvalue references T&&. These generally have pretty weak guarantees.
Pointers provide virtually no guarantees at all: they can be null, point to uninitialized memory, or point to nothing at all! C++ Only requires that they be aligned2. They are little more than an address (until they are dereferenced, of course).
References, on the other hand, are intended to be the “primary” pointer type. A T& cannot be null, is well-aligned, and is intended to only refer to live memory (although it’s not something C++ can really guarantee for lack of a borrow-checker). References are short-lived.
C++ uses non-nullness to its advantage. For example, Clang will absolutely delete code of the form
Because references cannot be null, and dereferencing the null pointer is always UB, the compiler may make this fairly strong assumption.
Rvalue references, T&&, are not meaningfully different from normal references, beyond their role in overload resolution.
Choosing a C++ (primitive) pointer type is well-studied and not the primary purpose of this blog. Rather, we’re interested in how these map to Rust, which has significantly more complicated pointers.
Like C++, Rust has two broad pointer types: *const T and *mut T, the raw pointers, and &T and &mut T, the references.
Rust pointer have even fewer constraints than C++ pointers; they need not even be aligned3! The const/mut specifier is basically irrelevant, but is useful as programmer book-keeping tool. Rust also does not enforce the dreaded strict-aliasing rule4 on its pointers.
On the other hand, Rust references are among the most constrained objects in any language that I know of. A shared reference &'a T, lasting for the lifetime 'a, satisfies:
Non-null, and well-aligned (like in C++).
Points to a valid, initialized T for the duration of 'a.
T is never ever mutated for the duration of the reference: the compiler may fold separate reads into one at will. Stronger still, no &mut T is reachable from any thread while the reference is reachable.
Stronger still are &'a mut T references, sometimes called unique references, because in addition to being well-aligned and pointing to a valid T at all times, no other reachable reference ever aliases it in any thread; this is equivalent to a C T* restrict pointer.
Unlike C++, which has two almost-identical pointer types, Rust’s two pointer types provide either no guarantees or all of them. The following unsafe operations are all UB:
letnull=unsafe{&*ptr::null()};// A reference to u8 need not be sufficiently aligned// for a reference to u32.letunaligned=unsafe{&*(&0u8as*constu8as*constu32)};// More on this type later...letuninit=unsafe{&*MaybeUninit::uninit().as_ptr()};letx=0;unsafe{// Not UB in C++ with const_cast!letp=&x;(pas*consti32as*muti32).write(42);}// Two mutable references live at the same time pointing to// the same memory. This would also be fine in C++!letmuty=0;letp1=unsafe{&*(&mutyas*muti32)};letp2=unsafe{&*(&mutyas*muti32)};
Rust also provides the slice types &[T]5 (of which you get mutable/immutable reference and pointer varieties) and dynamic trait object types &dyn Tr (again, all four basic pointer types are available).
&[T] is a usize6 length plus a pointer to that many Ts. The pointer type of the slice specifies the guarantees on the pointed-to buffer. *mut [T], for example, has no meaningful guarantees, but still contains the length7. Note that the length is part of the pointer value, not the pointee.
&dyn Tr is a trait object. For our purposes, it consists of a pointer to some data plus a pointer to a static vtable. *mut dyn Tr is technically a valid type8. Overall, trait objects aren’t really relevant to this post; they are rarely used this way in unsafe settings.
Suppose we’re building some kind of data structure; in Rust, data structures will need some sprinkling of unsafe, since they will need to shovel around memory directly. Typically this is done using raw pointers, but it is preferable to use the least weakened pointer type to allow the compiler to perform whatever optimizations it can.
There are a number of orthogonal guarantees on &T and &mut T we might want to relax:
Non-nullness.
Well-aligned-ness.
Validity and initialized-ness of the pointee.
Allocated-ness of the pointee (implied by initialized-ness).
We materialize a non-null, well-aligned pointer and reborrow it into a static reference; because there is no data to point to, none of the usual worries about the pointee itself apply. However, the pointer itself must still be non-null and well-aligned; 0x1 is not a valid address for an &[u32; 0], but 0x4 is9.
This also applies to empty slices; in fact, the compiler will happily promote the expression &mut [] to an arbitrary lifetime:
The most well-known manner of weakening is Option<&T>. Rust guarantees that this is ABI-compatible with a C pointer const T*, with Option::<&T>::None being a null pointer on the C side. This “null pointer optimization” applies to any type recursively containing at least one T&.
extern"C"{fnDoSomething(ptr:Option<&mutu32>);}fndo_something(){DoSomething(None);// C will see a `NULL` as the argument.}
The same effect can be achieved for a pointer type using the NonNull<T> standard library type: Option<NonNull<T>> is identical to *mut T. This is most beneficial for types which would otherwise contain a raw pointer:
No matter what, a &T cannot point to uninitialized memory, since the compiler is free to assume it may read such references at any time with no consequences.
Rust doesn’t provide any particularly easy ways to allocate memory without initializing it, too, so this usually isn’t a problem. The MaybeUninit<T> type can be used for safely allocating memory without initializing it, via MaybeUninit::uninit().
This type acts as a sort of “optimization barrier” that prevents the compiler from assuming the pointee is initialized. &MaybeUninit<T> is a pointer to potentially uninitialized but definitely allocated memory. It has the same layout as &T, and Rust provides functions like assume_init_ref() for asserting that a &MaybeUninit<T> is definitely initialized. This assertion is similar in consequence to dereferencing a raw pointer.
&MaybeUninit<T> and &mut MaybeUninit<T> should almost be viewed as pointer types in their own right, since they can be converted to/from &T and &mut T under certain circumstances.
Because T is almost a “subtype” of MaybeUninit<T>, we are entitled10 to “forget” that the referent of a &T is initialized converting it to a &MaybeUninit<T>. This makes sense because &T is covariant11 in &T. However, this is not true of &mut T, since it’s not covariant:
letmutx=0;letuninit:&mutMaybeUninit<i32>=unsafe{transmute(&mutx)};*uninit=MaybeUninit::uninit();// Oops, `x` is now uninit!
These types are useful for talking to C++ without giving up too many guarantees. Option<&MaybeUninit<T>> is an almost perfect model of a const T*, under the assumption that most pointers in C++ are valid most of the time.
MaybeUninit<T> also finds use in working with raw blocks of memory, such as in a Vec-style growable slice:
structSliceVec<'a,T>{// Backing memory. The first `len` elements of it are// known to be initialized, but no more than that.data:&'amut[MaybeUninit<T>],len:usize,}implSliceVec<'a,T>{fnpush(&mutself,x:T){assert!(self.len<data.len());self.data[self.len]=MaybeUninit::new(x);self.len+=1;}}
&mut T can never alias any other pointer, but is also the mechanism by which we perform mutation. It can’t even alias with pointers that Rust can’t see; Rust assumes no one else can touch this memory. Thus, &mut T is not an appropriate analogue for T&.
Like with uninitialized memory, Rust provides a “barrier” wrapper type, UnsafeCell<T>. UnsafeCell<T> is the “interior mutability” primitive, which permits us to mutate through an &UnsafeCell<T> so long as concurrent reads and writes do not occur. We may even convert it to a &mut T when we’re sure we’re holding the only reference.
UnsafeCell<T> forms the basis of the Cell<T>, RefCell<T>, and Mutex<T> types, each of which performs a sort of “dynamic borrow-checking”:
Cell<T> only permits direct loads and stores.
RefCell<T> maintains a counter of references into it, which it uses to dynamically determine if a mutable reference would be unique.
Mutex<T>, which is like RefCell<T> but using concurrency primitives to maintain uniqueness.
Because of this, Rust must treat &UnsafeCell<T> as always aliasing, but because we can mutate through it, it is a much closer analogue to a C++ T&. However, because &T assumes the pointee is never mutated, it cannot coexist with a &UnsafeCell<T> to the same memory, if mutation is performed through it. The following is explicitly UB:
letmutx=0;letp=&x;// This is ok; creating the reference to UnsafeCell does not// immediately trigger UB.letq=unsafe{transmute::<_,&UnsafeCell<i32>>(&x)};// But writing to it does!q.get().write(42);
The Cell<T> type is useful for non-aliasing references to plain-old-data types, which tend to be Copy. It allows us to perform mutation without having to utter unsafe. For example, the correct type for a shared mutable buffer in Rust is &[Cell<u8>], which can be freely memcpy‘d, without worrying about aliasing12.
This is most useful for sharing memory with another language, like C++, which cannot respect Rust’s aliasing rules.
There is no way to disable alignment and validity restrictions: references must always be aligned and have a valid lifetime attached. If these are unachievable, raw pointers are your only option.
We can combine these various “weakenings” to produce aligned, lifetime-bound references to data with different properties. For example:
&UnsafeCell<MaybeUninit<T>> is as close as we can get to a C++ T&.
Option<&UnsafeCell<T>> is a like a raw pointer, but to initialized memory.
Option<&mut MaybeUninit<T>> is like a raw pointer, but with alignment, aliasing, and lifetime requirements.
UnsafeCell<&[T]> permits us to mutate the pointer to the buffer and its length, but not the values it points to themselves.
UnsafeCell<&[UnsafeCell<T>]> lets us mutate both the buffer and its actual pointer/length.
Interestingly, there is no equivalent to a C++ raw pointer: there is no way to create a guaranteed-aligned pointer without a designated lifetime13.
Rust and C++ have many other pointer types, such as smart pointers. However, in both languages, both are built in terms of these basic pointer types. Hopefully this article is a useful reference for anyone writing unsafe abstraction that wishes to avoid using raw pointers when possible.
Except in Go, which synthesizes vtables on the fly. Story for another day. ↩
It is, apparently, a little-known fact that constructing unaligned pointers, but then never dereferencing them, is still UB in C++. C++ could, for example, store information in the lower bits of such a pointer. The in-memory representation of a pointer is actually unspecified! ↩
This is useful when paired with the Rust <*const T>::read_unaligned() function, which can be compiled down to a normal load on architectures that do not have alignment restrictions, like x86_64 and aarch64. ↩
usize is Rust’s machine word type, compare std::uintptr_t. ↩
The length of a *mut [T] can be accessed via the unstable <*mut [T]>::len() method. ↩
It is also not a type I have encountered enough to have much knowledge on. For example, I don’t actually know if the vtable half of a *mut dyn Tr must always be valid or not; I suspect the answer is “no”, but I couldn’t find a citation for this. ↩
Currently, a transmute must be used to perform this operation, but I see no reason way this would permit us to perform an illegal mutation without uttering unsafe a second time. In particular, MaybeUninit::assume_init_read(), which could be used to perform illegal copies, is an unsafe function. ↩
A covariant type Cov<T> is once where, if T is a subtype of U, then Cov<T> is a subtype of Cov<U>. This isn’t particularly noticeable in Rust, where the only subtyping relationships are &'a T subtypes &'b T when 'a outlives 'b, but is nonetheless important for advanced type design. ↩
Cell<T> does not provide synchronization; you still need locks to share it between threads. ↩
I have previously proposed a sort of 'unsafe or '! “lifetime” that is intended to be the lifetime of dangling references (a bit of an oxymoron). This would allow us to express this concept, but I need to flesh out the concept more. ↩
I’ve been told I need to write this idea down – I figure this one’s a good enough excuse to start one of them programming blogs.
TL;DR You can move-constructors the Rust! It requires a few macros but isn’t much more outlandish than the async pinning state of the art. A prototype of this idea is implemented in my moveit crate.
Rust is the best contender for a C++ replacement; this is not even a question at this point1. It’s a high-level language that provides users with appropriate controls over memory, while also being memory safe. Rust accomplishes by codifying C++ norms and customs around ownership and lifetimes into its type system.
Calling into either of these functions from the Rust or C side will recurse infinitely across the FFI boundary. The extern "C" {} item on the Rust side declares C symbols, much like a function prototype in C would; the extern "C" fn is a Rust function with the C calling convention, and the #[no_mangle] annotation ensures that recurse_into_rust is the name that the linker sees for this function. The link works out, we run our program, and the stack overflows. All is well.
But this is C. We want to rewrite all of the world’s C++ in Rust, but unfortunately that’s going to take about a decade, so in the meantime new Rust must be able to call existing C++, and vise-versa. C++ has a much crazier ABI, and while Rust gives us the minimum of passing control to C, libraries like cxx need to provide a bridge on top of this for Rust and C++ to talk to each other.
Unfortunately, the C++ and Rust object models are, a priori, incompatible. In Rust, every object may be “moved” via memcpy, whereas in C++ this only holds for types satisfying std::is_trivially_moveable3. Some types require calling a move constructor, or may not be moveable at all!
Even more alarming, C++ types are permited to take the address of the location where they are being constructed: the this pointer is always accessible, allowing easy creation of self-referential types:
classCyclic{public:Cyclic(){}// Ensure that copy and move construction respect the self-pointer// invariant:Cyclic(constCyclic&){new(this)Cyclic;}// snip: Analogous for other rule-of-five constructors.private:Cyclic*ptr_=this;};
The solution cxx and other FFI strategies take is to box up complex C++ objects across the FFI boundary; a std::unique_ptr<Cyclic> (perhaps reinterpreted as a Box on the Rust side) can be passed around without needing to call move constructors. The heap allocation is a performance regression that scares off potential Rust users, so it’s not a viable solution.
“Move” is a very, very overloaded concept across Rust and C++, and many people have different names for what this means. So that we don’t get confused, we’ll establish some terminology to use throughout the rest of the article.
A destructive move is a Rust-style move, which has the following properties:
It does not create a new object; from the programmer’s perspective, the object has simply changed address.
The move is implemented by a call to memcpy; no user code is run.
The moved-from value becomes inaccessible and its destructor does not run.
A destructive move, in effect, is completely invisible to the user4, and the Rust compiler can emit as many or as few of them as it likes. We will refer to this as a “destructive move”, a “Rust move”, or a “blind, memcpy move”.
A copying move is a C++-style move, which has the following properties:
It creates a new, distinct object at a new memory location.
The move is implemented by calling a user-provided function that initializes the new object.
The moved-from value is still accessible but in an “unspecified but valid state”. Its destructor is run once the current scope ends.
A copying move is just a weird copy operation that mutates the copied-from object. C++ compilers may elide calls to the move constructor in certain situations, but calling it usually requires the programmer to explicitly ask for it. From a Rust perspective, this is as if Clone::clone() took &mut self as an argument. We will refer to this as a “copying move”, a “nondestructive move”, a “C++ move”, or, metonymically, as a “move constructor”.
As part of introducing support for stackless coroutines5 (aka async/await), Rust had to provide some kind of supported for immobile types through pinned pointers.
The Pin type is a wraper around a pointer type, such as Pin<&mut i32> or Pin<Box<ComplexObject>>. Pin provides the following guarantee to unsafe code:
Given p: Pin<P> for P: Deref, and P::Target: !Unpin, the pointee object *p will always be found at that address, and no other object will use that address until *p’s destructor is called.
In a way, Pin<P> is a witness to a sort of critical section: once constructed, that memory is pinned until the destructor runs. The Pin documentation goes into deep detail about when and why this matters, and how unsafe code can take advantage of this guarantee to provide a safe interface.
The key benefit is that unsafe code can create self-references behind the pinned pointer, without worrying about them breaking when a destructive move occurs. C++ deals with this kind of type by allowing move/copy constructors to observe the new object’s address and fix up any self references as necessary.
Our progress so far: C++ types can be immoveable from Rust’s perspective. They need to be pinned in some memory location: either on the heap as a Pin<Box<T>>, or on the stack (somehow; keep reading). Our program is now to reconcile C++ move constructors with this standard library object that explicitly prevents moves. Easy, right;
C++ constructors are a peculiar thing. Unlike Rust’s Foo::new()-style factories, or even constructors in dynamic languages like Java, C++ constructors are unique in that they construct a value in a specific location. This concept is best illustraced by the placement-new operation:
Placement-new is one of those exotic C++ operations you only ever run into deep inside fancy library code. Unlike new, which triggers a trip into the allocator, placement-new simply calls the constructor of your type with this set to the argument in parentheses. This is the “most raw” way you can call a constructor: given a memory location and arguments, construct a new value.
In Rust, a method call foo.bar() is really syntax sugar for Foo::bar(foo). This is not the case in C++; a member function has an altogether different type, but some simple template metaprogramming can flatten it back into a regular old free function:
A Ctor is a constructing closure. A Ctor contains the necessary information for constructing a value of type Output which will live at the location *dest. The Ctor::ctor() function performs in-place construction, making *dest become initialized.
A Ctor is not the constructor itself; rather, it is more like a Future or an Iterator which contain the necessary captured values to perform the operation. A Rust type that is constructed using a Ctor would have functions like this:
It is an unsafe trait, because *dest must be initialized when ctor() returns.
It has an unsafe fn, because, in order to respect the Pin drop guarantees, *dest must either be freshly allocated or have had its destructor run just prior.
Since we are constructing into Pinned memory, the Ctor implementation can use the address of *dest as part of the construction procedure and assume that that pointer will not suddenly dangle because of a move. This recovers our C++ behavior of “this-stability”.
Unfortunately, Ctor is covered in unsafe, and doesn’t even allocate storage for us. Luckily, it’s not too hard to build our own safe std::make_unique:
fnmake_box<C:Ctor>(c:C)->Pin<Box<Ctor::Output>>{unsafe{typeT=Ctor::Output;// First, obtain uninitialized memory on the heap.letuninit=std::alloc::alloc(Layout::new<T>());// Then, pin this memory as a MaybeUninit. This memory// isn't going anywhere, and MaybeUninit's entire purpose// in life is being magicked into existence like this,// so this is safe.letpinned=Pin::new_unchecked(&mut*uninit.cast::<MaybeUninit<T>>());// Now, perform placement-`new`, potentially FFI'ing into// C++.c.ctor(pinned);// Because Ctor guarantees it, `uninit` now points to a// valid `T`. We can safely stick this in a `Box`. However,// the `Box` must be pinned, since we pinned `uninit`// earlier.Pin::new_unchecked(Box::from_raw(uninit.cast::<T>()))}}
Thus, std::make_unique<MyType>() in C++ becomes make_box(MyType::new()) in Rust. Ctor::ctor gives us a bridging point to call the C++ constructor from Rust, in a context where its expectations are respected. For example, we might write the following binding code:
classFoo{Foo(intx);}// Give the constructor an explicit C ABI, using// placement-`new` to perform the "rawest" construction// possible.extern"C"FooCtor(Foo*thiz,intx){new(thiz)Foo(x);}
structFoo{...}implFoo{fnnew(x:i32)->implCtor<Output=Self>{unsafe{// Declare the placement-new bridge.extern"C"{fnFooCtor(this:*mutFoo,x:i32);}// Make a new `Ctor` wrapping a "real" closure.ctor::from_placement_fn(move|dest|{// Call back into C++.FooCtor(dest.as_mut_ptr(),x)})}}}
But… we’re still on the heap, so we seem to have made no progress. We could have just called std::make_unique on the C++ side and shunted it over to Rust. In particular, this is what cxx resorts to for complex types.
Creating pinned pointers directly requires a sprinkling of unsafe. Box::pin() allows us to safely create a Pin<Box<T>>, since we know it will never move, much like the make_box() example above. However, it’s not possible to create a Pin<&mut T> to not-necessarilly-Unpin data as easilly:
letmutdata=42;letptr=&mutdata;letpinned=unsafe{// Reborrow `ptr` to create a pointer with a shorter lifetime.Pin::new_unchecked(&mut*ptr)};// Once `pinned` goes out of scope, we can move out of `*ptr`!letmoved=*ptr;
The unsafe block is necessary because of exactly this situation: &mut T does not own its pointee, and a given mutable reference might not be the “oldest” mutable reference there is. The following is a safe usage of this constructor:
letmutdata=42;// Intentionally shadow `data` so that no longer-lived reference than// the pinned one can be created.letdata=unsafe{Pin::new_unchecked(&mut*data)};
This is such a common pattern in futures code that many futures libraries provide a macro for performing this kind of pinning on behalf of the user, such as tokio::pin!().
With this in hand, we can actually call a constructor on a stack-pinned value:
Unfortunately, we still need to utter a little bit more unsafe, but because of Ctor’s guarantees, this is all perfectly safe; the compiler just can’t guarantee it on its own. The natural thing to do is to wrap it up in a macro much like pin!, which we’ll call emplace!:
This is truly analogous to C++ stack initialization, such as Foo val(args);, although the type of val is Pin<&mut Foo>, whereas in C++ it would merely bee Foo&. This isn’t much of an obstacle, and just means that Foo’s API on the Rust side needs to use Pin<&mut Self> for its methods.
What is the lifetime 'wat? This is just returning a pointer to the current stack frame, which is no good. In C++ (ignoring fussy defails about move semantics), NRVO would kick in and val would be constructed “in the return slot”:
Return value optimization (and the related named return value optimization) allow C++ to elide copies when constructing return values. Instead of constructing val on MakeFoo’s stack and then copying it into the ABI’s return location (be that a register like rax or somewhere in the caller’s stack frame), the value is constructed directly in that location, skipping the copy. Rust itself performs some limited RVO, though its style of move semantics makes this a bit less visible.
Rust does not give us a good way of accessing the return slot directly, for good reason: it need not have an address! Rust returns all types that look roughly like a single integer in a register (on modern ABIs), and registers don’t have addresses. C++ ABIs typically solve this by making types which are “sufficiently complicated” (usually when they are not trivially moveable) get passed on the stack unconditionally6.
Since we can’t get at the return slot, we’ll make our own! We just need to pass the pinned MaybeUninit<T> memory that we would pass into Ctor::ctor as a “fake return slot”:
We can provide another macro, slot!(), which reserves pinned space on the stack much like emplace!() does, but without the construction step. Calling make_foo only requires minimal ceremony and no user-level unsafe.
Move constructors involve rvalue references, which Rust has no meaningful equivalent for, so we’ll attack the easier version: copy constructors.
A copy constructor is C++’s Clone equivalent, but, like all constructors, is allowed to inspect the address of *this. Its sole argument is a const T&, which has a direct Rust analogue: a &T. Let’s write up a trait that captures this operation:
Unlike Ctor, we would implement CopyCtor on the type with the copy constructor, bridging it to C++ as before. We can then define a helper that builds a Ctor for us:
fncopy<T:CopyCtor>(val:&T)->implCtor<Output=T>{unsafe{ctor::from_placement_fn(move|dest|{T::copy_ctor(val,dest)})}}emplace!(lety=copy(x));// Calls the copy constructor.letboxed=make_box(copy(y));// Copy onto the heap.
Box<T> is interesting, because unlike &T, it is possible to move out of a Box<T>, since the compiler treats it somewhat magically. There has long been a desire to introduce a DerefMove trait captures this behavior, but the difficulty is the signature: if deref returns &T, and deref_mut returns &mut T, should deref_move return T? Or something… more exotic? You might not want to dump the value onto the stack; you want *x = *y to not trigger an expensive intermediate copy, when *y: [u8; BIG].
Usually, the “something more exotic” is a &move T or &own T reference that “owns” the pointee, similar to how a T&& in C++ is taken to mean that the caller wishes to perform ownership transfer.
Exotic language features aside, we’d like to be able to implement something like DerefMove for move constructors, since this is the natural analogue of T&&. To move out of storage, we need a smart pointer to provide us with three things:
It must actually be a smart pointer (duh).
It must be possible to destroy the storage without running the destructor of the pointee (in Rust, unlike in C++, destructors do not run on moved-from objects).
It must be the unique owner of the pointee. Formally, if, when p goes out of scope, no thread can access *p, then p is the unique owner.
Box<T> trivially satisfies all three of these: it’s a smart pointer, we can destroy the storage using std::alloc::dealloc, and it satisfies the unique ownership property.
&mut T fails both tests: we don’t know how to destory the storage (this is one of the difficulties with a theoretical &move T) and it is not the unique owner: some &mut T might outlive it.
Interestingly, Arc<T> only fails the unique ownership test, and it can pass it dynamically, if we observe the strong and weak counts to both be 1. This is also true for Rc<T>.
Most importantly, however, is that if Pin<P>, then it is sufficient that P satisfy these conditions. After all, a Pin<Box<P>> uniquely owns its contents, even if they can’t be moved.
It’s useful to introduce some traits that record these requirements:
OuterDrop is simply the “outer storage destruction” operation. Naturally, it is only safe to perform this operation when the pointee’s own destructor has been separately dropped (there are some subtleties around leaking memory here, but in general it’s not a good idea to destroy storage without destroying the pointee, too).
DerefMove7 is the third requirement, which the compiler cannot check (there’s a lot of these, huh?). Any type which implements DerefMove can be moved out of by carefully dismantling the pointer:
fnmove_out_of<P>(mutp:P)->P::TargetwhereP:DerefMove,P::Target:Sized+Unpin,{unsafe{// Copy the pointee out of `p` (all Rust moves are// trivial copies). We need `Unpin` for this to be safe.letval=(&mut*pas*mutP::Target).read();// Destroy `p`'s storage without running the pointee's// destructor.letptr=&mutpas*mutP;// Make sure to suppress the actual "complete" destructor of// `p`.std::mem::forget(p);// Actually destroy the storage.P::outer_drop(ptr);// Return the moved pointee, which will be trivially NRVO'ed.val}}
We can already speak of uninitialized but uniquely-owned stack memory with Slot, but Slot::emplace() returns a (pinned) &mut T, which cannot be DerefMove. This operation actually loses the uniqueness information of Slot, so instead we make emplace() return a StackBox.
A StackBox<'a, T> is like a Box<T> that’s bound to a stack frame, using a Slot<'a, T> as underlying storage. Although it’s just a &mut T on the inside, it augments it with the uniqueness invariant above. In particular, StackBox::drop() is entitled to call the destructor of its pointee in-place.
To the surprise of no one who has read this far, StackBox: DerefMove. The implementation for StackBox::outer_drop() is a no-op, since the calling convention takes care of destroying stack frames.
It makes sense that, since Slot::emplace() returns a Pin<StackBox<T>>, so should emplace!().
(There’s a crate called stackbox that provides similar StackBox/Slot types, although it is implemented slightly differently and does not provide the pinning guarantees we need.)
There’s no such thing as &move Self, so, much like drop(), we have to use a plain ol’ &mut instead. Like Drop, and like CopyCtor, this function is not called directly by users; instead, we provide an adaptor that takes in a MoveCtor and spits out a Ctor.
fnmov<P>(mutptr:P)->implCtor<Output=P::Target>whereP:DerefMove,P::Target:MoveCtor,{unsafe{from_placement_fn(move|dest|{MoveCtor::move_ctor(&mut*ptr,dest);// Destroy `p`'s storage without running the pointee's// destructor.letinner=&mutptras*mutP;mem::forget(ptr);P::outer_drop(inner);})}}
Notice that we no longer require that P::Target: Unpin, since the ptr::read() call from move_out_of() is now gone. Instead, we need to make a specific requirement of MoveCtor that I will explain shortly. However, we can now freely call the move constructor just like any other Ctor:
emplace!(lety=mov(x));// Calls the move constructor.letboxed=make_box(mov(y));// Move onto the heap.
(If you don’t care for language-lawyering, you can skip this part.)
Ok. We need to justify the loss of the P::Target: Unpin bound on mov(), which seems almost like a contradiction: Pin<P> guarantees its pointee won’t be moved, but isn’t the whole point of MoveCtor to perform moves?
At the begining of this article, I called out the difference between destructive Rust move and copying C++ moves. The reason that the above isn’t a contradiction is that the occurences of “move” in that sentence refer to these different senses of “move”.
The specific thing that Pin<P> is protecting unsafe code from is whatever state is behind the pointer being blindly memcpy moved to another location, leaving any self-references in the new location dangling. However, by invoking a C++-style move constructor, the data never “moves” in the Rust sense; it is merely copied in a way that carefully preserves any address-dependent state.
We need to ensure two things:
Implementors of MoveCtor for their own type must ensure that their type does not rely on any pinning guarantees that the move constructor cannot appropriately “fix up”.
No generic code can hold onto a reference to moved-from state, because that way they could witness whatever messed-up post-destruction state the move constructor leaves it in.
The first of these is passed onto the implementor as an unsafe impl requirement. Designing an !Unpin type by hand is difficult, and auto-generated C++ bindings using this model would hopefully inherit move-correctness from the C++ code itself.
The second is more subtle. In the C++ model, the moved-from value is mutated to mark it as “moved from”, which usually just inhibits the destructor. C++ believes all destructors are run for all objects. For example, std::unique_ptr sets the moved-from value to nullptr, so that the destructor can be run at the end of scope and do nothing. Compare with the Rust model, where the compiler inhibits the destructor automatically through the use of drop flags.
In order to support move-constructing both Rust and C++ typed through a uniform interface, move_ctor is a fused destructor/copy operation. In the Rust case, no “destructor” is run, but in the C++ case we are required to run a destructor. Although this changes the semantic ordering of destruction compared to the equivalent C++ program, in practice, no one depends on moved-from objects actually being destroyed (that I know of).
After move_ctor is called, src must be treated as if it had just been destroyed. This means that the storage for src must be disposed of immediately, without running any destructors for the pointed-to value. Thus, no one must be able to witness the messed-up pinned state, which is why mov() requires P: DerefMove.
Thus, no code currently observing Pin<P> invariants in unsafe code will notice anything untoward going on. No destructive moves happen, and no moved-from state is able to hang around.
I’m pretty confident this argument is correct, but I’d appreciate some confirmation. In particular, someone involved in the UCG WG or the Async WG will have to point out if there are any holes.
In the end, we don’t just have a move constructors story, but a story for all kinds of construction, C++-style. Not only that, but we have almost natural syntax:
emplace!{letx=Foo::new();lety=ctor::mov(x);letz=ctor::copy(y);}// The make_box() example above can be added to `Box` through// an extension trait.letfoo=Box::emplace(Foo::new());
As far as I can tell, having some kind of “magic” around stack emplacement is unavoidable; this is a place where the language is unlikely to give us enough flexibility any time soon, though this concept of constructors is the first step towards such a thing.
We can call into C++ from Rust without any heap allocations at all (though maybe wasting an instruction or two shunting pointers across registers for our not-RVO):
/// Generated Rust type for bridging to C++, like you might get from `cxx`.structFoo{...}implFoo{pubfnnew(x:i32)->implCtor{...}pubfnset_x(self:Pin<&mutSelf>,x:i32){...}}fnmake_foo(out:Slot<Foo>)->Pin<StackBox<Foo>>{letmutfoo=out.emplace(Foo::new(42));foo.as_mut().set_x(5);foo}
This is only the beginning: much work needs to be done in type design to have a good story for bridging move-only types from C++ to Rust, preferably automatically. Ctors are merely the theoretical foundation for building a more ergonomic FFI; usage patterns will likely determine where to go from here.
Open questions such as “how to containers” remain. Much like C++03’s std::auto_ptr, we have no hope of putting a StackBox<T> into a Vec<T>, and we’ll need to design a Vec variant that knows to call move constructors when resizing and copy constructors when cloning. There’s also no support for custom move/copy assignment beyond the trivial new (this) auto(that) pattern, and it’s unclear whether that’s useful. Do we want to port a constructor-friendly HashMap (Rust’s swisstable implementation)? Do we want to come up with macros that make dealing with Slot out-params less cumbersome?
Personally, I’m excited. This feels like a real breakthrough in one of the biggest questions for true Rust/C++ interop, and I’d like to see what people wind up building on top of it.
This isn’t exactly a universal opinion glances at Swift but it is if you write kernel code like me. ↩
You can’t just have rustc consume a .h and spit out bindings, like e.g. Go can, but it’s better than the disaster that is JNI. ↩
Some WG21 folks have tried to introduce a weaker type-trait, std::is_trivially_relocatable, which is a weakening of trivally moveable that permits a Rust-style destructive move. The libc++ implementation of most STL types, like std::unique_ptr, admit this trait. ↩
A lot of unsafe Rust code assumes this is the only kind of move. For example, mem::swap() is implemented using memcpy. This is unlike the situation in C++, where types will often provide custom std::swap() implementations that preserve type invariants. ↩
Because Future objects collapse their stack state into themselves when yielding, they may have pointers into themselves (as a stack typically does). Thus, Futures need to be guaranteed to never move once they begin executing, since Rust has no move constructors and no way to fix up the self-pointers. ↩
Among other things, this means that std::unique_ptrs are passed on the stack, not in a register, which is very wasteful! Rust’s Box does not have this issue. ↩
Rust has attempted to add something like DerefMove many times. What’s described in this post is nowhere near as powerful as a “real” DerefMove would be, since such a thing would also allow moving into a memory location. ↩